빅데이터란 ?
빅데이터에 대한 단일 정의는 없습니다. 공급 업체, 실무자 및 비지니스 전문가는 이를 다르게 사용합니다.
사전적 의미 : 기존의 데이터 처리 소프트웨어에 비해 너무 복잡한 데이터 세트의 애플리케이션
빅데이터를 설명하는 3가지
- 양 - 데이터의 크기
- 속도 - 데이터를 생성하고 처리 할 수 있는 속도
- 다양성 - 서로 다른 데이터 소스 및 형식
빅데이터 컨셉
- 클러스터 컴퓨팅 - 여러 시스템의 리소스를 풀링하여 작업을 완료합니다.
- 병렬 컴퓨팅 - 많은 계산이 동시에 수행되는 계산 유형
- 분산 컴퓨팅 - 병렬로 작업을 실행하는 노드 또는 네트워크 컴퓨터
- 배치 프로세싱 - 데이터를 더 작은 조각으로 나누고 각 조각을 개별 컴퓨터에서 실행
- 실시간 처리 - 정보를 처리하고 즉시 준비
유명한 프레임 워크
- Hadoop / MapReduce - 확장 가능하고 장애 내성이 있는 Java 기반 프레임워크
- 배치 데이터 프로세싱
- 오픈 소스
- Spark - 클러스터 된 컴퓨터에서 빅 데이터를 저장하고 처리하기 위한 프레임 워크
- 오픈 소스
- 병렬 컴퓨팅
- 배치 및 실시간 데이터 처리에 적합
Spark framework
- 여러 컴퓨터에 데이터와 계산을 배포합니다. ( 클러스터 컴퓨팅 )
- Spark는 메모리에서 대부분의 게산을 실행하여 제공
- 메모리에서 애플리케이션을 최대 100배 더 빠르게 실행하고 디스크에서할 때 10배 더 빠르게 실행
- Scala 언어로 작성되었지만, Java, Python, R, SQL도 지원
Spark 구성

Spark Core가 구축되고 나머지 Spark 라이브러리는 그 위에 구축됩니다.
- Spark SQL - Python, Java, Scala에서 구조적 및 반 구조적 데이터를 처리하기 위한 라이브러리
- MLlib ( 머신러닝 ) - 기계학습 알고리즘 라이브러리
- GraphX - 그래프 조작 및 병렬 그래프 계산 수행을 위한 알고리즘 및 도구 모음
- Spark Streaming - 실시간 데이터를 위한 확장 가능하고 처리량이 많은 라이브러리
Spark의 모드
- Local mode - 랩탑과 같은 단일 컴퓨터에서 Spark를 실행할 수 있는 모드
- 테스트, 디버깅 및 데모 목적으로 매우 편함
- Cluster mode
- 주로 프로덕션에서 사용
Local 모드에서 Cluster 모드로 전환하는 것이 기본적인 워크 플로
- 로컬모드에서 클러스터 모드로 전환하는 동안 코드를 변경할 필요 없음
PySpark
- Spark는 Scala로 작성되었습니다.
- PySpark는 파이썬에서 Spark를 지원합니다.
- 최신 버전의 PySpark는 Scala와 유사한 계산 기능을 제공합니다.
- PySpark의 API는 Pandas & Sklearn 패키지와 유사합니다.
Spark Shell
- 임시 데이터 분석을 가능하게하는 대화식 쉘 제공
- Spark 쉘은 클러스터에서 작업을 실행하기 전에 대화형 프로토 타이핑에 유용
- 다른 쉘과 달리 Spark 쉘을 사용하면 디스크에 배포 된 데이터와 상호 작용할 수 있습니다.
- 시스템의 여러 메모리가 있을 때, Spark는 이를 자동으로 배포합니다.
- spark-shell ( Scala ), PySpark ( Python ), SparkR ( R ) - 세가지 프로그래밍 언어로 쉘을 제공
PySpark Shell
- Python에서 Spark의 대화 형 응용 프로그래밍을 개발하기 위한 Python 기반 명령 줄 도구
- 클러스터 연결을 지원하도록 기능이 향상되었습니다.
SparkContext
- Spark기능과 상호 작용하기 위한 진입 점 (entry point)
- entry point : 운영 체제에서 제공된 프로그램으로 제어가 전송되는 지점 (집에 들어가는 키)
- PySpark 쉘의 SparkContext, sc 라는 변수로 엑세스
SparkContext
- Version - 현재 실행중인 스파크 버전을 보여줍니다.
sc.version
- Python Version - 현재 사용중인 Python 버전을 보여줍니다.
sc.pythonVer
- Master - 로컬 모드에서 실행할 로컬주소 Or 클러스터의 URL
sc.master
데이터 로드
parallelize()메소드
rdd = sc.parallelize([1,2,3,4,5])
1에서 5까지 숫자를 보유한 병렬 컬렉션을 만드는 방법
textFile()메소드
rdd2 = sc.textFile("test.txt")
텍스트 파일을 로드하는 방법
익명함수 - 파이썬
- 파이썬은, lambda 구문을 통해 런타임에 이름이 바인딩되지 않는 함수를 생성 가능합니다.
- lambda 함수는,
map(),filter()등 다른 함수와 잘 통합되어 있어서, 매우 강력합니다. - def와 마찬가지로, lambda는 프로그램에서 나중에 호출할 함수를 만듭니다. ( 이름에 할당하는 대신 함수를 반환 - 익명함수로 알려진 이유 )
- 함수 정의를 인라인하거나, 코드 실행을 연기하는 방법으로 사용
Lambda
lambda arguments: expression
lambda의 형식은 위와 같습니다.
double = lambda x: x * 2
print(double(3))
def vs lambda
def cube(x):
return x ** 3
g = lambda x: x**3
labmda 정의에 의해 lambda는 return문과 항상 반환되는 표현식을 포함합니다.
lambda - map()
map()함수는 목록의 모든 항목과 새로운 항목으로 호출됩니다.- 각 항목에 대해 해당 기능에서 리턴 한 항목이 포함 된 list가 리턴됩니다.
map(function, list)
items = [1, 2, 3, 4]
list(map(lambda x: x + 2, items))
map함수를 사용하는 예제는 위와 같습니다.
lambda - filter()
filter()함수는 함수와 리스트를 인수로 받습니다.- 함수가 True로 평가되는 항목이 포함 된 목록과 새 목록이 반환됩니다.
filter(function, list)
items = [1, 2, 3, 4]
list(filter(lambda x: (x%2 != 0), items))
RDD
- Resilient Distrubuted Datasets ( 탄력적 분산 데이터 세트 )
- 클러스터에 분산 된 데이터 모음
- RDD는 PySpark의 기본 및 백본 데이터 유형
- Spark가 데이터 처리를 시작하면 데이터를 파티션으로 나누고, 각 노드가 데이터 조각을 포함하여 클러스터 노드에 데이터를 분배
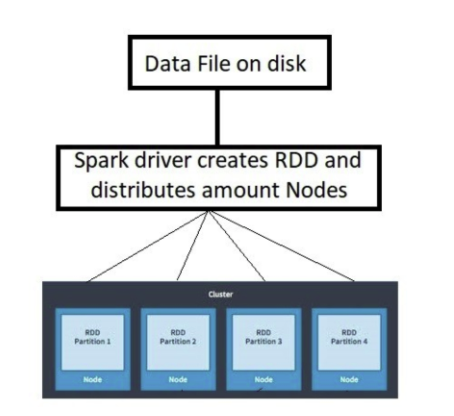
RDD 속성
- Resilient ( 복원력 ) - 장애를 견뎌내거나 누락되거나 손상된 파티션을 다시 계산할 수 있는 기능
- Distributed ( 분산 ) - 효율적인 계산을 위해 클러스터의 여러 노드에 걸쳐 작업을 확장합니다.
- Datasets - 파티션 된 데이터의 모음 인 데이터 세트 ( 배열, 테이블, 튜플, 객체 )
RDD 작성 방법
- RDD를 생성하는 가장 간단한 방법은 기존 객체 컬렉션을 취하는 방법 ( 목록, 배열, 집합을 SparkContext의 parellelize 메소드에 전달 )
- RDD를 작성하는 것보다 일반적인 방법은 HDFS에 저장된 파일 또는 외부 데이터 세트에서 데이터를 로드하는 것
- Files in HDFS
- Objects in Amazon S3 bucket
- lines in a text file
- 기존 RDD에서 RDD를 만드는 방법
Parallelized collection
- RDD는 SparkContext의 parallelize 메소드를 사용하여 목록 또는 세트에서 작성됩니다.
numRDD = sc.parallelize([1,2,3,4])
첫번째 - numRDD라는 RDD는 숫자 1,2,3,4를 포함하는 리스트 목록에서 작성됩니다.
helloRDD = sc.parallelize("Hello world")
두번째 - helloRDD라는 RDD는 “Hello world”라는 문자열에서 작성됩니다.
type(helloRDD)
[Output]
<class 'pyspark.rdd.PipelinedRDD'>
Python의 type 메소드를 사용하여 생성 된 객체가 RDD인지 확인 할 수 있습니다.
외부 데이터 세트
- 외부 데이터 세트의 RDD는 PySpark에서 가장 일반적입니다.
textFile()메소드를 사용하여 작성
fileRDD = sc.textFile("README.md")
PySpark 파티셔닝
- 파티션을 처리하는 방법을 이해하여 병렬 처리를 제어 할 수 있습니다.
- Spark의 파티션은 큰 데이터 세트의 분할이며, 각 부분은 클러스터의 여러 위치에 저장됩니다.
- 기본적으로 Spark는 몇가지 요소를 기반으로 RDD를 만들 때 데이터를 분할합니다.
numRDD = sc.parallelize(range(10), minPartitions = 6)
minPartitions 라는 인자를 통해 최소 파티션 갯수를 정의할 수 있습니다.
fileRDD = sc.textFile("README.md", minPartitions = 6)
- RDD의 파티션 수는 항상
getNumPartitions()함수를 통해 알 수 있습니다.
PySpark operations
- Pyspark에서 두가지 유형의 작업을 지원합니다.
- Transformations - 새 RDD를 리턴하는 RDD조작
- Actions - 일부 계싼을 수행하는 조작
RDD Transformations
- 내결함성에서 RDD를 지원하고 리소스 사용을 최적화하는 기능은 지연 평가 ( Lazy evaluation )
- Lazy evaluation
- Spark는 RDD 및 실행에서 수행하는 모든 작업에서 그래프를 만듭니다.

그림과 같이 RDD에 대해 조치가 수행 될 때만 그래프가 시작됩니다. 이를 Spark의 Lzy evaluation 이라고 합니다.
map() Transformation
- map 변환은 함수를 받아서 RDD의 각 요소에 적용합니다.
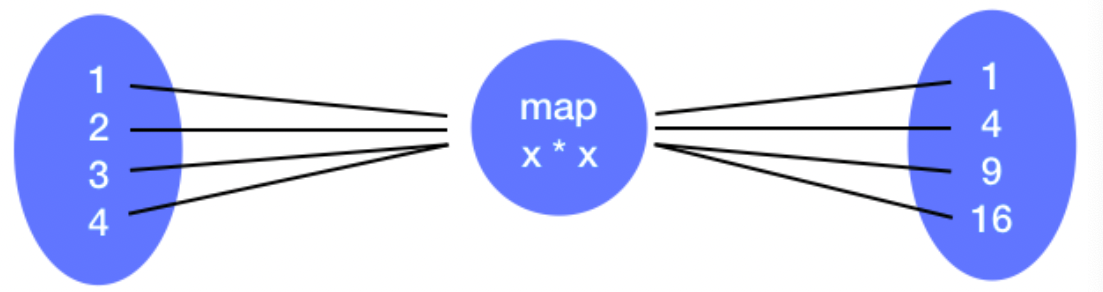
1,2,3,4의 요소를 가진 RDD로 부터, map 변환은 함수를 받아서 RDD의 각 요소에 적용합니다.
RDD = sc.parallelize([1,2,3,4])
RDD_map = RDD.map(lambda x: x * x)
filter() Transformation
- Filter 변환은 함수를 받아서 조건을 통과하는 요소 만있는 RDD를 반환합니다.
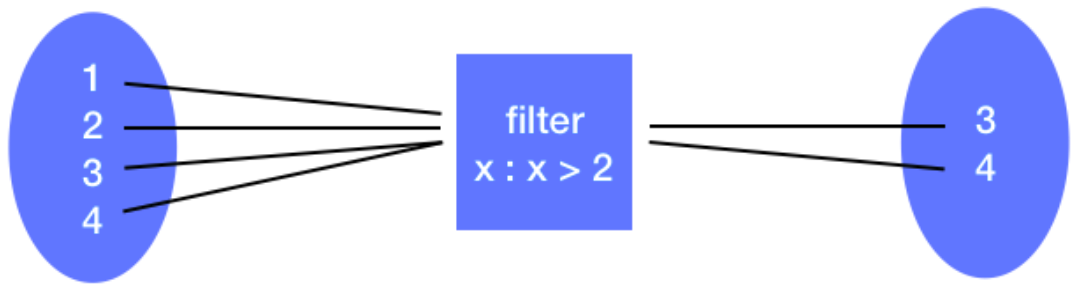
RDD = sc.parallelize([1,2,3,4])
RDD_filter = RDD.filter(lambda x: x > 2)
flatMap() Transformation
- RDD의 각 요소에 대해 여러 값을 리턴한다는 점을 제외하고 map 변환과 유사
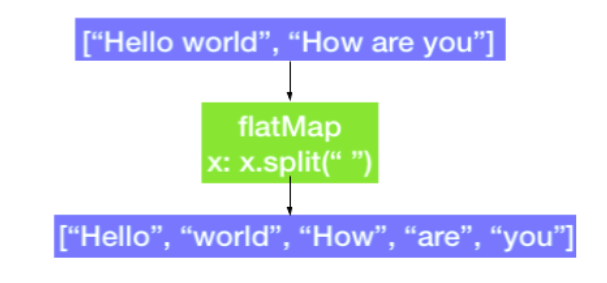
위의 사진과 같이 문자열을 split하거나 할 때 자주 사용합니다.
RDD = sc.parallelize(["hello world", "how are you"])
RDD_flatmap = RDD.flatMap(lambda x: x.split(" "))
union() Transformation
- Union 변환은 한 RDD와 다른 RDD의 통합을 리턴합니다.
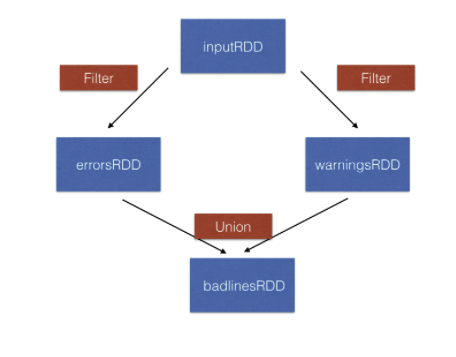
위의 그림을 보면, inputRDD를 필터링하고, 두개의 RDD인 errorsRDD, warningsRDD를 만듭니다.
이후, 두개의 RDD를 union 변환을 이용해서 합칩니다.
inputRDD = sc.textFIle("logs.txt")
errorRDD = inputRDD.filter(lambda x: "error" in x.split())
warningsRDD = inputRDD.filter(lambda x: "warnings" in x.split())
combinedRDD = errorRDD.union(warningsRDD)
RDD Actions
- Action은 RDD에 적용되어 계산을 실행 한 후 값을 반환하는 작업입니다.
- Basic RDD Actions
- collect()
- take(N)
- first()
- count()
collect() and take()
- collect() 는 RDD에서 전체 요소 목록을 리턴합니다.
- take(N) 은 RDD에서 ‘N’개의 요소를 인쇄합니다.
RDD_map.collect()
RDD_map.take(2)
first() and count()
- first() 는 RDD의 첫번재 요소를 리턴합니다.
RDD_map.first()
- count() 는 RDD의 총 요소 수를 리턴하는데 사용됩니다.
키 / 값 RDD
- 실제 데이터 세트의 대부분은 일반적으로 키 / 값 쌍을 이룹니다. ex) 팀 - 플레이어
- 데이터 집합의 일반적인 패턴은 각 행이 하나 이상의 값에 매핑되는 키입니다.
- 이러한 데이터를 처리하기 위해, Pyspark는 pair RDD라는 특수 데이터 구조를 제공합니다.
- pair RDD에서 키는 식별자를 나타내고, 값은 데이터를 나타냅니다.
pair RDDs 만들기
- 키-값 튜플 or 일반 RDD에서 만들기
- key-value pair 형태의 데이터에서 만들기
my_tuple = [('Sam', 23), ('Mary', 34), ('Peter', 25)]
pairRDD_tuple = sc.parallelize(my_tuple)
my_list = ['Sam 23', 'Mary 34', 'Peter 25']
regularRDD = sc.parallelize(my_list)
pairRDD_RDD = regularRDD.map(lambda s: (s.split(' ')[0], s.split(' ')[1]))
- Paired RDD Transformations
- reduceByKey(func) - 같은 키를 가진 값으로 결합
- groupByKey() - 같은 키를 가진 그룹으로 묶기
- sortByKey() - 키를 기준으로 정렬
- Join() - 2개의 RDD를 그들의 키를 기반으로 합침
reduceByKey()
- 함수를 사용하여 값을 동일한 키와 결합하는 변환
- 데이터 세트의 각 키마다 하나씩 여러 병렬 작업을 실행
regularRDD = sc.parallelize([("Messi", 23), ("Ronaldo", 34), ("Neymar", 22), ("Messi", 24)])
pairRDD_reducebykey = regularRDD.reduceByKey(lambda x,y : x + y)
pairRDD_reducebykey.collect()
sortByKey()
- 키에 정의 된 순서가 있는 한 쌍의 RDD를 정렬
- SortByKey 변환은 키를 기준으로 오름차순 또는 내림차순으로 정렬된 RDD를 리턴
pairRDD_reducebykey_rev = pairRDD_reducebykey.map(lambda x: (x[1], x[0]))
pairRDD_reducebykey_rev.sortByKey(ascending=False).collect()
groupByKey()
- 키별로 데이터를 그룹화 합니다.
- 데이터가 원하는 형식으로 입력되면, groupByKey 변환은 pair RDD에서 동일한 키를 가진 모든 값을 그룹화합니다.
airports = [("US","JFK"), ("UK", "LHR"), ("FR", "CDG"), ("US", "SFO")]
regularRDD = sc.parallelize(airports)
pairRDD_group = regularRDD.groupByKey().collect()
for cont, air in pairRDD_group:
print(cont, list(air))
Join
- 키를 기준으로 두 쌍의 RDD를 결합합니다.
RDD1 = sc.parallelize([("Messi", 34), ("Ronaldo", 32), ("Neymar", 24)])
RDD2 = sc.parallelize([("Ronaldo", 80), ("Neymar", 120), ("Messi", 100)])
RDD1.join(RDD2).collect()
[output]
[('Neymar',(24,120)), ('Ronaldo', (32,80)), ('Messi', (34,100))]
reduce(func)
- reduce(func)는 두 요소에서 작동하는 함수로, RDD에 함수를 적용한 결과로, 동일한 유형의 새 요소를 리턴합니다.
- 함수는 병렬로 올바르게 계산 될 수 있도록 commutative and associative 해야합니다.
x = [1,3,4,6]
RDD = sc.parallelize(x)
RDD.reduce(lambda x, y: x+y)
[output]
14
saveAsTextFile()
- 대부분의 경우 데이터의 크기가 커서 RDD에 대한 collect() 를 실행하지 않는 것이 좋습니다.
- 이런 경우, HDFS or S3에 데이터를 쓰는 것이 일반적입니다.
saveAsTextFile()은 RDD를 특정 디렉토리에 텍스트 파일로 저장하는데 사용 할 수 있습니다.- 기본적으로,
saveAsTextFile()은 각 파티션과 함께 RDD를 디렉토리 내 별도의 파일로 저장합니다.
RDD.saveAsTextFile("tempFile")
coalesce()를 사용해서 RDD를 single text file로 저장 할 수 있습니다.
RDD.coalesce(1).saveAsTextFile("tempFile")
위는 디렉토리 내에서 RDD를 단일 파일로 저장하는 예시입니다.
pair RDD 함수
- pair RDD변환에는 pair RDD에 사용할 수 있는 RDD 동작들이 있습니다.
- 그러나 pair RDD는 PySpark의 일부 추가 작업을 수행합니다.
countByKey()collectAsMap()
countByKey()
- (Key, Value) 형태의 RDD에서만 사용할 수 있습니다.
- countByKey 작업을 사용하면, 각 키의 요소 수를 계산할 수 있습니다.
rdd = sc.parallelize([("a",1), ("b",1), ("a",1)])
for kee, val in rdd.countByKey().items():
print(kee, val)
[output]
('a', 2)
('b', 1)
countByKey는 크기가 메모리에 들어가기에 충분히 작은 데이터 세트에만 사용해야 합니다.
collectAsMap()
- RDD의 key-value pair를 딕셔너리로 리턴합니다.
sc.parallelize([(1,2), (3,4)]).collectAsMap()
[output]
{1:2, 3:4}
Pyspark DataFrame
- PySpark SQL은 구조화 된 데이터를 위한 라이브러리입니다.
- PySpark RDD API와 달리, PySpark SQL은 더 많은 것을 제공합니다.
- Pyspark SQL은 DataFrame라는 프로그래밍 추상화를 제공합니다.
- DataFrame은 명명 된 열이있는 변경 불가능한 분산 데이터 콜렉션 입니다.
- DataFrame은 다음과 같은 대규모 구조화 된 데이터 수집을 처리하도록 설계되었습니다. ( RDS, JSON 등 )
- DataFrame API는 Python, R, Scala, Java 를 지원합니다.
- DataFrame은 SQL 쿼리( SELECT * from table ) or 표현식 함수( df.select() )를 지원합니다.
DataFrame 진입점 ( Entry point )
- SparkSession 은 Spark DataFrame의 진입점을 제공합니다.
- SparkSession은 RDD에서 SparkContext가 수행했던 작업을 수행합니다.
- SparkSession은 데이터프레임을 만들고, 등록 할 수 있습니다.
- SparkSession 또한 PySpark 쉘이 가능합니다.
DataFrame 만들기
- 기존 RDD에서 createDataFrame 메소드를 사용하여 만들기
- read 메소드를 사용해서, CSV, JSON, TXT와 같은 파일 데이터 소스로 부터 만들기
- 스키마를 정의해야 합니다.
- DataFrame의 데이터 구조이며, Spark가 데이터에 대한 쿼리를 보다 효율적으로 최적화하는데 도움이 됩니다.
- 열 이름, 데이터 타입, 해당 열에 null or 빈 값 허용 여부 등
RDD -> DataFrame
- RDD에서 DataFrame을 만들려면, RDD와 스키마를 createDataFrame 메소드에 전달해야 합니다.
iphones_RDD = sc.parallelize([
("XS", 2018, 5.65, 2.79, 6.24),
("XR", 2018, 5.94, 2.98, 6.84),
("X10", 2017, 5.65, 2.79, 6.13),
("8Plus", 2017, 6.23, 3.07, 7.12)
])
names = ['Model', 'Year', 'Height', 'Width', 'Weight']
iphones_df = spark.createDataFrame(iphones_RDD, schema=names)
type(iphones_df)
[output]
pyspark.sql.dataframe.DataFrame
위와 같이, 스키마를 지정해서 인자로 넘겨줘야 합니다.
만약 스키마가 없을 경우, 데이터에서 스키마를 유추하려고 시도합니다.
CSV/JSON/TXT
- CSV / JSON / TXT 를 통해 DataFrame을 만들 경우, spark.read 속성을 사용합니다.
df_csv = spark.read.csv("people.csv", header=True, inferSchema=True)
df_json = spark.read.json("people.json", header=True, inferSchema=True)
df_txt = spark.read.txt("people.txt", header=True, inferSchema=True)
파일 유형에 관계없이, 파일 경로와, header, inferSchema 두개의 매개 변수가 필요합니다.
header - 첫 번째 행을 열 이름으로 취급 ( True / False )
inferSchema - DataFrame 판독기에 schema를 추측하도록 지시 ( True / False )
DataFrame operators
- RDD와 동일하게, DataFrame에 작업도 두가지로 나눠집니다.
- Transformations
- Actions
- DataFrame은 집계를 필터링, 그룹화 또는 계산하기 위한 PySpark SQL을 사용할 수 있습니다.
select() and show()
- select 변환은 DataFrame에서 하나 이상의 열을 추출하는데 사용 ( select 작업 안에 열 이름을 전달 )
df_id_age = test.select('Age')
- DataFrame에서 행을 인쇄하려면 Action을 실행해야 합니다.
show()는 기본적으로 20행을 인쇄하는 액션입니다.
df_id_age.show(3)
위와 같이, N값을 주면 처음부터 N행 까지 인쇄합니다.
filter() and show()
filter()는 select과 달리, 지정된 조건을 통과하는 행만 선택합니다.
new_df_age21 = new_df.filter(new_df.Age > 21)
new_df_age21.show(3)
groupby() and count()
groupby()변환은, DataFrame을 그룹화하여 집계를 실행할 수 있습니다.
test_df_age_group = test.df.groupby('Age')
test_df_age_group.count().show(3)
orderby()
orderby()변환은, 주어진 열을 기준으로 정렬 된 DataFrame을 반환합니다.
test_df_age_group.count().orderBy('Age').show(3)
dropDuplicates()
dropDuplicates()변환은, 중복 행이 제거 된 새 DataFrame을 반환합니다.
test_df_no_dup = test_df.select("User_ID", "Gender", "Age").dropDuplicates()
test_df_no_dup.count()
withColumnRenamed()
withColumnRenamed()- 기존 열의 이름을 바꾸어 새 DataFrame을 반환합니다.
test_df_sex = test_df.withColumnRenamed('Gender', 'Sex')
test_df_sex.show(3)
printSchema()
printSchema()는 열 유형을 확인하기 위해 사용합니다.
test_df.printSchema()
columns actions
columns액션은, 데이터프레임의 열 이름을 문자열 배열로 반환합니다.
test_df.columns
describe() actions
describe()액션은, DataFrame에서 숫자 열의 요약 통계를 계산하는데 사용합니다.
test_df.describe().show()
describe()에 인자로 열 이름을 입력하지 않으면, DataFrame에 있는 모든 숫자 열에 대한 통계를 출력합니다.
DataFrame API vs SQL queries
- Pyspark는 DataFrame API, SQL queries 두가지 방법으로 조작할 수 있습니다.
- DataFrame API
- 프로그래밍 인터페이스를 제공합니다.
- 기본적으로 데이터 상호 작용하기 위한, DSL ( Domain-Specific Language )
- 프로그래밍 방식으로 훨씬 쉽게 구성할 수 있습니다.
- SQL queries
- 훨씬 간결하고 이해하기 쉽습니다.
- 이식성이 있으며, 지원되는 모든 언어를 수정하지 않고 사용할 수 있습니다.
SQL Queries
- SparkSession은 SQL 쿼리를 실행하는 데 사용할 수 있는 SQL이라는 메서드를 제공합니다.
sql()메소드는 SQL 문을 인수로 사용합니다.- sql쿼리는 DataFrame에 대해 직접 실행할 수 없습니다. - 기존 DataFrame에 대해 SQL 쿼리를 발행하기 위해 임시테이블을 작성하는
createOrReplaceTempView함수를 사용합니다
df.createOrReplaceTempView("table1")
df2 = spark.sql("SELECT filed1, field2 from table1")
df2.collect()
위와 같이 임시 테이블을 생성 후, SQL 쿼리를 사용합니다.
결과 출력에 경우, DataFrame이므로, collect, first, show 등의 액션으로 작업을 실행 합니다.
SQL query 를 이용한 집계
test_df.createOrReplaceTempView("test_table")
query = '''
SELECT Age, max(Purchase)
FROM test_table
GROUP BY Age
'''
spark.sql(query).show(5)
SQL 쿼리를 통해 원하는 데이터를 집계 추출한다음, spark.sql을 통해 로드합니다.
Visualization
- 데이터 시각화는 그래프 또는 차트 형식으로 데이터를 나타내는 방법입니다.
- EDA ( 탐색적 데이터 분석 )의 중요한 구성 요소로 간주됩니다.
- matplotlib, Seaborn, Bokeh 등과 같은 Python의 시각화를 지원하는 여러 오픈 소스 도구가 있으나, PySpark DataFrame에서 직접 사용할 수 없습니다.
- 시각화를 하는 세가지 방법
- pyspark_dist_explore library
- toPanda()
- HandySpark library
Pyspark_dist_explore
- Pyspark DataFrames의 데이터에 대한 빠른 통찰력을 얻는 플로팅 라이브러리입니다.
- matplotlib 그래프를 생성하기 위한 3가지 기능
hist()distplot()pandas_histogram()
test_df = spark.read_csv("test.csv", header=True, inferSchema=True)
test_df_age = test_df.select('Age')
hist(test_df_age, bins=20, color="red")
toPandas()
- PySpark DataFrame을 Pandas DataFrame으로 변환하는 방법입니다.
- 변환 후, matplotlib or seaborn과 같은 플로팅 도구를 사용하여 DataFrame차트를 쉽게 만들 수 있습니다.
test_df = spark.read.csv("test.csv", header=True, inferSchema=True)
test_df_sample_pandas = test_df.toPandas()
test_df_sample_pandas.hist('Age')
Pandas DataFrame vs Spark DataFrame
- Pandas DataFrame
- in-memory
- single server 기반 구조
- 적용하면 즉시 결과를 얻습니다.
- mutable
- PySpark DataFrame보다 더 많은 작업을 지원
- Spark DataFrame
- Parallel
- Lazy evaluation
- Immutable
HandySpark
- HandySpark는 PySpark 사용자 경험을 향상 시키도록 설계 - 시각화 기능을 포함한 탐색적 데이터 분석
test_df = spark.read.csv("test.csv", header=True, inferSchema=True)
hdf = test_df.toHandy()
hdf.cols["Age"].hist()
PySpark MLlib
- 머신러닝 - 데이터에서 배울 수 있는 알고리즘의 구성 및 연구를 탐구합니다.
- PySpark MLlib - 기계학습 라이브러리입니다. ( 실제 머신러닝을 확장 가능하고 쉽게 만드는 것이 목표입니다. )
- MLlib는 다음을 제공합니다.
- ML 알고리즘 - 협업 필터링, 분류, 클러스터링 등 알고리즘
- Featurization - 기능 추출, 변환, 차원 축소 및 선택 등 기능
- Pipelines - 파이프라인 구성, 평가 및 조정
PySpark MLlib가 필요한 이유
- Sklearn은 가장 유명한 파이썬 머신러닝 알고리즘입니다.
- Sklearn은 중소 규모 데이터 세트에 적합합니다. - 병렬 처리기능이 필요한 대규모 데이터셋에는 적용되지 않습니다.
- PySpark MLlib 은 클러스터의 노드에서 병렬로 적용 할 수 있는 작업에 적합합니다.
- Sklearn과 달리, PySpark MLlib는 Python외에도 Scala, Java, R과 같은 고급 언어를 지원합니다.
- MLlib은 또한 머신러닝 파이프라인을 구축하기 위한 고급 API를 제공합니다.
- 머신러닝 파이프 라인은 여러 머신러닝 알고리즘을 결합한 완벽한 워크 플로우입니다.
MLlib Algorithms
- Classication ( Binary and Multiclass ) and Regression: LinearSVMs, logisticregression, decisiontrees, randomforests, gradient-boostedtrees, naiveBayes, linearleastsquares, Lasso, ridgeregression, isotonic regression
- Collaborative filtering: Alternating least squares (ALS)
- Clustering: K-means, Gaussian mixture, Bisecting K-means and Streaming K-Means
웬만한거 다 지원한다… ?
The three C’s of Machine learning
- Collaborative filtering
- 엔티티 / 사용자와의 과거 행동, 선호 또는 유사성
- Classication
- 새로운 관측치가 속하는 범주 세트를 식별
- Clustering
- 유사한 특성을 기반으로 데이터를 클러스터로 그룹화
MLlib import
pyspark.mllib.recommendation
from pyspark.mllib.recommendation import ALS
- pyspark.mllib.classfication
from pyspark.mllib.classification import LogisticRegressionWithLBFGS
- Pyspark.mllib.clustering
from pyspark.mllib.clustering import KMeans
Collaborative filtering
- 공동 필터링은 많은 사용자로부터 선호도 또는 취향 정보를 수집함으로써 사용자의 관심사 등을 알 수 있는 방법입니다.
- 공동 필터링은 추천 시스템에서 가장 일반적으로 사용되는 알고리즘 중 하나입니다.
- 공동 필터링에는 두 가지 접근 방식이 있습니다.
- 사용자 - 사용자 접근
- 대상 사용자와 유사하며 공동 평가를 사용하여 대상 사용자를 위한 권장 사항을 만듭니다.
- 아이템 - 아이템 접근
- 대상 사용자와 연관된 항목과 유사하거나 관련된 항목을 찾아서 추천합니다.
- 사용자 - 사용자 접근
pyspark.mllib.recommendation
- Rating 클래스는 RDD를 구문 분석하고 사용자, 제품 및 평가의 튜플을 만드는 데 매우 유용합니다.
from pyspark.mllib.recommendation import Rating
r = Rating(user=1, product=2, rating = 5.0)
(r[0], r[1], r[2])
[output]
(1, 2, 5.0)
randomSplit()
- 훈련 및 테스트 세트에 들어가는 것은 기계 학습의 필수 부분입니다.
- PySpark 의
randomSplit()함수를 사용하면, 훈련데이터와 검증데이터를 나눌 수 있습니다.
data = sc.parallelize([1,2,3,4,5,6,7,8,9,10])
training, test = data.randomSplit([0.6,0.4])
Alternating Least Squares ( ALS )
- 이전 구매 또는 평가를 기반으로 고객이 원하는 제품을 찾습니다.
- ALS 방법에서는, Rating 객체를
ALS.train(ratings, rank, iterations)같이 표현합니다.
r1 = Rating(1, 1, 1.0)
r2 = Rating(1, 2, 2.0)
r3 = Rating(2, 1, 2.0)
ratings = sc.parallelize([r1, r2, r3])
model = ALS.train(ratings, rank=10, iterations=10)
predictAll()
predictAll()메소드는 사용자 ID 및 제품 ID 쌍의 RDD를 이용해서 각 쌍에 대한 예측을 리턴합니다.
unrated_RDD = sc.parallelize([(1,2), (1,1)])
predictions = model.predictAll(unrated_RDD)
predictions.collect()
[output]
[Rating(user=1, product=1, rating=1.000020303010),
Rating(user=1, product=2, rating=1.98983910010)]
MSE
(actual rating - predicted rating) 을 이용해서 모델을 평가합니다.
rates = ratings.map(lambda x: ((x[0],x[1]),x[2]))
preds = predictions.map(lambda x: ((x[0], x[1]), x[2]))
rates_preds = rates.join(preds)
MSE = rates_preds.map(lambda x: (x[1][0] - x[1][1])**2).mean()
Classification
- 분류는 항목이 속하는 범주를 식별하는 널리 사용되는 기계학습 알고리즘입니다.
- 분류는 알려진 레이블이 있는 일련의 데이터를 취합니다. (지도학습)
- 미리 결정된 기능과 해당 정보를 기반으로 새 레코드에 레이블을 지정합니다.
Logistic Regression
- 로지스틱 회귀는 일부 독립 젼수가 주어진 이진 반응을 예측하는 분류 방법입니다.
- Y축의 라벨과의 관계를 측정합니다.
- 로지스틱 회귀 분석에서 출력은 0 or 1의 값을 가지게 됩니다. (시그모이드)
Working with Vectors
- PySpark MLlib는 Vector와 라벨포인트를 가지는 특수한 데이터 타입을 가집니다.
- Vector의 두가지 타입
- Dense Vector - 모든 항목을 부동 소수점 숫자의 배열로 저장합니다.
- Sparse vector - 0이 아닌 값과 해당 인덱스만 저장합니다.
denseVec = Vectors.dense([1.0, 2.0, 3.0])
sparseVec = Vectors.sparse(4, {1: 1.0, 3: 5.5})
- LabelPoint() - 입력 기능과 예상 값을 둘러선 wrapper입니다.
- 레이블과 기능 벡터가 포함되어 있습니다.
- 레이블은 부동 소수점 값이며, 이진 분류의 경우 1 or 0의 값을 가집니다.
positive = LabeledPoint(1.0, [1.0, 0.0, 3.0])
negative = LabeledPoint(0.0, [2.0, 1.0, 1.0])
HashingTF()
- 주어진 문서를 벡터로 계산하는 HashingTF 알고리즘
from pyspark.mllib.feature import HashingTF
sentence = "hello hello world"
words = sentence.split()
tf = HashingTF(10000)
tf.transform(words)
SparseVector(10000, {3065: 1.0, 6861:2.0})
HashingTF(10000) 크기의 벡터를 만듭니다. 이후 words를 통해 벡터화 합니다.
Logistic Regression - LogisticRegressonWithLBFGS
- 로지스틱 회귀를 위한 LogisticRegressionWithLBFGS입니다.
- 최소 요구사항
- LabelPoint
- RDD
data = [
LabeledPoint(0.0, [0.0, 1.0]),
LabeledPoint(1.0, [1.0, 0.0]),
]
RDD = sc.parallelize(data)
lrm = LogisticRegressionWithBFGS.train(RDD)
lrm.predict([1.0, 0.0])
Clustering
- 비지도 학습에 한 종류
- 레이블 없이 객체를 유사성이 높은 클러스터로 그룹화합니다.
- 지도학습과 달리, 필터링 및 분류, 데이터에 레이블이 지정된 경우 레이블링되지 않은 데이터를 이해하기 위해 클러스터링을 사용하기도 함
K-means
- K-means는 몇개의 그룹으로 묶을 것인지, 데이터 요소와 사전 정의 된 수의 k 클러스터를 제공합니다.
- 일련의 반복을 통한 K-means 알고리즘은 군집을 생성합니다.
K-means with Spark MLlib
- PySpark MLlib를 사용한 K-means 클러스터링 알고리즘은, 숫자 데이터를 RDD에 로드한 다음, 구분 기호를 기준으로 데이터를 구문 분석합니다.
RDD = sc.textFile("WineData.csv").map(lambda x:x.split(",")).\
map(lambda x: [float(x[0]), float(x[1])])
RDD.take(5)
Train a K-means
from pyspark.mllib.clustering import KMeans
model = Kmeans.train(RDD, k=2, maxIterations=10)
Evaluating the K-means Model
from math import sqrt
def error(point):
center = model.centers[model.predict(point)]
return sqrt(sum([x**2 for x in (point-center)]))
WSSSE = RDD.map(lambda point: error(point)).reduce(lambda x,y: x+y)
Evaluating을 위해서 def를 하나 정의하고 이를 이용해서 평가합니다.
Visualizing clusters
wine_data_df = spark.createDataFrame(RDD, schema=['col1','col2'])
wine_date_df_pandas = wine_data_df.toPandas()
cluster_centers_pandas = pd.DataFrame(model.clusterCenters, columns=['col1', 'col2'])
plt.scatter(wine_data_df_pandas['col1'], wine_data_df_pandas['col2'])
plt.scatter(cluster_centers_pandas['col1'], cluster_centers_pandas['col2'], color='red', marker='x')
군집화가 잘 됬는지 확인하는 가장 좋은 방법은 시각화를 진행하는 것입니다.
시각화를 하기위해서 Pandas DataFrame으로 변환하고 matplotlib을 이용해서 시각화를 진행합니다.