Data Cleaning
- 파이프라인 처리에 사용할 원시 데이터를 준비하는 과정을 Data Cleaning 이라고 정의합니다.
- Data Cleaning 는 모든 프로덕션 데이터 시스템의 필수입니다.
- 데이터가 깨끗하지 않을 경우 신뢰할 수 없으며 문제가 발생할 수 있습니다.
- 몇가지 과정
- 텍스트 서식 변경 or 바꾸기
- 데이터를 기반으로 한 계산
- 불완전한 데이터 제거 or 쓰레기 데이터 제거
Data Cleaning 하는 이유
전형적인 Data System 문제
- 성능 최적화 문제
- 데이터 흐름 구성 문제
Spark의 장점
- 데이터 처리 용량의 확장
- 데이터 핸들링을 위한 프레임워크 제공
데이터 정제 예시
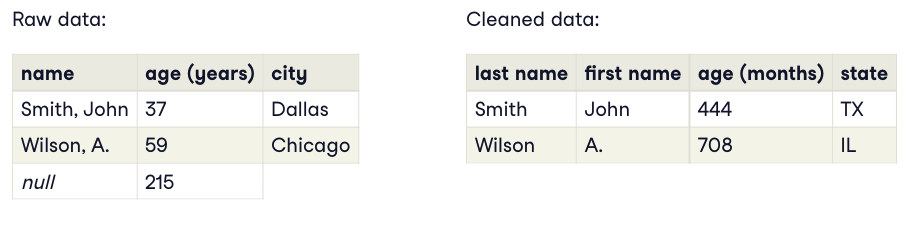
OLTP -> OLAP 구조로 변경해야 사용하기 좋습니다.
Spark Schemas
- 데이터 정리의 주요 기능은 모든 데이터가 예상 형식인지 확인해야 합니다.
- Spark는 스키마를 사용하여 데이터 세트의 유효성을 검사하는 기본 제공 기능을 제공합니다.
- 스키마는 주어진 DataFrame에 대한 열의 수와 유형을 정의하고 유효성을 검사합니다.
- 스키마에는 다양한 유형의 필드가 포함될 수 있습니다.
- string
- date
- integer
- array
- 정의된 스키마를 통해 Spark는 읽는 동안 준수하지 않는 데이터를 필터링하여 예상 된 정확성을 보장합니다.
- 스키마는 성능적인 이점을 가집니다.
- 데이터를 가져올 때, 스키마를 추론하려고 시도하면서 데이터를 두번 읽게 되는데, 이를 정의할 경우 생략할 수 있습니다.
Spark Schema Example
import pyspark.sql.types
peopleSchema = StructType([
StructField('name', StringType(), True),
StructField('age', IntegerType(), True),
StructField('city', StringType(), True)
])
people_df = spark.read.format('csv').load(name='rawdata.csv', schema=peopleSchema)
위와 같이, 각 필드에 대한 항목을 포함하는 StructField로 구성된 StructType을 정의합니다.
각 StructField는 필드임, dataType, 데이터 null 여부 로 구성됩니다.
스키마를 구성하고, spark.read를 통해 파일을 읽어올 때 정의합니다.
Python 변수
- Mutable
- Flexibility
- Concurrency - 동일한 데이터를 수정하려는 여러 동시 구성 요소
- 이러한 작업들은 복잡성을 추가할 수 있습니다.
Spark 변수 - Immutability
- 반드시 필요한 것은 아니지만 불변성은 함수형 프로그램의 구성 요소입니다.
- 한번 정의되고 초기화 후에 수정할 수 없습니다.
- 변수 이름을 재사용하면, 원래 데이터가 삭제됩니다.
- Spark는 모든 클러스터 구성 요소간에 데이터를 공유할 수 있습니다.
예시
voter_df = spark.read.csv('voterdata.csv')
데이터가 생성되면, 두 가지 추가 작업을 수행하려고 합니다.
voter_df = voter_df.withColumn('fullyear', voter_df.year + 2000)
voter_df = voter_df.drop(voter_df.year)
위의 작업은, 실제 데이터를 수정하는 것이 아니라, 새로운 데이터에 연산을 진행하고 값을 저장합니다.
이후, 데이터 프레임에서 원래 연도 열을 삭제합니다.
Spark - Lazy Processing
- 대규모 데이터 세트에서 빠르게 수행하는 이유
- Spark의 Lazy Processing은 작업이 수행 될 때까지 실제로 거의 발생하지 않습니다.
- 이전 예시에 데이터를 핸들링하지만, 실제로는 데이터를 읽거나 추가, 수정하지 않습니다.
- Spark는 원하는 작업에 대한 지침(변환)을 업데이트합니다.
- 이러한 기능을 통해 Spark는 원하는 결과를 얻디 위해 가장 효율적인 작업 집합을 수행합니다.
voter_df = voter_df.withColumn('fullyear', voter_df.year + 2000)
voter_df = voter_df.drop(voter_df.year)
voter_df.count()
이전 코드에서, count()함수를 통해 Action을 취하기 전 까지 실제로 작동하지 않습니다.
CSV 파일의 문제점
- 스키마가 정의되지 않았습니다.
- 중첩데이터를 사용하기 위해서는 특수하게 핸들링 해야합니다. ( 이스케이프 문자, 쉼표 등 )
- 인코딩 형식으로 인해 사용되는 언어가 제한됩니다.
Spark and CSV files
- 일반적인 CSV파일 문제 외에도 Spark에는 CSV데이터를 처리하는 몇가지 특정 문제가 있습니다.
- CSV 파일을 가져오고 구문 분석하는 과정은 상당히 느립니다.
- 가져오는 프로세스 중, 작업자간에 파일을 공유할 수 없습니다. ( 병렬처리 불가 )
- 스키마가 정의되지 않은 경우 스키마를 유추하기 전에 모든 데이터를 읽어야합니다. ( 이중 )
- Spark에는 predicate pushdown이라는 기능이 있습니다. ( CSV에서는 불가 )
- 최소한의 작업을 수행하도록 작업을 정렬하는 방법 ( 파일 스캔을 효율적으로 할 수 있는 기능 )
- 처리 전 데이터 필터링은 predicate pushdown의 기본 최적화 중 하나입니다.
- 이를 통해 대용량 데이터 세트에서 처리해야하는 정보의 양이 크게 줄어 듭니다.
- 하지만 CSV데이터에 대해서는 적용할 수 없습니다.
- Spark 프로세스는 여러단계를 가지며, 중간 단계 파일 표현을 활용할 수 있습니다.
- 이러현 표현을 통해 소스에서 데이터를 다시 생성하지 않고, 데이터를 사용할 수 있습니다.
- 단, CSV를 사용하려면 스키마, 인코딩 형식 등을 정의하는 상당한 추가 작업이 필요합니다.
Parquet Format
- Parquet은 Hadoop기반 시스템에서 사용하기 위해 개발 된 압축되어 있는 데이터 형식입니다.
- Spark, Hadoop, Apache Impala 등이 포함됩니다.
- Parquet 형식은 청크(Chunk, <파일 더미=""> - PNG, IFF, MP3, AVI 같은 멀티 미디어 파일 형식) 로 액세스 할 수있는 데이터로 구성됩니다.
- 전체 파일을 처리하지 않고도 효율적인 읽기 / 쓰기 작업이 가능합니다.
- 이 구조화 된 형식은 Spark의 predicate pushdown을 지원합니다. - 상당한 성능 향상을 제공
- Parquet 파일은 자동으로 스키마 정보를 포함하고 데이터 인코딩을 처리합니다.
- Parquet 파일은 바이너리 파일 형식이며 적절한 도구로만 사용할 수 있습니다. ( 텍스트 편집기로 편집 할 수 있는 CSV파일과는 대조적 )
Working with Parquet
- Parquet files 읽는 방법1
df = spark.read.format('parquet').load('filename.parquet')
CSV파일 형식을 읽는 것처럼, format메소드를 이용해서 형식 지정
- Parquet files 읽는 방법2
df = spark.read.parquet('filename.parquet')
Spark.read.parquet함수를 통해서 바로 읽는 방법
- Parquet files를 작성하는 방법
df.write.format('parquet').save('filename.parquet')
df.write.parquet('filename.parquet')
Parquet and SQL
- Parquet 파일은 Spark내에서 다양한 용도로 사용됩니다. ( SQL 작업을 수행하는데 완벽 )
flight_df = spark.read.parquet('flights.parquet')
Parquet파일에 대해 SQL 쿼리를 수행하려면 스파크를 통해 데이터 프레임을 만들어야 합니다.
flight_df.createOrReplaceTempView('flights')
이후 createOrReplaceTempView() 메서드를 통해 Parquet 데이터의 별칭을 SQL 테이블로 추가합니다.
short_flights_df = spark.sql('SELECT * FROM flgiths WHERE flightduration < 100')
마지막으로 SQL 구문과 스파크를 사용하려 쿼리합니다.
이러한 방법은 Parquet를 백업 저장소로 사용하고 있기 때문에 우리가 가진 모든 성능 이점을 얻습니다.
DataFrame
- DataFrame 은 행과 열로 구성되며, 일반적으로 데이터베이스 테이블과 유사합니다.
- DataFrame은 변경할 수 없습니다. 데이터 구조나 내용이 변경되면 새로운 DataFrame이 생성됩니다.
- DataFrame은 변환을 사용하여 수정됩니다.
voter_df.filter(voter_df.name.like('M%'))
voters = voter_df.select('name', 'position')
filter() 명령은 이름이 문자 ‘M’으로 시작하는 행만 반환합니다.
select() 명령은, 입력한 컬럼에 해당하는 열만 반환합니다.
DataFrame 변환
- Filter / Where
- 인수에 정의 된 요구 사항을 충족하는 행만 포함
voter_df.filter(voter_df.date > '1/1/2019')
- Select
- 요청 된 열을 반환
voter_df.select(voter_df.name)
- withColumn
- DataFrame에 새 열을 만듭니다.
voter_df.withColumn('year', voter_df.date.year)
- drop
- DataFrame에서 열을 제거합니다.
voter_df.drop('unused_column')
Filtering data
- 필터링을 사용하면 원하는 결과와 일치하는 데이터만 사용할 수 있습니다.
- 결측치 제거
- 이상 데이터 제거
- DataFrame 분할 ( 결합된 데이터 syslog 파일 등 )
voter_df.filter(voter_df['name'].isNotNull())
voter_df.filter(voter_df.date.year > 1800)
voter_df.where(voter_df['_c0'].contains('VOTE'))
voter_df.where(~ voter_df._c1.isNull())
문자열 변환
pyspark.sql.functions에 포함되어 있습니다.
import pyspark.sql.functions as F
voter_df.withColumn('upper', F.upper('name'))
withColumn() 함수를 사용하여 문자열 변환을 합니다. upper 함수를 통해 Name의 대문자로 변환
voter_df.withColumn('splits', F.split('name', ' '))
처리 전용 중간 열을 만들 수 있는데, 이는 여러 단계가 필요한 복잡한 변환을 명확히 하는데 유용합니다.
voter_df.withColumn('year', voter_df['_c4'].cast(IntegerType()))
문자열 열을 정수로 변환하는 방식의 변환도 유용합니다.
ArrayType() column functions
- Spark로 데이터 정리를 수행하는 동안 ArrayType() 열과 상호 작용해야 할 수 있는데, 이는 일반적인 파이썬의 List와 유사합니다.
.size(<column>)는 지정된 ArrayType() 인수에 있는 항목 수를 반환합니다..getItem(<index>)는 인덱스 인수를 취하고 목록 열의 해당 인덱스에 있는 항목을 반환합니다.- 이 외에도 다양한 함수가 있습니다.
Conditional clauses
- Spark에서 기존의 if / then / else 문을 수행 할 수 있지만, DataFrame의 각 행이 독립적으로 평가되므로 심각한 성능 저하를 초래합니다. ( 최적화 된 기본 제공 조건을 사용하면 이 문제가 완화됩니다. )
.when().otherwise()
예시
.when(<if condition>, <then x>)
df.select(df.Name, df.Age, when(df.Age >= 18, "Adult"))
- 여러개의
when()
df.select(df.Name, df.Age, when(df.Age >= 18, "Adult").when(df.Age < 18, "Minor"))
.otherwise()
df.select(df.Name, df.Age, when(df.Age >= 18, "Adult").otherwise("Minor"))
otherwise문은 else문과 유사합니다.
사용자 정의 함수
- 사용자 정의 함수 or UDFs ( User Defined Functions )
- 파이썬 메소드
pyspark.sql.functions.udf를 통해서 호출됩니다.- 변수로 저장되며, Spark 함수로 호출 할 수 있습니다.
예시
def reverseString(mystr):
return mystr[::-1]
먼저 파이썬 함수를 정의합니다.
udfReverseString = udf(reverseString, StringType())
함수를 래핑하고 나중에 사용할 수 있도록 변수에 저장합니다.
정의한 메서드의 이름과, 반환 할 Spark 데이터 유형이 인자로 들어갑니다.
user_df = user_df.withColumn('ReverseName', udfReverseString(user_df.Name))
정의한 UDF를 이용해서, 새로운 열을 추가합니다.
다른 예시
def sortingCap():
return random.choice(['G', 'H', 'R', 'S'])
udfSortingCap = udf(sortingCap, StringType())
user_df = user_df.withColumn('Class', udfSortingCap())
다른 예시는 인수가 필요하지 않은 함수를 사용하는 것입니다.
Partitioning
- Spark는 DataFrame을 파티션 or 청크로 분할합니다.
- 파티션은 자동으로 정의, 확대, 축소 합니다. (사용중인 Spark 클러스터 유형에 따라 크게 다를 수 있습니다.)
- 파티션의 크기는 다양하지만 일반적으로 파티션의 크기를 동일하게 유지하는게 좋습니다.
- 각 파티션이 독립적으로 처리됩니다.
Lazy processing
- Spark의 모든 변환 작업은 지연됩니다.
- 실제로 수행하는 것이 아니라, DataFrame에 수행해야 하는 작업을 정의합니다.
- 정의한 변환 작업은 Spark Action 작업을 실행할 때 실행됩니다.
- Spark는 최상의 성능을 위해 변환을 재정렬 할 수 있습니다.
- 일반적으로는 눈에 띄지 않지만, 때때로 예기치 못한 문제가 발생할 수 도 있습니다. (ID오류 등)
- 이로 인해 실제로 문제가 발생하지는 않지만 무엇을 예상해야 하는지 모르는 경우 데이터가 비정상적으로 보일 수 있습니다.
Adding IDs
- 관계형 데이터베이스에는 행을 식별하는 데 사용되는 필드가있습니다.
- 이러한 ID는 일반적으로 값이 증가하고 순차적이며 가장 중요한 고유 한 정수입니다.
- 이러한 ID는 본질적으로 병렬적이지 않다는 문제를 가집니다.
Monotonically increasing IDs
- Spark에는
monotonically_increasing_id()라는 내장 함수가 있습니다. - 값이 증가하고 고유한 정수 ID를 제공합니다.
- 이러한 ID는 반드시 순차적인 것은 아닙니다. ( 값 사이에 종종 매우 큰 간격이 있을 수 있습니다. )
- 일반 관계형 ID와 달리 Spark는 완전히 병렬입니다.
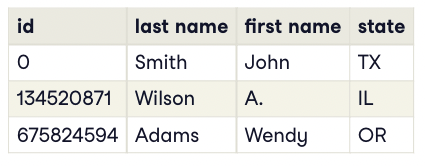
테이블의 ID필드는 값이 증가하는 정수이지만 순차적이지 않습니다.
참고
- 파티션과 단조롭게 증가하는 ID의 작동방식은 많은 차이가 있습니다.
- 특히 join 이 관련된 경우 작업의 순서가 맞지 않습니다.
- 변환을 테스트 해보는 것이 좋습니다.
Caching in Spark
- 클러스터에 있는 처리 노드의 메모리 또는 디스크에있는 DataFrame
- 캐싱은 후속 변환 or 작업의 속도를 향상시킵니다. ( 원래 데이터 소스에서 더 이상 데이터를 검색 할 필요가 없습니다. )
- 캐싱을 사용하면 클러스터의 리소스 사용률이 감소합니다.
캐싱의 단점
- 매우 큰 데이터 세트는 캐시 된 데이터 프레임 용으로 예약 된 메모리에 맞지 않을 수 있습니다.
- 나중에 요청 된 변환에 따라 캐시는 성능에 도움이 되는 작업을 수행하지 못할 수 있습니다.
- 데이터 세트가 메모리에 캐시 된 상태로 유지되지 않으면 디스크에 지속될 수 있습니다.
- Spark 클러스터의 디스크 구성에 따라 성능이 크게 향상되지 않을 수 있습니다.
- 리소스 및 로컬 디스크 I / O 가 느린 경우 개체 캐싱을 피하는 것이 좋습니다.
- 캐시된 개체의 수명이 보장되지 않습니다.
Caching 팁
- 캐싱은 매우 유용하지만, DataFrame을 다시 사용할 계획인 경우에만 해당됩니다.
- 단일 작업에만 필요한 경우 캐싱할 필요가 없습니다.
- 캐싱으로 성능을 측정하는 가장 좋은 방법은 다양한 구성을 테스트하는 것입니다.
- 처리주기의 다양한 지점에서 데이터 프레임을 캐싱하고 처리 시간이 개선되는지 확인하세요
- 메모리 또는 빠른 NVMe / SSD 스토리지에 캐시하세요.
- 대용량을 처리하는 경우 로컬 하드 드라이브가 유용할 수 있습니다.
- 정상적인 캐싱이 작동하지 않는 것 같으면, Parquet표현을 만들어 보세요
- 작업이 끝나면 DataFrame 캐싱을 수동으로 중지 할 수 있습니다.
Caching 만들기
.cashe()함수 호출을 통해 만들 수 있습니다.- 주어진 Action 이전에 DataFrame 객체에 대한 캐시를 만듭니다.
voter_df = spark.read.csv('voter_data.txt.gz')
voter_df.cache().count()
위와 같은 방법으로 cache를 저장할 수 있습니다.
voter_df = voter_df.withColumn('ID', monotonically_increasing_id())
voter_df = voter_df.cache()
voter_df.show()
다음과 같이 변수에 담을 수 도 있습니다.
Cache operations
- Spark 캐싱과 함께 몇 가지 다른 옵션을 사용할 수 있습니다.
.is_cached함수를 통해 캐시되었는지 확인 할 수 있습니다.
print(voter_df.is_cached)
.unpersist()를 통해 캐시를 해제할 수 있습니다.
voter_df.unpersist()
Spark clusters
- Spark 클러스터는 드라이버 프로세스와 필요한만큼의 작업자 프로세스라는 두가지 유형으로 구성됩니다.
- 드라이버는 작업 할당 및 작업자의 데이터 결과 통합을 처리합니다.
- 작업자는 일반적으로 Spark 작업의 실제 변환 / 작업 을 처리합니다. 작업이 할당되면 독립적으로 작동하고 결과를 운전자에게 다시 보고합니다.
- Spark 클러스터를 실행하는 방법은 여러방법이 있으며, 작업자 환경에 따라 다릅니다.
Import performance
- 사용 가능한 가져오기 개체가 많을 수록 클러스터가 작업을 더 잘 분할 할 수 있습니다.
- 큰 클러스터를 사용하면, 각 작업자가 가져오기 프로세스에 참여할 수 있습니다.
- 큰 파일은 여러개의 작은 파일보다 성능이 훨씬 떨어집니다.
-
더 큰 파일이지만, 더 작은 파일간에 분할 된 동일한 양의 데이터를 쉽게 처리할 수 있습니다.
- 여러 파일이 있는 경우에도 단일 import 문을 정의 할 수 있습니다.
airport_df = spark.read.csv('airport-*.txt.gz')
가져오기 파일 이름을 정의 할 때 모든 형식의 표준 와일드 카드 기호를 사용할 수 있습니다.
- 개체의 크기가 같으면 클러스터는 매우 큰 개체와 매우 작은 개체를 혼합하는 것보다 성능이 좋습니다.
Schemas
- Spark의 잘 정의 된 스키마는 갸져오기 성능을 크게 향상합니다.
- 스키마가 정의되지 않은 경우 가져오기 작업은 구조를 추론하기 위해 데이터를 여러번 읽어야합니다.
- 데이터가 많으면 속도가 매우 느립니다.
- Spark는 데이터 개체를 사용자와 동일하게 정의하지 않을 수도 있습니다.
- Spark 스키마는 가져오기시 유효성 검사도 제공합니다.
개체를 더 작은 개체로 분할하는 방법
- split, cut, awk 같은 내장 OS 유틸리티 사용
split -l 10000 -d largefile chunk-
<쪼갤 갯수> <쪼갤 파일> <접두사>
- 파이썬을 사용하여 적합하다고 생각되는 객체로 분할
- 단일 파일을 읽은 다음, Parquet 으로 분할
df_csv = spark.read.csv('singlelargefile.csv')
df_csv.write.parquet('data.parquet')
df = spark.read.parquet('data.parquet')
초기 가져오기가 느리더라도 이후 분석할 때 잘 작동합니다.
Configuration options
- Spark 에는 설치의 모든 측면을 제어하는 다양한 구성 설정이 있습니다.
- 구성은 클러스터의 특정 요구 사항에 가장 적합하도록 수정할 수 있습니다.
- 구성 설정을 보거나 설정하기 위해서는 Spark를 실행합니다.
spark.conf.get(<configuration name>)
spark.conf.set(<configuration name>)
Cluster Type
- Spark 배포는 사용자의 정확한 요구 사항에 따라 달라질 수 있습니다.
- Single node ( 단일 시스템 )
- Standalone ( 드라이버 및 작업자로 전용 머신이 있는 독립형 클러스터 )
- Managed ( 관리되는 클러스터 )
- YARN
- Mesos
- Kubernetes
Driver
- Spark 클러스터 당 하나의 드라이버가 있습니다.
- 클러스터의 다양한노드 / 프로세스에 대한 작업 할당 처리
- 드라이버는 모든 프로세스 및 작업의 상태를 모니터링하고 모든 작업을 처리합니다.
- 클러스터에 있는 다른 프로세스의 결과 통합
- 공유 데이터( 리소스 등 작업에 필요한 데이터 )에 대한 모든 액세스를 처리
Driver Tip
- 다른 노드에 비해 메모리를 두배로 늘리는 것이 좋습니다. ( 이는 작업 모니터링 및 데이터 통합 작업에 유용합니다. )
- Spark 시스템과 마찬가지로 빠른 로컬 저장소는 이상적인 설정에서 Spark를 실행하는데 유용합니다.
Worker
- 작업자는 드라이버가 할당 한 실행중인 작업을 처리하고 이러한 결과를 드라이버에게 전달합니다.
- 작업자는 모든 코드, 데이터 및 주어진 작업을 완료하는 데 필요한 리소스에 대한 액세스 합니다.
- 권장사항
- 작업 유형에 따라 더 많은 작업자 노드가 더 큰 노드보다 낫습니다.
- Spark의 모든 것과 마찬가지로, 다양한 구성을 테스트하여 워크로드에 대한 균형을 찾습니다.
- 작업자는 캐싱, 중간 파일 등을 위해 고속 로컬 스토리지를 사용할 수 있습니다.
Spark execution plan
- 스파크가 성에 미치는 영향을 이해하려면 내부에서 수행되는 작업을 볼 수 있어야 합니다.
voter_df = df.select(df['VOTER NAME']).distinct()
voter_df.explain()

Shuffling
- Spark는 클러스터의 다양한 노드에 데이터를 배포합니다. 이에 부작용이 셔플링입니다.
- 셔플링은 특정 작업을 완료하는데 필요한 데이터 조각을 다양한 작업자에게 이동하는 것입니다.
- 사용자로 부터 복잡성을 감춥니다.
- 몇개의 노드에 모든 데이터가 필요한 경우, 필요한 전송을 완료하는데 속도가 느릴 수 있습니다.
- 클러스터링의 전체 처리량을 낮춥니다.
- 작업자는 데이터가 전송되기를 기다리는 시간을 소비합니다. ( 이는 나머지 작업에 사용할 수 있는 작업자의 수를 제한합니다. )
- 셔플링은 종종 필요한 구성요소이지만, 가능한 최소화하는 것이 좋습니다.
셔플링 제한
- 셔플링을 완전히 제거하는 것은 까다로울 수 있지만, 이를 제한 할 수 있는 몇가지 사항이 있습니다.
.repartition(num_partitions)를 사용하지 않습니다.- repartition 함수는 요청된 파티션 수인 단일 인수를 사용하는 함수입니다.
- repartition에는 노드와 프로세스간에 데이터를 완전히 섞어야 하며 비용이 많이 듭니다.
- 파티션 수를 줄여야 하는 경우,
.coalesce(num_partitions)을 사용하세요. 이는 전체 데이터 셔플없이 데이터를 통합합니다. ( 더 적은 파티션 수를 입력해야 합니다. )
.join()함수의 사용을 조심하세요.- join함수의 사용은 무차별 적으로 셔플 작업을 유발할 수 있으며, 클러스터 로드가 증가하고 처리 시간이 느려집니다.
.broadcast()를 사용해서 DataFrame을 합치세요.
- 최적화 하세요.
Broadcasting
- Spark에서 브로드캐스팅은 각 작업자에게 개체의 복사본을 제공하는 방법입니다.
- 각 작업자가 자체 데이터 사본을 가지고 있으면 노드 간 통신이 덜 필요합니다.
- 이것은 데이터 셔플을 제한하고 노드가 독립적으로 작업할 가능성이 높습니다.
- 브로드캐스팅을 사용하면, 속도를 크게 높힐 수 있습니다.
- 특히 조인되는 DataFrame 중 하나가 다른 것보다 훨씬 작은 경우
join()작업을 수행
- 특히 조인되는 DataFrame 중 하나가 다른 것보다 훨씬 작은 경우
.broadcast(<DataFrame>)를 통해 구현합니다.
from pyspark.sql.functions import broadcast
combined_df = df_1.join(broadcast(df_2))
아주 작은 것을 사용하면, 브로드 캐스팅이 느려질 수 있습니다.
Data Pipeline
- 데이터 파이프라인은 단순한 단계 집합입니다.
- 입력 데이터소스는 단계별로 이동하여 원하는 출력으로 변환해야 합니다.
- 데이터 파이프라인은 여러 단계 or 구성 요소로 구성되며, 여러 시스템이 걸쳐있을 수도 있습니다.
- 데이터 파이프라인은 많은 시스템과 통신 할 수 있습니다.
Data Pipeline 구성
- 데이터 파이프라인은 크게 입력, 변환, 출력으로 구성됩니다. ( 데이터를 전달하기 전에, 검증 및 분석 단계가 있는 경우도 많습니다. )
- 입력은 CSV, JSON, 텍스트 등을 포함하여 모든 데이터 유형이 될 수 있습니다.
- 다양한 방법을 이용해서 원하는 형식으로 데이터를 변환합니다.
- withColumn(), filter(), drop() 등
- 변환을 정의한 후에는 데이터를 사용 가능한 형식으로 출력해야 합니다.
- 유효성 검사는 테스트를 실행하여, 예상한 대로 결과가 출력되는지 확인합니다.
- 분석은 다음 사용자에게 데이터를 전달하기 전 마지막 단계로, 사용자가 데이터 세트를 더 쉽게 사용할 수 있도록 하는 모든 작업을 포함합니다.
Pipeline details
- 데이터 파이프라인은 공식적으로 정의된 개체가 아닙니다. ( 단, Spark 데이터파이프라인 객체를 사용한 경우는 다릅니다. )
schema = StructType([
StructField('name', StringType(), False),
StructField('age', StringType(), False),
])
df = spark.read.format('csv').load('datafile').schema(schema)
df = df.withColumn('id', monotonically_increasing_id())
...
df.write.parquet('outdata.parquet')
df.write.json('outdata.json')
What are we trying to parse?
- 데이터를 읽을 때, 완전히 균일 한 파일이 제공되는 경우는 거의 없습니다.
- 대부분의 경우 데이터를 제거하거나, 포맷해야하는 콘텐츠가 있습니다.
- Incorrect data
- Empty rows
- Commented lines
- Headers
- Nested structures
- Multiple delimiters
- Non-regular data
- 표형식에 맞지 않으며 각각의 다른 수의 열로 구성된 경우
- Incorrect data
[예시] Stanford ImageNet annotations
- 다양한 ImageNet 이미지에서 개를 찾고 식별하는데 초점을 맞춘 데이터
- 데이터는 모든 식별 된 개 목록을 제공합니다.
- 여러 개가 같은 이미지에 있는 경우를 포함하는 이미지도 존재
- ImageNet 내의 폴더를 포함한 기타 메타데이터가 포함됩니다. ( 데이터 세트, 이미지 크기 및 이미지 경계 )

[예시] blank lines, headers and comments 제거
- Spark으 CSV parse는 선택적 매개 변수를 통해 일반적인 데이터 문제를 해결할 수 있습니다.
- CSV 구문 분석을 사용할 때, 빈 줄이 자동으로 제거됩니다.
- 선택적 명명된 인수 comment를 사용하여 주석을 제거 할 수 있습니다.
df1 = spark.read.csv('datafile.csv.gz', comment='#')
- 헤더행은, header라는 선택적 매개 변수를 통해 구문 분석할 수 있습니다.
- 스키마가 정의되지 않은 경우 열 이름은 처음에 헤더에 정의된 대로 설정됩니다.
df1 = spark.read.csv('datafile.csv.gz', header='True')
자동적으로 컬럼 생성
- CSV 데이터를 Spark로 가져올 때, 가능한 경우 자동적으로 DataFrame을 생성합니다.
- CSV의 텍스트 행을 ‘sep’라는 정의 된 인자를 통해 분할합니다. ( default = ‘,’ )
df1 = spark.read.csv('datafile.csv.gz', sep=',')
- CSV 구문 분석기는 구분 문자가 문자열 내에 없는 경우 데이터 구문 분석에도 성공합니다. (‘_c0’ 열에 저장)
df1 = spark.read.csv('datafile.csv.gz', sep='*')
이 트릭을 이용해서, 중첩되거나 복잡한 데이터 구문 분석을 할 수 있습니다.
Validation
- 유효성 검사는 데이터 집합이 예상 형식을 준수하는지 확인하는 과정입니다.
- 행과 열의 수가 맞는지?
- 데이터 타입이 일치하는지?
- 더 복잡한 규칙에 대한 유효성 검사를 진행
Validating via joins
- 유효성을 검사하는데 사용되는 한가지 기술은 조인을 사용해서 DataFrame의 콘텐츠가 알려진 집합과 일치하는지 확인하는 방법입니다.
- join을 사용하면 데이터가 집합에 있는지 쉽게 확인 할 수 있습니다.
- 특히 긴 항목 목록에 대해 개별 행의 유효성 검사하는 것과 비교하여 비교적 빠릅니다.
parsed_df = spark.read.parquet('parsed_data.parquet')
company_df = spark.read.parquet('companies.parquet')
verified_df = parsed_df.join(company_df, parsed_df.company == compnay_df.company)
- 이러한 방법은, 기준을 충족하지 않는 행을 자동으로 필터링하는 효과가 있습니다.
Complex rule validation
- 복잡한 규칙 유효성 검사는 Spark 구성요소를 사용하여 논리를 검사하는 아이디어입니다.
- Calculations
- 불규칙한 데이터 세트의 열 수를 확인하기 위한 계산
- 외부 소스에 대해서 유효성 검사 적 ( 웹서비스, 로컬파일, API 호출 등 )
- 이러한 규칙은 종종 UDF로 구현되며, 논리를 한 곳으로 가져오고 DataFrame의 콘텐츠에 대해 쉽게 설명할 수 있습니다.
Analysis calculations ( UDF )
def getAvgSale(saleslist):
totalsales = 0
count = 0
for sale in saleslist:
totalsales += sale[2] + sale[3]
count += 2
return totalsales / count
udfGetAvgSale = udf(getAvgSale, DoubleType())
df = df.withColumn('avg_sale', udfGetAvgSale(df.sales_list))
이전장에서 했던 것처럼, Python을 이용해서 함수를 정의하고 이를 udf로 정의합니다.
- Spark UDF는 매우 강력하고 유연하며, 때로는 특정 유형의 데이터를 처리하는 유일한 방법입니다.
- 몇몇의 UDF는 특정 작업을 위한 내장 Spark함수로 대체 할 수 있습니다.
- 가능한 경우 인라인으로 계산을 수행합니다.
- 인라인 수학 연산을 사용하여, Spark 열을 정의한 다음 최상의 성능을 위해 최적화 할 수 있습니다.
df = df.read.csv('datafile')
df = df.withColumn('avg', (df.total_sales / df.sales_count))
df = df.withColumn('sq_ft', df.width * df.length)
df = df.withColumn('total_avg_size', udfComputeTotal(df.entries) / df.numEntries)