
Flexibly Structured Data
MongoDB는 엄격하고 알려진 구조 없이 데이터를 탐색하는 데 도움을 주는 도구입니다.
이를 이용해, 다양한 데이터를 처리하고, 분석 및 통합할 수 있습니다.
또한 요구 사항이 발전함에 따라 문제를 계속 개선하고 수정할 수 있습니다.
오늘날 웹상의 대부분의 애플리케이션 프로그래밍 인터페이스는 특정 데이터 형식을 노출하는데, 이 형식으로 데이터를 표현할 수 있으면 MongoDB를 사용가능합니다.
JavaScript Object Notation ( JSON )
- JSON은 웹서비스와 클라이언트 코드가 데이터를 전달하는 일반적인 방법입니다.
- JSON은 MongoDB 데이터 형식의 기초입니다.
- JSON은 두가지 컬렉션 구조가 존재합니다.
- Objects {}
- Arrays []
JSON <> Python
- JSON 객체는 Python에 있는 dictionary 형식과 같습니다.
- Array또한, Python Array와 동일합니다.
- strings, numbers, boolean, null 등이 파이썬에서도 매핑됩니다.
JSON <> Python <> MongoDB
| MongoDB | JSON | Python |
|---|---|---|
| Databases | Objects | Dictionaries |
| > Collections | Arrays | Lists |
| » Documents | Objects | Dictionaries |
| »> Subdocuments | Objects | Dictionaries |
| »> Values | Value types | Value types + datetim, regex |
Example) The Nobel Prize API data(base)
import requests
from pymongo import MongoClient
client = MongoClinet()
db = clinet['nobel']
for collection_name in ['prizes', 'laureates']:
response = requests.get("http://api.nobelprize.org/v1/{}.json".format(collection_name[:-1]))
documents = response.json()[collection_name]
db[collection_name].insert_many(documents)
pymongo 라이브러리를 통해, 파이썬으로 MongoDB를 호출할 수 있습니다.
이후 client를 선언하고, 데이터베이스와 연결합니다.
반복문을 통해서, 원하는 데이터를 수집합니다.
컬렉션에서 문서를 계산하는 방법 & 문서를 찾는 방법
먼저 클라이언트 개체에서 데이터 베이스 및 컬렉션 액세스 합니다.
- Using []
db = client["nobel"]
prizes_collection = db["prizes"]
- Using .
db = client.nobel
prizes_collection = db["prizes"]
두가지 방법중 익숙한 방법을 사용하면 됩니다.
Count documents
문서의 수를 계산하기 위해서는 count_documents 를 사용합니다.
filter = {}
n_prizes = db.prizes.count_documents(filter)
n_laureates = db.laureates.count_documents(filter)
필터를 통해서, 필터링 합니다.
doc = db.prizes.find_one(filter)
이후, 문서를 가져와 API가 제공하는 원시 JSON 데이터의 스키마를 유추합니다.
문서 찾기
filter_doc = {
'born' : '1845-03-27',
'diedCountry' : 'Germany',
'gender' : 'male',
'surname' : 'Rontgen'
}
db.laureates.count_documents(filter_doc)
문서를 찾기 위해서는, 찾고자하는 문서의 정보를 표현합니다.
이후, count_documents 를 통해, 해당하는 문서를 찾습니다.
Simple filters
db.laureates.count_documents({'gender':'female'})
위와 같이, 단일 필터를 수행할 수도 있습니다.
Composing filters
filter_doc = {'gender':'female',
'diedCountry' : 'France',
'bornCity' : 'Warsaw'}
db.laureates.count_documents(filter_doc)
데이터에 대한 내용을 보고 싶으면, find_one 을 통해 정보를 가져옵니다. ( 모두 가져오려면, find )
db.laureates.find_one(filter_doc)
Query operators
db.laureates.count_documents({
'diedCountry' : {
'$in' : ['France', 'USA']
}
})
db.laureates.count_documents({
'diedCountry' : {
'$ne' :'France'
}
})
위와같이, 필드가 ‘France’ 이거나 ‘USA’ 인 문서를 찾을 수 있습니다.
MongoDB 연산자에는 달러기호 접두사가 존재합니다.
또한, 특정 문자열과 같지 않은 문서를 찾으려면, ‘$ne’ 를 이용합니다.
- $gt : >
- $gte : >=
- $lt : <
- $lte : <=
이외에도 위와 같은 연산자를 사용할 수 있습니다.
db.laureates.count_documents({
'diedCountry': {
'$gt' : 'Belgium',
'$lte' : 'USA'
}
})
위와 같이, 문자열을 입력했을 경우, 숫자가 아닌 알파벳 순서를 의미합니다.
A functional density
db.laureates.find_one({
"firstname": "Walter",
'surname': "Kohn"
})
위는 find_one 를 이용해서 검색하는 방법입니다.
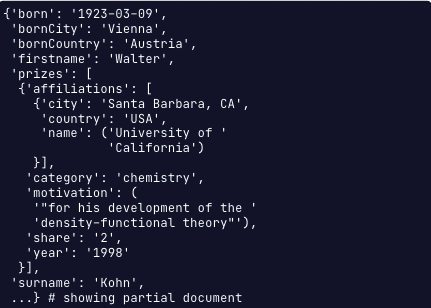
db.laureates.count_documents({
"prizes.affiliations.name" : ("University of California")
})
위의 아웃풋에서, affiliations.name 에 해당하는 결과값을 가진 문서의 갯수를 찾는 방법입니다.
점표기법을 통해서, 문서전체에서 이에 해당하는 문서가 몇개인지 쉽게 찾을 수 있습니다.
Schema
MongoDB를 사용하면, 컬렉션에 대한 스키마를 지정하고 적용할 수 있지만, 필수는 아닙니다.
예를들어, 필드는, 컬렉션의 문서에서 동일한 유형의 값을 가질 필요가 없습니다.
db.laureates.find_one({'surname': 'Naipaul'})
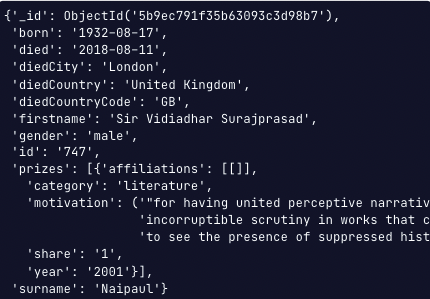
위와 같이, pirzes 부분이 비어있을 수 있습니다.
루트 수준 필드라도 모든 문서에 있을 필요는 없습니다. 위의 출력의 예시에서는 bornCountry가 존재하지 않습니다.
db.laureates.count_documents({"bornCountry": {"$exists": True}})
“$exists” 연산자를 사용하면, 필드의 존재 여부를 쿼리할 수 있습니다.
db.laureates.count_documents({})
[output]
922
db.laureates.count_documents({'prizes': {"$exists": True}})
[output]
922
db.laureates.count_documents({'prizes.0': {"$exists": True}})
[output]
922
db.laureates.count_documents({'prizes.1': {"$exists": True}})
[output]
6
위와같이, .0 .1 등으로, 해당하는 숫자를 알 수 있습니다.
Using .distinct()
db.laureates.distinct("gender")
[output]
['male', 'female', 'org']
distinct를 이용해서, 유니크한 값을 찾을 수 있습니다.
집계는 컬렉션 전체에서 데이터를 처리하고, 계산된 결과를 생성합니다.
Index
MongoDB가 유지관리할 필드에 Index를 등록할 수 있는데, 이를 이용해서, 효율적인 쿼리 및 집계를 보장합니다.
하지만, 많은 데이터로 작업하지 않는 경우, 일반적으로 Index가 필요하지 않습니다. ( 사용하는 컬렉션이 메모리에 남기때문에 - 메가바이트 미만, 천개이하의 문서 )
.distinct() with dot notation
db.laureates.find_one({"prizes.2": {"$exists": True}})
점표기법을 사용하면, 문서의 루트 수준보다 깊이 포함된 필드를 지정할 수 있습니다.
db.laureates.find_one({"prizes.share": "4"})
위와 같이, 점 표기법으로, 찾는 방법을 사용합니다.
db.laureates.distinct("prizes.category")
[output]
['physics', 'chemistry', 'peace',
'medicine','literature', 'econmics']
list(db.laureates.find({"prizes.share": "4"}))
위와같이 두개의 함수를 이용해서 사용해서 합치는 방법도 있지만, 이를 하나의 함수로 사용하면 더 깔금하게 사용가능합니다.
db.laureates.distinct("prizes.category", {"prizes.share": "4"})
[output]
['physics', 'chemistry', 'medicine']
위와 같이, distinct함수에 인자를 넣어주면, 해당하는 카테고리만 출력할 수 있습니다.
Example) prize categories with multi-winners
db.laureates.count_documents({"prizes.1": {"$exists": True}})
두 개 이상의 prizes를 수상한 수상자가 있는 상의 카테고리 수를 찾는 코드입니다.
db.laureates.distinct("prizes.category", {"prizes.1": {"$exists": True}})
[output]
['chemistry', 'physics', 'peace']
distinct를 이용해서, 상을 2번이상 받은 카테고리를 출력하는 코드입니다.
Array fields and equality, simplified
{"nicknames" : ["Johnny", "JSwitch", "JB", "Tc Johnny", "Bardy"]}
db.laureates.find({"nicknames": "JB"})
JB라는 별명을 가진 모든 수상자를 찾는다고 가정할 때, 위와 같이, 필터 문서를 사용할 수 있습니다.
필터는 “nicknames” 배열 필드에 “JB” 와 동일한 값이 하나 이상 있는 모든 문서와 일치시킵니다.
Array fields and operators
db.laureates.count_documents({"prizes.category": "physics"})
[output]
206
db.laureates.count_documents({"prizes.category": {"$ne": "physics"}})
[output]
716
동일하게, “$ne”를 통해서, physics를 수상하지 않은 문서를 찾을 수도 있습니다.
db.laureates.count_documents({"prizes.category":
{"$in" : ["physics", "chemistry", "medicine"]}})
[output]
596
db.laureates.count_documents({"prizes.category":
{"$nin" : ["physics", "chemistry", "medicine"]}})
[output]
326
또한, not-in 연산자를 사용하여, 해당 범주에 속하지 않는 적어도 하나의 상을 가진 수상자를 찾습니다.
Enter $elemMatch
상품 하위 문서 내에서, 둘 이상의 필드를 필터링 하기 위해서는, $elemMatch를 사용합니다.
db.laureates.count_documents({
"prizes": {"elemMatch":{"category": "physics", "share":"1"}}})
elemMatch 연산자를 사용하면, 해당 조건 모두 해당하는 문서를 찾습니다.
Finding a substring with $regex
db.laureates.find_one({"firstname": "Marie"})
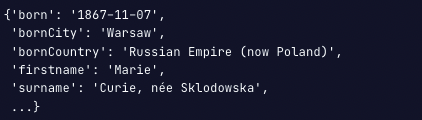
위와 같은 출력에서, bornCountry 속 Poland 를 가지는 문서를 출력하고 싶을때, regex를 사용합니다.
db.laureates.distinct("bornCountry", {"bornCountry": {"$regex": "Poland"}})
위와 같이, 폴란드 문자열에 정규식 연산자를 사용합니다.
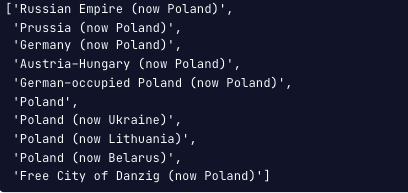
위와 같이, 폴란드를 포함한 문서를 출력할 수 있습니다.
Flag options for regular expressions
db.laureates.distinct("bornCountry", {"bornCountry": {"$regex": "poland", "$options":"i"}})
다음과 같이 option을 추가하는 방법도 있습니다. ( 옵션 i는 대소문자를 구분하지 않는 방법입니다. )
from bson.regex import Regex
db.laureates.distinct("bornCountry", {"bornCountry": Regex("poland", i)})
MongoDB는 또한 컴파일된 정규식 개체를 지원합니다.
Pymongo 드라이버에는 bson Regex 클래스가 있는 패키지가 포함되어 있으며, 이 패키지는 표시된 대로 가져와서 사용할 수 있습니다.
import re
db.laureates.distinct("bornCountry", {"bornCountry": re.compile("poland")})
Python 정규식을 사용할 수도 있습니다. 하지만, bson Regex 클래스를 사용하는 것이 MongoDB에 더 적합합니다.
Begining and ending ( and escaping )
from bson.regex import Regex
db.laureates.distinct("bornCountry", {"bornCountry": Regex("^Poland")})
['output']
['Poland',
'Poland (now Ukraine)',
...
필드 값의 시작 부분과 일치시키려면, 캐럿 문자(^)를 사용합니다. - regex에 전달하는 문자열의 시작 부분에 고정시킵니다.
db.laureates.distinct("bornCountry", {"bornCountry": Regex("^Poland \(now")})
[output]
['Poland (now Ukraine)',
'Poland (now Lithuania)',
...
문자를 이스케이프 하려면, 백슬래시를 이용합니다.
db.laureates.distinct("bornCountry", {"bornCountry": Regex("now Poland\)$")})
[output]
['Russian Empire (now Poland)',
'Prussia (now Poland)',
...
필드 값의 끝을 일치 시키려면 달러 기호를 사용합니다.
Projection 이란?
Projection이라는 용어는 다차원 데이터를 줄이는 방법에 관한 것입니다.
데이터 테이블 열을 선택하는 것인데, MongoDB에서는 하위 구조를 선택하는 것입니다.
Projection in MongoDB
docs = db.laureates.find(filter={}, projection={"prizes.affilations": 1,"_id": 0})
type(docs)
<pymongo.cursor,Cursor as 0x10d6e69e8>
MongoDB에서는 문서 필드를 지정하여 예측 값들을 가져옵니다.
컬렉션의 find 메서드에 대한 두번째 인수로 사전을 전달하여, 이를 수행할 수 있습니다.
투영에 포함하려는 각 필드에 대해 값 1을 지정합니다. 포함하지 않은 필드는 투영에 포함되지 않습니다.
단 “_id” 필드는 예외사항으로, 기본적으로 항상 투영에 포함됩니다. 이를 생략하려면 0을 할당해야 합니다.
해당 리턴값은, 데이터 자체가아니라 커서로, 한번에 하나씩 문자를 가져올 수 있는 이터러블 형태입니다.
list(docs)[:3]
우리는 이렇게 얻은 이터러블에 List를 취함으로써, 데이터를 관리할 수 있습니다.
Missing fields
만약 find한 내용이 존재하지 않는 데이터일 경우, MongoDB는 오류를 발생시키는 대신, 해당 필드가 없는 문서를 반환합니다.
Simple aggregation
docs = db.laureates.find({}, ["prizes"])
n_prizes = 0
for doc in docs:
n_prizes += len(doc["prizes"])
print(n_prizes)
[output]
942
예를 들어, 수여된 총 상금 메달 수를 계산한다고 할 때, 모든 수상자에 대한 상품 배열의 총 요소 수를 얻습니다.
위와 같이, prizes만 투영해, 매우 큰 컬렉션의 성능에 확실히 영향을 줄 수 있습니다.
Sorting post-query with Python
Python만으로 검색된 문서 목록을 정렬하는 방법은 유용합니다.
이 방법은, 특히 작은 데이터 세트의 경우 성능이 뛰어날 수 있습니다.
이는 데이터를 로컬 캐시에 저장하고, 다양한 작업을 시도할 수 있습니다.
docs = list(db.prizes.find({"category": "physics"}, ["year"]))
docs = sorted(docs, key=itemgetter("year"))
print(docs["year"] for doc in docs[:5])
파이썬 sorted함수에 key로 itemgetter(“year”) 를 통해, 정렬하면, year순으로 정렬된 값을 얻을 수 있습니다.
Sorting in-query with MongoDB
cursor = db.prizes.find({"category": "physics"}, ["year"], sort=[("year",1)])
print([doc["year"] for doc in cursor][:5])
'''
역순의 값을 얻고 싶으면, sort에 -1를 사용합니다..
cursor = db.prizes.find({"category": "physics"}, ["year"], sort=[("year",-1)])
'''
Mongo에 서버의 필드 값으로 간단한 정렬을 수행하고, 결과를 정렬된 순서로 요청할 수도 있습니다.
Primary and secondary sorting
for doc in db.prizes.find({"year": {"$gt": "1966", "$lt" : "1970"}}, ["category", "year"],
sort=[("year", 1), ("category",-1)])
print("{year} {category}".format(**doc))
정렬을 위해, 두개의 키를 이용하는 방법은, sort에 2개의 카테고리를 입력하면 됩니다.
Sorting with pymongo versus MongoDB shell
MongoDB용 CLI shell은 JavaScript를 이용합니다.
- MongoDB shell
- {“year”: 1, “category”:-1}
- javascript 개체는 입력된 키 순서로 유지됩니다.
- Python
- Python 3.6 이하의 버전에서는, 개체 순서를 유지한다는 보장이 없습니다.
- 이것이 pymongo에 튜플 목록이 필요한 이유입니다.
Index
MongoDB의 인덱스는 책의 인덱스와 같습니다.
MongoDB를 사용하면 각 컬렉션을 책으로, 각 문서를 페이지로, 각 필드를 콘텐츠 유형으로 생각하면 됩니다.
인덱스를 통해, 해당 필드의 값을 사용하여 필드를 인덱싱 할 수 있습니다.
When to use indexes?
- 하나 또는 몇 개의 문서만 돌려받을 것으로 예상되는 경우
- 문서가 매우 크거나 컬렉션이 매우 큰 경우
특정 쿼리를 사용하여 상품 문서를 수집하는데 걸리는 시간
%%timeit
docs = list(db.prizes.find({"year":"1901"}))
0.5 밀리초
%%timeit
docs = list(db.prizes.find({}, sort=[("year",1)]))
5 밀리초
Adding a single-field index
create_index 메소드를 사용하여 수상 연도에 대한 오름차순 인덱스를 생성하는 방법
db.prizes.create_index([("year",1)])
이를 생성하고, 위에서 했던 시간 측정을 할경우, 쿼리 성능이 향상됨을 알 수 있습니다.
%%timeit
docs = list(db.prizes.find({"year":"1901"}))
0.38 밀리초
%%timeit
docs = list(db.prizes.find({}, sort=[("year",1)]))
4 밀리초
단일쿼리에서 30% 복수쿼리에서 20%의 성능향상을 가져옵니다.
Adding a compound(multiple-field) index
db.prizes.create_index([("category", 1), ("year", 1)])
오름차순 범주에 대한 복합 인덱스를 만든 다음 오름차순 연도를 만듭니다.
따라서, Mongo는 각 범주에 대해 연도를 오름차순으로 인덱스를 유지합니다.
list(db.prizes.find({"category": "economics"}, {"year": 1, "_id":0}))
Mongo는 쿼리를 실행하기 위해 컬렉션 자체를 검사할 필요없이, 인덱스에 의해 커버됩니다.
속도향상 측면에서는 약간의 향상을 얻지만, 컬렉션보다 훨씬 적은 공간을 차지합니다.
일반적으로 쿼리를 포함하는 인덱스를 정의하면 성능이 크게 향상될 수 있습니다.
쿼리 성능 문제를 해결하는 몇가지 방법
- index_information()
- 컬렉션에 어떤 인덱스가 있는지 확인하는데 도움이 됩니다.
- explain()
- MongoDB는 주어진 쿼리가 실행되는 방법을 자세히 설명하는 쿼리 계획의 출력을 제공합니다.
Example) Limiting our exploration
for doc in db.prizes.find({}, ["laureates.share"]):
share_is_three = [laureate['share']==3 for laureate in doc["laureates"]]
첫번째, 모든 수상에 대해 share가 3인 경우를 확인
for doc in db.prizes.find({"laureates.share": "3"}):
print("{year} {category}".format(**doc))
이를 통해 3으로 분할된 수상 정보를 인쇄할 수 있습니다. 이렇게 출력할 경우, 수많은 출력을 가지게됩니다.
for doc in db.prizes.find({"laureates.share": "3"}, limit=3):
print("{year} {category}".format(**doc))
위처럼, 수많은 출력을 원치 않을 경우, limit 옵션을 통해, 출력하고 싶은 양을 조절할 수 있습니다.
for doc in db.prizes.find({"laureates.share": "3"}, limit=3, skip=6):
print("{year} {category}".format(**doc))
또한, skip을 통해, 처음부터 skip으로 설정한 숫자만큼 건너뛰고 데이터를 가져올 수 있습니다.
for doc in db.prizes.find({"laureates.share": "3"}).limit(3):
print("{year} {category}".format(**doc))
위처럼, find에 인자로 limit를 주지않고, 커서에 연결해서 제한을 줄 수 있습니다.
for doc in db.prizes.find({"laureates.share": "3"}).sort([("year",1)]).skip(3).limit(3):
print("{year} {category}".format(**doc))
위와 같이, sort, skip, limit 모두 커서에 연결할 수 있습니다.
단, find_one에 경우 커서에 연결할 수 없습니다.
Simple sorts of sort
cursor1 = (db.prizes.find({"laureates.share":"3"}).skip(3).limit(3).sort([("year",1)]))
cursor2 = (db.prizes.find({"laureates.share":"3"}).skip(3).limit(3).sort("year",1))
cursor3 = (db.prizes.find({"laureates.share":"3"}).skip(3).limit(3).sort("year"))
위의 3줄 모두 동일하게 작동하는 코드입니다.
Queries have implicit stages
cursor = db.laureates.find(filter={"bornCountry": "USA"}, projection={"prizes.year":1},
limit=3)
위의 코드는 단계별로 진행됩니다.
- 필터
- 출력을 위해 다운스트림에 필요한 필드를 투영
- 검색되는 문서의 수를 제한
cursor = db.laureates.aggregate([
{"$match": {"bornCountry":"USA"}},
{"$project": {"prizes.year": 1}},
{"$limit": 3}
])
위의 코드와 동일한 방식으로 작동하는 코드입니다.
Adding sort and skip stages
from collections import OrderedDict
list(db.laureates.aggregate([
{"$match": {"bornCountry":"USA"}},
{"$project": {"prizes.year": 1, "_id":0}},
{"$sort": OrderedDict([("prizes.year", 1)])},
{"$skip": 1},
{"$limit": 3},
]))
정렬 및 스킵또한, 파이프라인 단계로 사용할 수 있습니다.
단 정렬 단계에서, pymongo는 OrderDict클래스를 이용해야 합니다.
OrderDict 클래스는 입력된 순서대로 필드 방향 쌍을 생성합니다.
But can I count?
list(db.laureates.aggregate([
{"$match": {"bornCountry":"USA"}},
{"$count": "n_USA-born-laureates"}
]))
[output]
[{'n_USA-born-laureates': 269}]
count 단계를 사용하여 이전 단계에서 전달된 문서의 수를 계산할 수 있습니다.
해당 집계 컬렉션은, count_documents 메서드와 동일합니다.
Field paths
집계 단계는 필드 경로가 표함된 표현식을 사용할 수 있습니다.
- 표현 방식
- {field1:
, ...}
- {field1:
db.laureates.aggregate([
{"$project": {"prizes.share": 1}}
]).next()
[output]
{'_id': ObjectId('5bd3a610053b1704219e19d4'),
'prizes': [{'share': '1'}]}
여기에서 표현 개체를 프로젝트 단계에 전달합니다.
개체에 ‘prizes.share’라는 하나의 키가 있으면 표현식 값은 1 입니다.
db.laureates.aggregate([
{"$project": {"n_prizes": {"$size": "$prizes"}}}
]).next()
대조적으로, 위의 코드는 “n_prizes”라고 하는 필드에 투영합니다.
- {“$size”: “$prizes”} 이라는 표현식의 값을 사용
- field path : $prizes
파이프라인에 의해 해당 단계에서 처리된 각 문서에 대한 prizes 필드의 값을 취합니다.
이를 이용해서, 집계 중 새 필드를 만들거나, 이전 필드를 덮어 쓸 수 있습니다.
Operator expression
db.laureates.aggregate([
{"$project": {"n_prizes": {"$size":"$prizes"}}}
]).next()
[output]
{'_id': ObjectId('5bd3a610053b1704219e19d4'),
'n_prizes': 1}
여기서 또 다른 새로운 개념은 연산자를 함수로 취급하는 연산자 표현식입니다.
표현식은 하나 이상의 인수에 연산자를 적용하고, 값을 반환합니다.
- 표현식 : {“$size”: “$prizes”}
- filed path : $prizes
따라서 표현식 개체는 n-prizes 필드를 할당합니다. (편의상 하나의 매개변수만 있어서 대괄호 생략)
db.laureates.aggregate([{"$project": {"solo_winner": {"$in":["1", "$prizes.share"]}}}]).next()
[output]
{'_id': ObjectId('5bd3a610053b1704219e19d4'),
'solo_winner': True}
쿼리 필터에서 사용할 수 있는 많은 연산자에는 집계에 해당하는 연산자가 있습니다.
Implementing .distinct()
list_1 = db.laureates.distinct("bornCountry")
list_2 = [doc["_id"] for doc in db.laureates.aggregate([{"$group": {"_id": "$bornCountry"}}])]
set(list_2) - {None} == set(list_1)
여기서는 $group를 사용합니다. group은 _id 필드를 매핑해야 하는 표현식 개체를 사용합니다.
모든 MongoDB 문서의 경우 _id 필드는 고유 해야합니다.
그룹 단계에 선행하는 매치 단계가 없기 때문에 모든 BornCountry 값이 캡쳐됩니다.
여기에는 필드가 문서에 없을 때 발생하는 값인 None 이 포함됩니다.
How many prizes have been awarded in total?
list(db.laureates.aggregate([
{"$project": {"n_prizes": {"$size": "$prizes"}}},
{"$group": {"_id": None, "n_prizes_total": {"$sum": "$n_prizes"}}}
]))
[output]
[{'_id': None,'n_prizes_total': 941}]
project 단계와 group 단계의 결합입니다.
underscore-id는 모든 문서에 대해 None으로 매핑됩니다.
즉, 그룹 단계에서 하나의 문서만 나타납니다.
이 문서 하나는 새 필드인 n_prizes_total을 연산자 표현식에 매핑합니다.
여기서 $sum 은, 그룹 단계에서 누산기 역할을 합니다.
Sizing and summing
list(db.prizes.aggregate([
{"$project": {"n_laureates": {"$size": "$laureates"}, "category": 1}},
{"$group": {"_id":"$category", "n_laureates": {"$sum" : "$n_laureates"}}},
{"$sort": {"n_laureates": -1}},
]))
[output]
[{'_id': 'medicine','n_laureates': 216},
{'_id': 'physics','n_laureates': 210},
{'_id': 'chemistry','n_laureates': 181},
{'_id': 'peace','n_laureates': 133},
{'_id': 'literature','n_laureates': 114},
{'_id': 'economics','n_laureates': 81}]
각 분야별 수상자 수를 원한다고 가정하면 이를 수행하는 한 가지 방법은 $size 연산자를 사용하여, 필드를 투영하는 것입니다.
이후, 상 범주별로, 그룹화 하는 단계를 추가하여 범주당 수상자 수를 생성할 수 있습니다.
이후, n_laureates 필드를 각 범주에 대한 n_laureates 값의 합으로 재설정합니다.
이후 내림차순으로 정리합니다.
How to $unwind
수상자 배열의 개별 요소를 어떻게 사용할까요?
list(db.prizes.aggreagte([
{"$unwind": "$laureates"},
{"$project": {"_id":0, "year":1, "category":1, "laureates.surname":1, "laureates.share":1}},
{"$limit":3}
]))
[output]
[{'year': '2018',
'category': 'physics','laureates': {'surname': 'Ashkin','share': '2'}},
{'year': '2018',
'category': 'physics','laureates': {'surname': 'Mourou','share': '4'}},
{'year': '2018',
'category': 'physics','laureates': {'surname': 'Strickland','share': '4'}}]
이를 수행하기 위해서는 $unwind를 사용합니다.
이는 배열 요소당 하나의 파이프라인 문서를 출력합니다.
여기에서 우리는 세 개의 문서에 걸쳐 수상자 필드를 풀었습니다.
Renormalization, anyone?
unwind 이후 다음 단계를 사용하여, 데이터를 재압축합니다.
데이터를 정규화하고 각 상품의 수상자 ID만 추적하려면?
결국 우리는 수상자 컬렉션에서 더많은 정보를 가져올 수 있습니다.
list(db.prizes.aggregate([
{'$unwind': "$laureates"},
{"$project": {"year":1, "country": 1, "laureates.id":1}},
{"$group": {"_id": {"$concat": ["$cateogry", ":", "$year"]}, "laureate_ids":{"$addToSet": "$laureates.id"}}}
{"$limit": 5}
]))
[output]
[{'_id': 'medicine:1901','laureate_ids': ['293']},
{'_id': 'peace:1902','laureate_ids': ['465','464']},
{'_id': 'physics:1902','laureate_ids': ['3','2']},
{'_id': 'peace:1903','laureate_ids': ['466']},
{'_id': 'medicine:1903','laureate_ids': ['295']}]
여기에서 각 수상별 수상자의 ID목록을 얻습니다.
수상자 배열을 해체한 후 연도, 범주 및 수상자 ID를 예측합니다.
연도와 카테고리는 함께 상을 식별합니다.
따라서, 이러한 값을 연결하여 그룹화 할 수 있습니다.
그룹 단계에서 addToSet 연산자를 사용하여 각 상품에 대한 수상자 ID를 수집합니다.
$unwind and count ‘em, one by one
list(db.prizes.aggregate([
{"$project": {"n_laureates" : {"$size": "$laureates"}, "category": 1}},
{"$group": {"_id":"$category", "n_laureates": {"$sum": "$n_laureates"}}},
{"$sort": {"n_laureates": -1}},
]))
unwind 연산자를 이해하는 방법은 다음과 같습니다.
이전에는 크기 연산자를 사용하여 상별 수상자 수를 예측했습니다.
이 프로젝션은 그룹 단계에 입력되어 카테고리별 카운트를 출력합니다.
list(db.prizes.aggregate([
{"$unwind": "$laureates"}
{"$group": {"_id":"$category", "n_laureates": {"$sum": 1}}},
{"$sort": {"n_laureates": -1}},
]))
크기를 예측하고, 합산하는 대신 문서를 풀고 계산할 수 있습니다.
여기에서 그룹 단계는 해제 단계에서 제공한 범주당 문서를 계산합니다.
$lookup
이 단계에서는 왼쪽 외부 조인이라고 하는 것을 통해 다른 컬렉션에서 문서를 가져옵니다.
list(db.prizes.aggregate([
{"$match":{"category": "economics"}},
{"$unwind": "$laureates"},
{"$lookup": {"from": "laureates", "foreignField":"id",
"localField":"laureates.id", "as":"laureate_bios"}},
{"$unwind": "$laureate_bios"},
{"$group": {"_id":None, "bornCountries": {"$addToSet": "$laureate_bios.bornCountry"}}}
]))
[output]
[{'_id': None,
'bornCountries': [
'the Netherlands','British West Indies (now Saint Lucia)','Italy',
'Germany (now Poland)','Hungary','Austria','India','USA',
'Canada','British Mandate of Palestine (now Israel)',
'Norway','Russian Empire (now Russia)','Russia','Finland',
'Scotland','France','Sweden','Germany','Russian Empire (now Belarus)',
'United Kingdom','Cyprus'
]}]
경제 분야 수상자의 출생 국가를 수집합니다.
상품 컬렉션에서 먼저 수상자 배열을 해제합니다.
이제 각 파이프라인 문서에는 단일 수상자 _ID가 있습니다.
그런 다음 id 에 대해 동일한 값을 가진 문서에 대해 수상자 컬렉션을 쿼리합니다.
우리가 찾은 각각에 대해 laureate_bios라는 배열에 푸쉬합니다.
다음으로, 고유한 수상자 bornCountry 값을 수집합니다.
$addToSet 연산자에 배열이 아닌 단일 BornCountry 값을 제공하려고 합니다.
위의 과정을 쉽게하는 방법이 있습니다.
MongoDB는 정규화 된 스키마를 적용하지 않습니다. 따라서, 쿼리 단순성과 효율성을 지원하도록 컬렉션의 스키마를 조정할 수 있습니다.
bornCountries = db.laureates.distinct("bornCountry", {"prizes.category": "economist"})
수상자 컬렉션이 상품 카테고리에 대한 정보도 저장하므로, 위의 코드를 이용하면 간단합니다.
A somber $project
돌아가신 노벨상 수상자들의 생존 연수를 알고싶다고 가정하면,
docs = list(db.laureates.aggregate([
{"$match": {"died": {"$gt": "1700"}, "born": {"$gt": "1700"}}}
{"project": {"died": {"$dateFromString": {"dateString": "$died"}},
"born": {"$dateFromString": {"dateString":"$born"}}}}
]))
born 및 died 필드를 투영하여 이를 계산하는 파이프라인을 만들 수 있습니다.
MongoDB에는 dateFromString이라는 연산자를 사용하면, 계산할 수 있습니다.
$match를 통해, 비정상적인 날짜를 제거하고, 1700년 이상의 데이터만 쿼리합니다.
하지만 이렇게 할 경우, 에러가 발생하는데, 일부 수상자는 출생년도만 기록되어 있기 때문입니다.
split and cond itionally correct
docs = db.laureates.aggregate([
{"$match": {"died": {"$gt": "1700"}, "born": {"$gt": "1700"}}},
{"$addFields": {"bornArray": {"$split": ["$born", "-"]},
"diedArray": {"$split": ["$died", "-"]}}},
{"$addFields": {"born": {"$cond": [
{"$in": ["00", "$bornArray"]},
{"$concat": [{"$arrayElemAt": ["$bornArray", 0]}, "-01-01"]}
]}}},
{"$project": {"died": {"$dateFromString": {"dateString": "$died"}},
"born": {"$dateFromString": {"dateString": "$born"}},
"_id": 0}}
])
addFields 단계를 통해, 날짜 문자열의 하이폰으로 분할된 새 배열 필드를 제공합니다. 이것을 통해, 년,월,일을 요소로 갖는 배열을 가지게됩니다.
여기서 addFields를 쓰는이유는, 파이프라인에 전달하려는 다른 모든 필드를 지정할 필요가 없어서 입니다.
이후, born 필드를 다시 작성합니다. 여기서 $cond는 삼항 연산자입니다.
만약 출생 월일이 기록되어있지 않아서, 00으로 처리되어 있다면, 이를 -01-01로 변경합니다.
이를 통해 생존연수를 계산할 수 있습니다.
A $bucket list
docs = list(db.laureates.aggregate([
...,{
{"$project": {"died": {"$dateFromString": {"dateString":"$died"}},
"born": {"$dateFromString": {"dateString": "$born"}}}},
{"$project": {"years":{"$floor": {"$divide":[
{"$subtract": ["$died","$born"]},
31557600000 # 1000 * 60 * 60 * 24 * 365.25
]}}}},
{"$bucket": {"groupBy": "$years","boundaries": list(range(30, 120, 10))}}}
]))
for doc in docs: print(doc)
[output]
{'_id': 30,'count': 1}
{'_id': 40,'count': 6}
{'_id': 50,'count': 21}
{'_id': 60,'count': 87}
이후 died 와 born에 대해 $dateFromString을 적용하고, 연산을진행 후, 투영합니다.
마지막으로 $bucket 연산자를 이용하는데, 이는 값을 일련의 경계로 나눠주는 역할을 합니다.