GCP에는 워크로드 아이덴티티라는 기능이 있습니다.
이는 GCP의 리소스를 제어하기 위한 IAM을 조금 더 편리하게 이용 할 수 있는 기능입니다.
AWS의 IAM 프로파일과 비슷하다고 느껴집니다.
요즘, 시크릿 데이터를 어떻게 처리해야 하는지 고민이 많습니다.
제일 많은 케이스가 GKE에서 IAM 서비스 계정을 사용하는 경우라고 생각이 듭니다.
apiVersion: v1
kind: Secret
metadata:
name: gcpsm-secret
labels:
type: gcpsm
type: Opaque
stringData:
secret-access-credentials: |-
{
"type": "service_account",
"project_id": "external-secrets-operator",
"private_key_id": "",
"private_key": "-----BEGIN PRIVATE KEY-----\nA key\n-----END PRIVATE KEY-----\n",
"client_email": "test-service-account@external-secrets-operator.iam.gserviceaccount.com",
"client_id": "client ID",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/test-service-account%40external-secrets-operator.iam.gserviceaccount.com"
}
위의 예시는 Secret Manager - provider Google에서 나오는 예시 코드입니다.
위와 같이, Service Account 정보를 가진 Json키 StringData로 사용하는 케이스가 많이 보입니다.
저또한 이러한 문제를 해결하고자 워크로드 아이덴티티를 사용하려고 합니다.
테스트 코드
먼저 이를 테스트 하기 위해서 테스트 코드를 준비했습니다.
사실 거창한 코드는 아니고, GCP에서 제공해주는 python pub/sub 예제입니다. 이를 쿠버네티스 job형태로 사용하기 위해 이미지화 해서 gcr.io로 전송하였습니다.
( 사전에 pub/sub을 사용하기 위해 pub/sub 셋팅을 해둔 상태입니다. )
이를 GKE에서 사용을 하니, 당연히 오류가 났습니다. 이유는 권한 문제입니다. Credentials를 따로 지정하지 않았으니 당연한 결과입니다.

이제 이 오류를 해결하고자, GCP 워크로드 아이덴티티를 적용하고자 합니다.
워크로드 아이덴티티 설정
워크로드 아이덴티티는 GKE 클러스터의 리소스가 IAM서비스 계정을 가장할 수 있게 해줍니다.
GCP Docs를 보면 자세하게 사용법을 설명하고 있습니다. 저 또한 이 문서를 보고 적용하였습니다.
먼저, 이를 적용하기 위해서는 GKE 셋팅을 해야합니다.
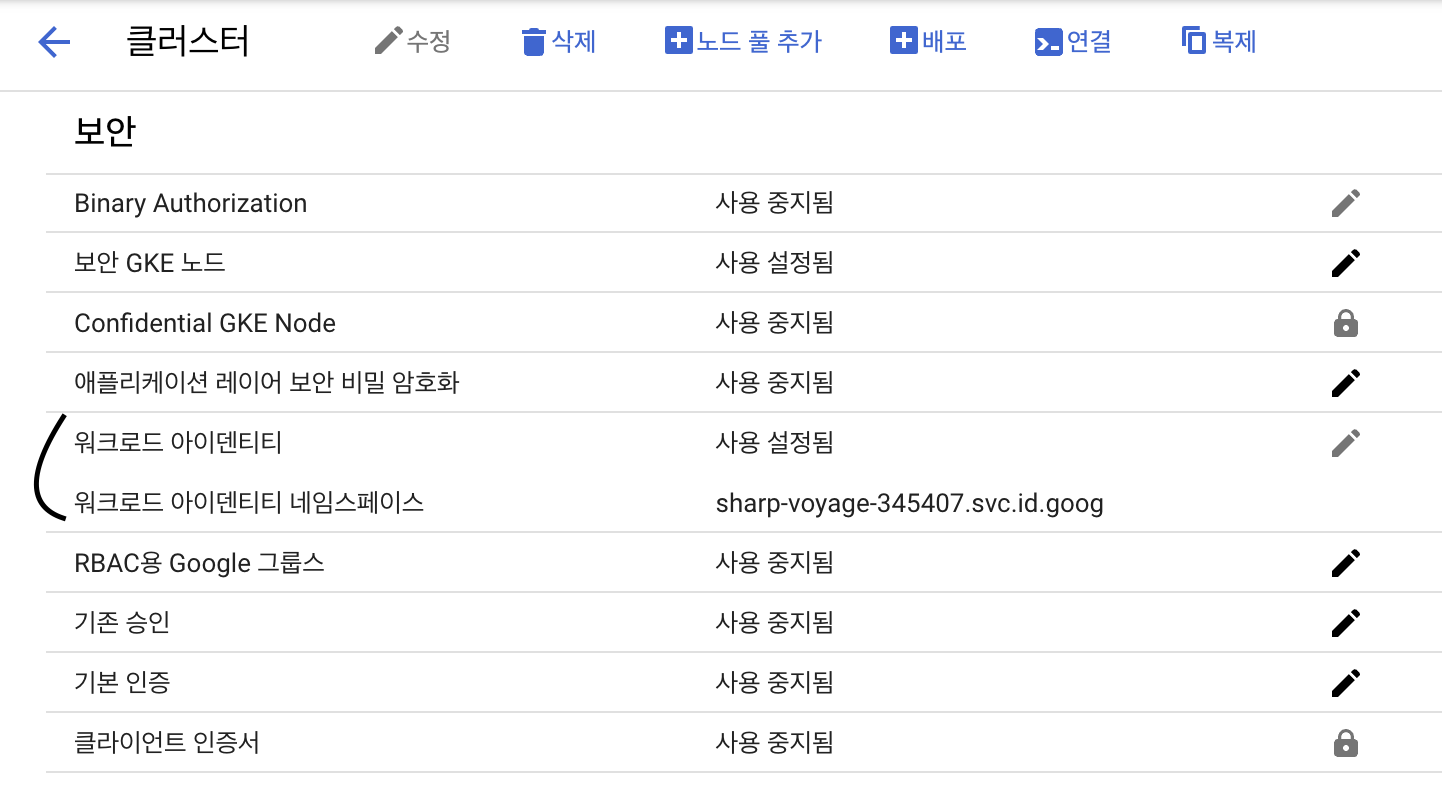
GKE 클러스터 설정을 보면, 워크로드 아이덴티티 관련 설정이 있습니다. 저는 이를 켜둔 상태라 저렇게 뜨는데, 껴둔 상태면 사용 중지됨 이라고 표기 됩니다.
이를 활성화 해줍니다.
클러스터만 한다고 끝이아니고, 워크로드 아이덴티티를 적용하고자 하는 노드풀에 대해서도 설정을 추가해야합니다.
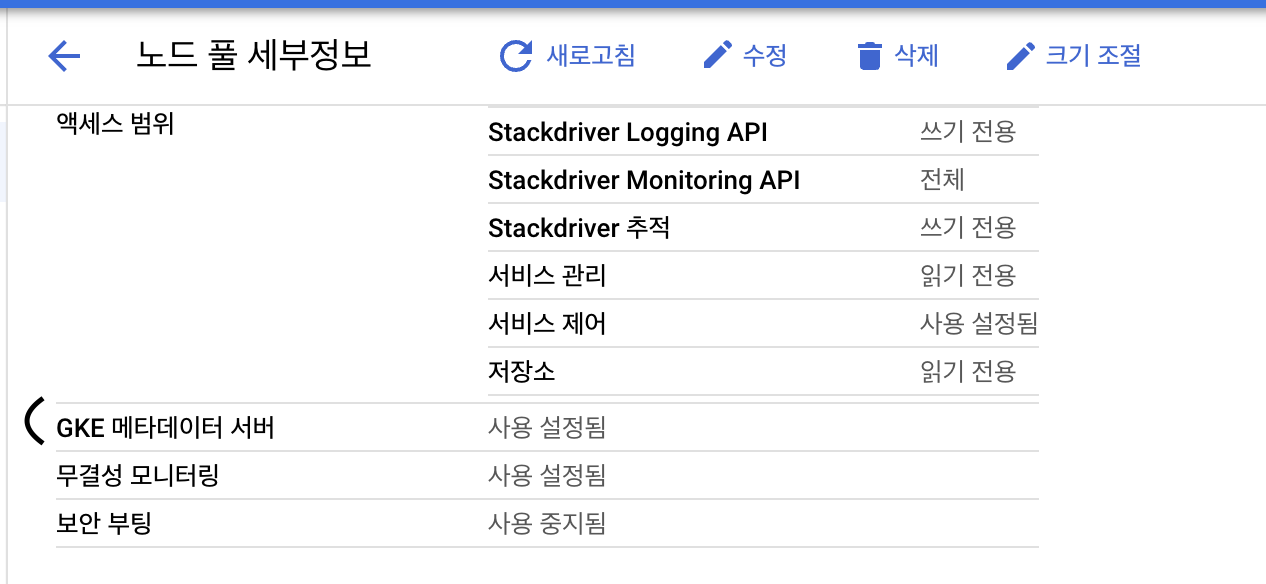
클러스터와 동일하게, GKE 메타데이터 서버 설정을 활성화 해주면 준비가 완료됩니다.
저의 경우 UI를 선호하여 UI에서 설정을 변경하였지만, gcloud를 이용한 cli를 통해 설정 변경도 가능하니 참고하세요.
gcloud container clusters update CLUSTER_NAME \
--region=COMPUTE_REGION \
--workload-pool=sharp-voyage-345407.svc.id.goog
gcloud container node-pools update NODEPOOL_NAME \
--cluster=CLUSTER_NAME \
--workload-metadata=GKE_METADATA
IAM service-account 만들기
이제 워크로드 아이덴티티를 적용할 service account를 생성해줍니다.
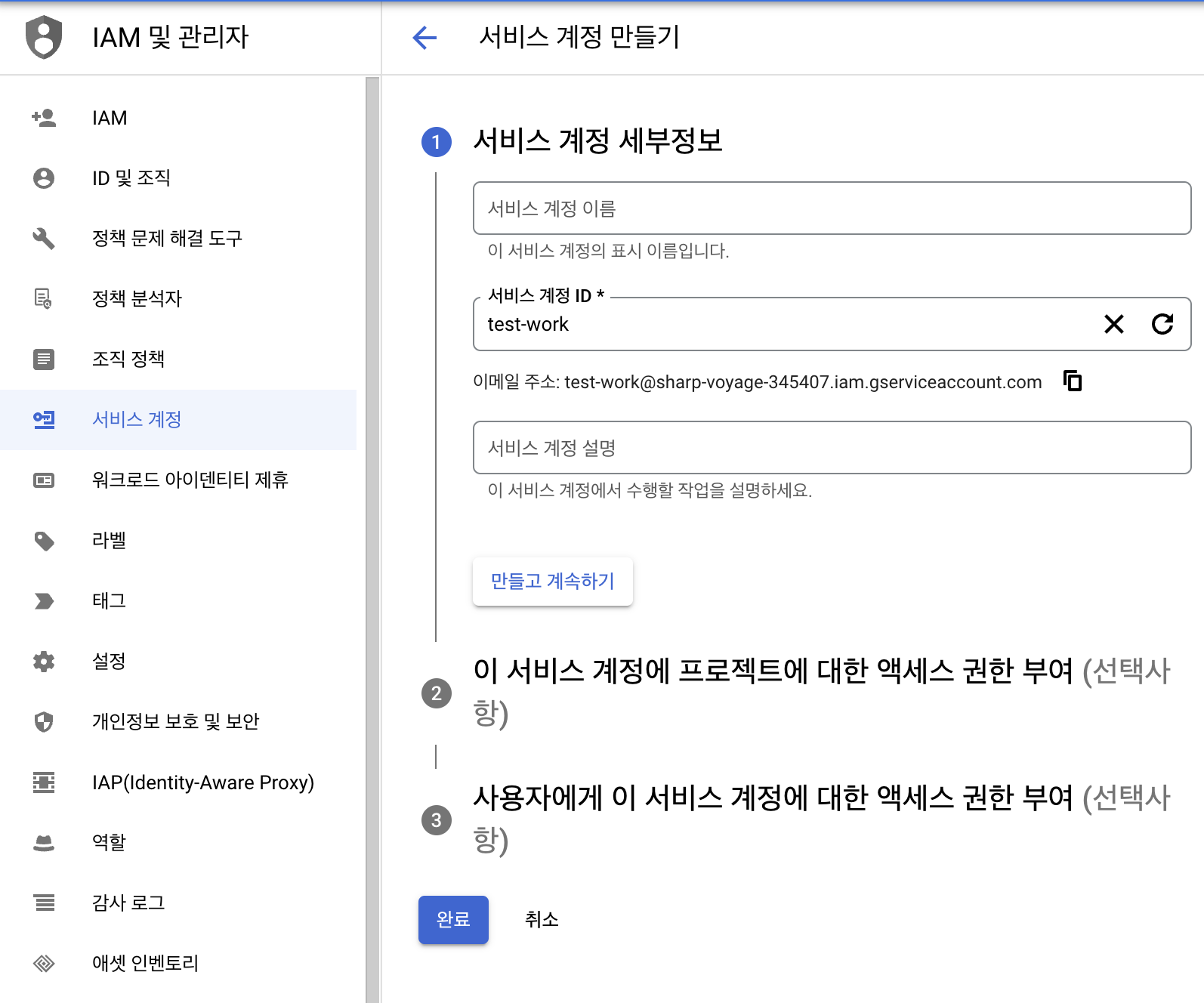
GCP IAM에서 적용하고자하는 권한을 추가하여 생성하면 완료됩니다.
여기서 이전처럼 JSON파일로 key저장 등은 안해도 workload identity를 적용할 수 있습니다.
이 또한 UI 외에도 CLI에서 생성할 수 있습니다.
GKE 적용하기
이제 GKE에 적용할 준비가 완료되었습니다.
gcloud iam service-accounts add-iam-policy-binding <GSA_NAME>@<GSA_PROJECT>.iam.gserviceaccount.com \
--role roles/iam.workloadIdentityUser \
--member "serviceAccount:<PROJECT_ID>.svc.id.goog[<NAMESPACE>/<KSA_NAME>]"
해당 servce-account를 클러스터에서 사용하겠다고 gcloud를 사용하여 활성화하는 작업입니다.
여기서 사용되는 변수 설명은 아래와 같습니다.
- GSA_NAME : 생성한 service-account 이름
- GSA_PROJECT : 생성한 service-account의 project_id
- PROJECT_ID : GKE를 사용하는 project_id (대부분의 케이스가 GSA_PROJECT와 PROJECT_ID가 동일할겁니다. 조직을 여러개로 나눠두지 않은이상?)
- NAMESPACE : Service-account를 저장할 네임스페이스
- KSA_NAME : Kubernetes 서비스 계정이름
gcloud iam service-accounts add-iam-policy-binding admin-user@sharp-voyage-345407.iam.gserviceaccount.com \
--role roles/iam.workloadIdentityUser \
--member "serviceAccount:sharp-voyage-345407.svc.id.goog[es/sa]"
저의 경우 위와같이 설정했습니다.
이제 NAMESPACE와 SERVICE-ACCOUNT를 생성해줍니다.
apiVersion: v1
kind: Namespace
metadata:
name: es
---
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
iam.gke.io/gcp-service-account: admin-user@sharp-voyage-345407.iam.gserviceaccount.com
name: sa
namespace: es
shell로 바로 입력해도 되지만, 저같은 경우 yaml파일을 사용하는 것을 선호하여 위와 같이 작성했습니다.
annotations에 설정한 값만 추가하면 큰 어려움은 없을 것이라고 판단됩니다.
Docs에서 제공하는 값은 아래와 같습니다.
$ kubectl create namespace NAMESPACE
$ kubectl create serviceaccount KSA_NAME \
--namespace NAMESPACE
$ kubectl annotate serviceaccount KSA_NAME \
--namespace NAMESPACE \
iam.gke.io/gcp-service-account=GSA_NAME@GSA_PROJECT.iam.gserviceaccount.com
이렇게 생성을 완료하면 Service Account를 적용할 준비가 완료됩니다.
리소스에 Service Account 적용하기
위에서 service-account를 생성했다고 모든 리소스에 적용되는 것은 아니고, 사용하고자 하는 값에 service-account를 적용시켜주면 됩니다. (Default service account에 적용하면 될지도???)
사용법은 사용할 리소스 spec부분에 serviceAccount를 명시해주면 됩니다.
spec:
template:
spec:
serviceAccountName: sa
nodeSelector:
iam.gke.io/gke-metadata-server-enabled: "true"
serviceAccountName: sa 처럼 사용할 service-account이름을 입력하면 설정한 값으로 사용합니다.
또한 nodeSelector를 설정했는데, 이것이, 이전에 노드풀에서 메타데이터서버를 활성화한 이유입니다.
해당 옵션이 활성화되어 있지 않으면, 워크로드 아이덴티티를 사용할 수 없습니다.
이렇게 설정하고 실행하면 이전에 실패했던 작업이 성공하는 것을 알 수 있습니다.
사용한 코드는 제 깃헙에 저장했으니 참고하세요.!