Data is valuable
- 현대 조직은, 데이터 수집이 얼마나 가치 있는지 인식하고 있습니다.
- 데이터 는 내부적으로, 점점 더 많은 사람들이 사용하고 있습니다.
- 회사 내 거의 모든 사람이 액세스 할 수 있고, 새로운 통찰력을 얻을 수 있습니다.
- 대중을 향한 측면에서, 기업들이 더 많은 데이터를 사용할 수 있도록 하고 있습니다. (공용 API 등)
Genesis of the data
- 데이터의 기원은 수집 된 스트리밍 데이터와 같은 운영 체제에 있습니다.
- 데이터는 구글 애널리틱스, 판매 플랫폼 등 사물인터넷 장치, 웹 세션 데이터 등으로 부터 생성됩니다.
이러한 데이터는 나중에 처리 할 수 있도록 어딘가에 저장해야 합니다.
오늘날 데이터의 규모와 데이터가 흐르는 속도는 우리가 “데이터 레이크” 라고 부르고 있습니다.
Operational data is stored in the landing zone
데이터 레이크는 여러 시스템으로 구성되며 일반적으로 여러 영역으로 구성됩니다.
ex) 운영 체제에서 가져온 데이터는 “LANDING” 이라고 부르는 곳에서 끝납니다.
데이터 레이크로 부터, 데이터를 가져오는 과정을 수집이라고 부릅니다.
Cleaned data prevents rework
사람들은 데이터 레이크 위에 다양한 서비스를 구축합니다. ( 예측 알고리즘, A/B 테스트 용 대시보드)
이러한 서비스 중 상당수는 데이터에 변환을 적용해야 합니다.
변환의 중복을 방지하기 위해 , Landing zone 은 청소되어 청정 구역에 저장됩니다.
The business layer provides most insights
마지막으로, 사용 사례별로이 깨끗한 데이터에 몇 가지 특수 변환이 적용됩니다.
ex) 이탈 할 가능성이 있는 고객을 예측하는 것은 일반적인 비지니스 사용 사례
정리 된, 데이터 세트로 구성된 데이터 세트를 기계학습 알고리즘에 적용합니다.
Pipelines move data from one zone to another
한 영역에서 다른 영역으로 데이터를 이동하고, 그 과정에서 데이터를 변환하기 위해 사람들은 데이터 파이프 파인을 구축합니다.
파이프 라인은 파일과 같은 외부 이벤트에 의해 트리거 될 수 있습니다. (특정 위치, 일정 시간 또는 수동으로 저장 )
일반적으로 대규모 배치로 데이터를 처리하는 파이프 라인은, 야간과 같은 일정에 따라 트리거됩니다.
이러한 파이프 라인을 추출, 변환, 로드 파이프라인 또는 ETL 파이프 라인이라고 합니다.
이들을 잘 관리하기 위해서, 좋은 도구를 이용하는 데, 그것이 Airflow입니다.
Singer’s core concepts
Singer의 목표는 데이터를 이동하는 스크립트를 작성하기 위한 오픈 소스 표준이 되는 것입니다.
데이터 추출 스크립트 및 데이터로드 스크립트는 표준 출력을 통해 표준 JSON 기반 데이터 형식을 사용하여 통신 해야 합니다.
Singer는 사양이므로 “탭” 이라고 하는 추출 스크립트 및 “타켓” 이라고하는 로딩 스크립트는 모든 프로그래밍 언어로 작성할 수 있습니다.
데이터를 한 위치에서 다른 위치로 이동하는 작은 데이터 파이프라인을 만들기 위해 쉽게 혼합 및 일치 시킬수 있습니다.
탭과 타겟은, schema, state, record 특정 스크림으로 전송 및 읽기
스트림은 메시지를 보내는 이름으로 지정된 가상 위치이며 다운 스트림 위치에서 선택 할 수 있습니다.
주제에 따라 다른 스트림을 사용하여 데이터를 분할 할 수 있습니다.
ex) 오류 메시지는 오류 스트림으로 이동하고, 다른 데이터베이스 테이블의 데이터도 다른 스트림으로 이동
Describing the data through its schema
columns = {"id","name","age","has_children"}
users = {(1, "Adrian", 32,False),
(2, "Ruanne", 28, False),
(3, "Hillary", 29, True)}
json_schema = {
"properties": {"age": {"maximum": 130,
"minimum": 1,
"type": "integer"},
"has_children": {"type": "boolean"},
"id": {"type": "integer"},
"name": {"type": "string"}},
"$id": "http://yourdomain.com/schemas/my_user_schema.json",
"$schema": "http://json-schema.org/draft-07/schema#"
}Singer 사양을 사용하면, 먼저 스키마를 지정 하여 데이터를 설명합니다.
스키마는 유효한 JSON 스키마로 제공되어야 합니다.
구조화 된 데이터에 주석을 달고 유효성을 검사 할수 있는 사양입니다. 각 속성 또는 필드의 데이터 유형을 지정합니다.
나이가 정수 값이어야 한다는 제약 혹은, 최소값, 최댓값을 부과할 수 도 있습니다.
$id, $schema를 통해 스키마를 고유하게 지정할 수 있습니다. 또한, 조작하고 사용중인 JSON 스키마 버전을 다른 사용자에게 알려줍니다. (이는 선택 옵션이지만, 프로덕션 등급의 코드에서 적극 권장됩니다. )
Describing the data through its schema
import singer
singer.write_schema(schema=json_schema,
stream_name="DC_employees",
key_properties=["id"])Singer 라이브러리에 JSON 스키마에서, 스키마 메시지를 만들도록 지시 할 수 있습니다.
Singer의 “write_schema” 함수를 호출하여, 앞서 정의한 “json_schema”를 전달합니다.
“Stream_name”을 사용하여 이 메시지가 속한 스트림의 이름을 지정합니다. ( 무엇이든 가능 )
함께 속한 데이터는 동일한 스트림으로 전송되어야 합니다.
“key_properites” 속성은 다음 목록과 같아야합니다.
- 이 스트림의 레코드에 대한 기본 키를 구성하는 문자열 (주차장에서 자동차의 데이터를 처리하는 경우, 번호판이나, 대리 키가 될 수 있습니다.)
- 기본 키가 없으면 빈 목록을 지정
Serializing JSON
import json
json.dumps(json_schema["properties"]["age"])JSON은 Singer뿐만 아니라, 다른 여러 곳에서도 일반적인 형식입니다.
Python은 JSON과 함께 작동하는 json모듈을 제공합니다.
JSON으로 직렬화 된 코드의 객체를 가져 오려면, json dump를 사용 하면 됩니다.
with open("foo.json", mode ="w") as fh:
json.dump(obj=json_schema, fp=fh)첫번쨰 코드는, 단순히 객체를 문자열로 변환하는 반면, 두번째 코드는 동일한 문자열을 파일에 씁니다.
Streaming record messages
columns = ("id", "name", "age", "has_children")
user = {(1, "Adrian", 32, False),
(2, "Ruanne", 28, False),
(3, "Hillary", 29, True)}
singer.write_record(stream_name="DC_employees",
record=dict(zip(columns, user.pop())))
-----------------------------------------------------
fixed_dict = {"type": "RECORD", "stream": "DC_employee"}
recored_msg = {**fixed_dict, "record": dict(zip(columns, users.pop()))}
print(json.dumps(record_msg))이러한 사용자를 Singer Record 메세지로 변환하기 위해 write_record함수를 호출합니다.
stream_name은 이전에 스키마 메시지에서 지정한 스트림과 일치해아합니다.
(그렇지 않으면, 레코드가 무시됩니다.)
두 개의 키가 더있는 또다른 딕셔너리는 타입와 스트림입니다.
언패킹 연산자를 사용하면, 우아하게 수행 가능.
Chaining taps and targets
#Module: my_tap.py
import singer
singer.write_schema(stream_name="foo", schema=..)
singer.write_records(steram="foo", records=..)write_schema 와 write_record를 결합하는 경우 함수를 사용하면 JSON객체를 stdout에 인쇄하는 python 모듈이 있습니다.
이러한 메시지를 구문 분석 할 수 있는 Singer 대상도 있는 경우 전체 수집 파이프 라인이 있습니다. ( write_record 가 아닌 write_records사용)
python my_tap.py | target-csv
python my_tap.py | target-csv --config userconfig.cfg파이썬 패키지 색인에서 사용할 수 있는 target_csv는 JSON라인에서 CSV파일을 만드는 것입니다.
CSV파일은 이것을 실행하는 동일한 디렉토리에 만들어집니다.
구성 파일을 제공하여 달리 구성하지 않는 명령
파이썬 인터프리터로 코드를 파싱하여 탭을 실행하는 것을 막을 수는 없습니다. 하지만 일반적으로 적절하게 패키징 된 탭과 타켓을 찾을 수 있으므로, 이와 같이 직접 호출하여 사용합니다.
Modular ingestion pipelines
my-packaged-tap | target-csv
my-packeged-tap | target-google-sheets
my-packaged-tap | target-postgresql --config conf.json
tap-custom-google-scraper | target-postgresql --config headlines.json파이썬의 csv모듈은 기능을 모듈성을 제공합니다.
각 탭 또는 대상은 한 가지를 매우 잘 수행하도록 설계되었습니다. 구성 파일을 통해서 쉽게 구성 할 수 있습니다.
표준화 된 중간 형식으로 작업하면 target-csv를 쉽게 교체할 수 있습니다. ( 구글시트 , Posrgresql 등)
즉, 많은 코드를 작성할 필요없이, 탭을 선택하고 의도 한 소스 및 대상과 일치하는 대상을 검색하면 준비가 완료됩니다.
Keeping track with state messages
Singer의 state의 메시지는, 일반적으로 상태를 추적하는데 사용되며, 이는 특정 시점에 있는 방식입니다.
이것은 일반적으로 프로세스에 대한 일종의 기억입니다.
| id | name | last_updated_on |
|---|---|---|
| 1 | Adrian | 2019-06-14T14:00:04.000+02:00 |
| 2 | Ruanne | 2019-06-16T18:33:21.000+02:00 |
| 3 | Hillary | 2019-06-14T10:05:12.000+02:00 |
매일 정오, 현지 시간에 데이터베이스에 새 레코드만 추출한다고 가정하면 가장 쉬운 방법은 가장 많이 발생하는 항목을 추적하는 것 입니다.
last_updated_on값을 입력하고, 탭을 성고적으로 실행 한 후 상태 메시지로 보냅니다. 이후 동일한 메시지를 재사용하여 이전 상태 이후에 업데이트 된 레코드만 추출합니다.
write_state함수를 사용하여 이러한 상태 메시지를 보냅니다.
singer.write_state(value={"max-last-updated-on": some_variable})값 필드는 자유 형식이며 동일한 탭에서만 사용할 수 있습니다.
What is spark
스파크는 대량의 데이터를 처리하기 위한 분석 엔진입니다.
스파크 코어는 서로 다르지만, 관련된 4개의 라이브러리를 지원합니다.
- Spark SQL
- Spark Streaming
- MLlib
- GraphX
이러한 라이브러리는 동일한 애플리케이션에서 원활하게 결합 될 수 있습니다. Spark는 랩탑 및 클라우드의 독립 실행 형을 포함하여 모든 곳에서 실행됩니다.
또한 Python과 같이 여러 프로그래밍 언어로 존재하며 종종 PySpark라고도 불립니다.
When to use Spark
스파크는 대규모 데이터를 처리하는 경우 유용한 프레임 워크로, 수십억 개의 데이터 세트 크기로 매우 잘 확장됩니다.
- 여러 시스템에서 실행을 병렬화하여 기록합니다.
- 데이터 과학자가 사용하는 노트북과 같은 대화형 분석에서도 사용 가능합니다. ( 대화식으로 데이터를 탐색하고, 데이터에 대한 가설을 신속하게 검증하고, 결과를 심층 분석합니다. )
- 기계 학습 알고리즘 및 기능 모음을 제공합니다. (기능 구축, 모델 학습, 새 데이터에 대한 기존 모델 평가 등)
스파크를 사용하면 안되는 경우
- 데이터가 거의 없을 때 : 스파크는 오버 헤드를 추가하여, 소량의 데이터에 대해 비효율적이고 느립니다.
- 간단한 필터를 적용하기 만한다면, 스파크의 풍부함이 과잉이 됩니다.
Business case: finding the perfect diaper
- 편안함과 같은 질적 측면
- 가격과 같은 양적인 측면
마케팅 부서는 이미 다음과 같은 원시 데이터 소스를 준비
- 가격 ( 매장별 해당 모델 가격 데이터 )
- 평점 ( 사용자별 해당 모델 평점 데이터 )
Starting the Spark analytics engine
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()PySpark로 데이터 세트를 로드하려면, SparkSession을 만들어야 합니다. ( 스파크 버전2 이상 )
생성 시 실행 환경이 구성됩니다.
Reading a CSV file
스파크는 CSV를 포함한 모든 종류의 파일을 읽을 수 있는 매우 편리한 방법을 제공합니다.
로컬 파일 시스템에있는 파일을 읽기 위해 해당 파일의 경로를 “spark.read.csv”를 이용합니다.
prices = spark.read.csv("mnt/data_lake/landing/prices.csv")
prices.show()이것은 전체 파일 읽기를 즉시 트리거하지 않습니다. 그러나 일부 메타 데이터와 몇 바이트에 불과하므로 작업을 매우 빠릅니다.
이 DataFrame에 대한 작업을 수행 할 때까지 실제 실행이 연기됩니다.
show()가 행동을 하게 합니다.
데이터 세트의 열을 볼 수 있지만, 헤더는 데이터의 일부로 저장됩니다.
Reading a CSV file with headers
prices = spark.read.options(header="true").csv("mnt/data_lake/landing/prices.csv")
prices.csv()위와 같이, header=“true”를 인수로 전달하면, 헤더가 전달됩니다. ( 표면적으로 보기 좋아짐 )
Automatically inferred data types
from pprint import pprint
pprint(price.dtypes)데이터 타입을 확인해보면 해당 데이터 프레임은 전부 string인 것을 알 수 있는데, Spark가 스키마를 추론하도록 할 수 있지만, 프로덕션에서는 잘못 유추 된 데이터 유형에 의존하지 않으므로, 일반적으로 스키마를 직접 정의합니다.
Enforcing a schema
독자의 스키마를 통해, 스키마를 수동으로 지정 할 수 있습니다.
매서드를 사용하고, StructType 을 전달하여, StructFields목록을 캡슐화 합니다.
schema = StructType([StructField("store", StringType(), nullable=False),
StructField("countrycode", StringType(), nullable=False),
StructField("brand", StringType(), nullable=False),
StructField("price", FloatType(), nullable=False),
StructField("currency", StringType(), nullable=True),
StructField("quantity", IntegerType(), nullable=True),
StructField("date", DateType(), nullable=False),
])
prices = spark.read.options(header="true").schema(schema).csv("mnt/data_lake/landing/prices.csv")각 StructField는 CSV 파일의 한 열, 즉 이름, 유형 및 NULL 일 수 있는지 여부를 설명
이렇게 설정하면, 나중에 변환에 유리해집니다.
Reasons to clean data
데이터 과학자는 데이터 정제에 많은 시간을 사용하는데, 작업하는 대부분의 데이터 소스는 분석 할 준비가 되어 있지 않기 떄문입니다.
- 잘못된 유형의 데이터 ( csv에서 읽을 때, 모든 것이 문자열이기에 자주 발생 )
- 잘못된 행 ( 특히 소스에서, 수동으로 입력 한 데이터를 구문 분석 할 때 엑셀 같은 일부 행에는 단순히 가짜 정보가 포함 )
- 행이 불완전 ( 때로는 하나 또는 두 개를 제외하고 행이 거의 모든 필드가 유효합니다. )
- 잘못 선택된 자리 표시 ( N/A 혹은 Unknown 등과 같은 문자열이 발생 - Null로 대체 )
Can we automate data cleanong?
데이터 과학자가 데이터를 정리하는데 너무 많은 시간을 소비한다면, 자동화하면 되지만, 자동화 할 수 없는 이유는, 데이터 정리는 종종 콘텍스트에 따라 달라지기 때문입니다.
- 모든 데이터 행이 중요한 규제 또는 엄격한 보고 환경에 있는가?
- 다운 스트림 시스템이 95% 깨끗한 데이터와 95% 완전한 데이터를 처리 할 수 있는가?
- 암시적 표준은 무엇인가? ( ex] 서유럽을 기반으로 하는 경우, 모든 날짜 시간을 중부 유럽 시간으로 설정 )
- 데이터를 읽는 시스템의 하위 수준 세부 정보는 무엇인가?
Selecting data types
| Data type | Value type in Python |
|---|---|
| ByteType | Good for numbers that -128 ~ 127 |
| ShortType | Good for numbers that -32768 ~ 32767 |
| IntegerType | Good for numbers that -2147483648 ~ 2147483647 |
| FloatType | float |
| StringType | string |
| BooleanType | bool |
| DateType | datetime.date |
Badly formatted source data
잘못 된 행이 있을경우, 스파크는 잘못된 행을 통합하기 위해 노력합니다. (null 처리)
하지만 이는 우리가 원하는 방법이 아닙니다.
Handle invalid rows
스파크는 잘못된 행을 삭제하는 옵션을 제공합니다.
이를 위해 옵션 메소드 mode키워드에 DROPMALFORMED를 전달합니다.
prices = (spark.read.options(header="true", mode="DROPMALFORMED").csv('landing/prices.csv'))이렇게 설정하면, 잘못된 행이 자동으로 삭제됩니다.
The significance of null
잘못된 행이아닌, 불완전한 행일 경우, 해당 데이터를 모두 삭제하는 것은 이상적이지 않습니다.
prices = (spark.read.options(header="true").schema(schema).csv('/landing/prices_with_incomplete_rows.csv'))
prices.show()Spark의 가장 기본적인 방법은 null값으로 공백을 채우는 방법입니다.
Supplying default values for missing data
누락된 데이터를 특정 값으로 채우도록 Spark에 지시 할 수 있습니다.
prices.fillna(25, subset=['quantity']).show()이를 수행하는방법은 fillna 메소드를 사용하는 방법입니다. ( subset설정으로, 해당 열에만 영향 )
Badly chosen placeholders
사람들은 종종 가치를 모르는 필드에 자리 표시자(placeholder)를 지정합니다.
employees = spark.read.options(header="true").schema(schema).csv("employees.csv")이러한 자리 표시자는 분석 목적에 적합하지 않습니다. 대부분의 경우 알 수 없는 데이터를 단순히 null값 으로 처리하는 것이 좋습니다.
Conditionally replace values
from pyspark.sql.functions import col, when
from datetime import date, timedelta
one_year_from_now = date.today().replace(year=date.today().year + 1)
better_frame = employees.withColumn("end_date", when(col("end_date") > one_year_from_now, None)).otherwise(col("end_date"))
better_frame.show()여기서는 when() 함수의 조건을 사용하여 비논리적인 값을 대체합니다.
조건이 충족되면 값을 Python의 None으로 바뀝니다. 이 값은 Spark에서 null로 변환됩니다.
Why do we need to transform data?
통찰력은 일반적으로 데이터가 어느 정도 처리 된 후에 도출됩니다.
ex) 이웃에서 최고 평점을 받는 상위 10개의 호텔
정규화 과정, 위치 필터링 및 데이터 병합이 필요 할 수 있습니다. (훈련 된 기계 학습 모델을 적용하는 것도 데이터를 변환하는 것의 과정)
Common data transformations
비지니스 로직 적용과 관련된 5가지 매우 일반적인 데이터 변환은 다음과 같습니다.
-
데이터 필터링 ( 특정 분석에 유용한 데이터에만 집중 )
-
열을 선택 및 이름 변경 ( 해당 필드에 집중 할 수 있음 )
-
특정 필드별로 행을 그룹화 한 다음, 평균가격 및 샘플 수와 같읕 일부 메트릭 집계
-
특정 필드를 통해 연결하여, DataFrame를 결합하면, 데이터의 레코드에 더 많은 속성 부여 가능
-
마지막으로 주문 데이터를 통해 우선 순위를 지정
Filtering and ordering rows
prices_in_belgium = prices.filter(col('countrycode') == 'BE').orderBy(col('date'))부울 값이 있는 열을 “filter” 메소드에 전달하여 데이터를 필터링 할 수 있습니다.
ex) 이 예에서는 국가 코드가 문자열 “BE”와 같은 행만 유지됩니다.
- col 함수를 사용하여, Columns 개체를 만들 수 있습니다.
- orderBy를 통해 정렬을 할 수 있습니다.
Selecting and renaming columns
prices.select(
col("store"),
col("brand").alias("brandname")
).distinct()데이터가 있는 매장에서 판매 된 모든 브랜드를 알고 싶다고 가정하면, 선택 방법을 사용할 수 있습니다.
열의 이름을 바꾸려면 해당 열에서 “alias”메서드를 호출하기 만하면됩니다.
스파크에서는, DataFrame에서 distinct함수를 호출하여 고유 한 행만 반환 할 수 있습니다.
Grouping and aggregating with mean()
(price.groupBy(col('brand')).mean('price')).show()브랜드 별 평균 상품 가격을 알고 싶다면, 브랜드 열별로, 데이터를 그룹화하고, 각 그룹 내 가격의 평균을 호출 하는 것만큼 간단합니다.
Grouping and aggregating with agg()
(prices.groupBy(col('brand'))
.agg(
avg("price").alias("average_price"),
count("brand").alias("number_of_items"))
)평균과 갯수 모두를 원한단면, PySpark에서 agg메서드를 사용하면 됩니다.
Joining related data
일반적으로 조인을 통해 서로 다른 데이터 원본을 통합합니다.
ratings_with_prices = ratings.join(prices, ["brand", "model"])모든 행은 추가 정보로 보강됩니다.
Running your pipeline locally
파이썬을 실행하는 것처럼, PySpark 데이터 파이프 라인을 로컬에서 실행 할 수 있습니다.
즉, 파이썬 인터프리터를 호출하고 기본 어플리케이션에 대한 경로를 전달합니다.
python hello_world.py
python my_pyspark_data_pipeline.py스파크를 로컬에 설치한 경우 작동합니다.
파이프 라인에 필요한 모든 리소스와 올바르게 구성된 클래스 경로
클래스 경로는 Java에 알려준다는 점에서 PYTHONPATH와 유사한 역할을 합니다.
Using the “spark-submit” helper program
일상적인 작업에서는 spark-submit 스크립트를 사용하게 됩니다.
이 스크립트는 실행 환경을 설정하는 데 도움이 됩니다. 클러스터 관리자 및 선택한 배포 모드에 적합합니다. 클러스터 관리자는 다른 프로그램에서 사용할 수 있는 다른 노드의 RAM 및 CPU와 같은 클러스터 리소스 등을 관리합니다. ( YARN은 인기가 있으며, 각각 다른 옵션이 있습니다. )
이것이 spark-submit이 호출 매개 변수를 어느 정도 통합하려고 하는 이유입니다.
배포 모드는 Spark에 Spark 드라이버를 실행할 위치를 알려줍니다.
애플리케이션 : 전용 마스터 또는 클러스터 작업자 노드 중 하나
각 모드에는 장단점이 있으므로, 기술적으로 매우 빠릅니다.
시작 환경을 설정 한 후 “spark-submit”은 기본 클래스 또는 기본 메서드도 호출합니다.
Basic arguments of “spark-submit”
많은 PySpark애플리케이션의 경우 다음 템플릿 작업을 시작하는데 충분합니다.
spark-submit \
--master "local[*]" \
--py-files PY_FILES \
MAIN_PYTHON_FILE \
app_argumentsSpark-submit을 호출합니다.
선택적 마스터 인수를 전달합니다. ( 이는 클러스터 관리자에 고유 URL이거나, local[*]과 같은 문자열입니다. 이는 실제 클러스터 또는 단순히 로컬 머신 리소스를 가져올 수 있는 위치를 Spark에게 알려줍니다.)
PySpark 데이터 파이프 라인이 하나 이상의 Python 모듈에 의존하는 경우 이 모듈을 모든 노드에 복사하여 각 Python 인터프리터가 클러스터 작업자는 실행해야하는 기능의 세부 정보를 어디서 찾을 수 있는지 알고 있습니다. 일반적으로, 작업자 노드에 아직 설치되지 않은 모듈은 zip파일을 통해 제공합니다.
그리고 이것이 --py--files인수가 우리에게 하는 일입니다.
마지막으로 Spark에 어떤 파일이 메인 파일인지, 어플리케이션의 진입 점인지 알려줍니다.
SparkSession 생성을 트리거하는 코드가 포함 된 파일입니다. 해당 파일인 경우 해당 Python 모듈이 실제로 “argparse”를 통해 명령 줄 인수를 구문 분석합니다. (예를 들어, 모듈에서 명령 끝에 이러한(app_arguments) 추가 인수를 제공 할 수 있습니다.)
Collecting all dependencies in one archive
--py--files옵션은 각각에 추가 될 쉼표로 구분 된 파일 목록을 사용할 수 있습니다.
Python 인터프리터가 모듈을 찾을 위치를 나열하는 작업자의 PYTHONPATH
Zip 파일은 코드를 패키징하고 배포하는 일반적인 방법입니다.
PySpark에서 사용할 준비가 된 적절한 zip파일을 만들려면, 모듈의 루트 폴더를 포함하는 디렉토리에 대한 쉘이 필요합니다.
zip \
--recurse-paths \
dependencies.zip \
pydiaper
spark-submit \
--py-files dependencies.zip \
pydiaper/cleaning/clean_prices.py--recurse-paths플래그를 전달하여 모든 하위 폴더의 모든 파일을 추가합니다.
결과 압축 아카이브의 이름을 제공하고, 마지막으로 압축하려는 폴더의 이름을 제공합니다.
결과 zip 파일은 “spark-submit”의 --py-files인수에 그대로 전달할 수 있습니다.
Testing your data pipeline
웹 브라우저 같은 소프트웨어는 아직 완성되지 않았기 때문에, 제품이 변경되는 것은 당연합니다. 또한, 잘못된 계산이나 응답 불량과 같은 문제가 발견되고 해결되어야 합니다.
그러나 제품의 주요 측면도 일정하게 유지되어야 합니다.
근무 시간을 기준으로 사람들의 임금을 계산하는 코드는 지속적이고 잘 테스트 되는 것이 좋습니다.
Rationale behind testing
우리의 기대치가 일치 함을 확인하기 위해 테스트가 작성되고 실행됩니다. 코드 기반에 대한 테스트를 수행함으로써, 우리는 과거의 어느 시점에 그랬던 것처럼, 우리의 기대에 대한 서면 사본을 갖게됩니다.
따라서 테스트를 통해 주요 변경 사항을 도입 할 가능성이 줄어듭니다.
테스트가 없으면, 함수가 호출될 때까지 결과를 알 수 없습니다. ( 비용적인 측면도 많이 듬 )
자동화된 테스트는 이를 방지하는 데 도움을 줍니다. 테스트는 거의 완전하지 않습니다. ( 모든 경우의 수를 다해 보는것이 아니라, 몇개의 샘플만 테스트하도록 선택합니다. - 따라서 테스트가 모든 경우에 대한 정확성을 보장하지는 않습니다. )
테스트의 필요성에 대한 다른 주장은, 테스트가 가장 최신의 문서형식이라는 것입니다.
종종 사람들은 일부 소프트웨어의 기능을 수동으로 설명하는 문서를 작성합니다.
설정이 높은 수준으로 유지되는 한 괜찮습니다. 특정 기능에 대한 세부사항은 피해야합니다. ( 실제로 실행되는 것과, 동기화되지 않는 경향이 있습니다. )
잘 작성된 테스트는 코드가 블랙 박스로 취급 되더라도 코드가 무엇을하는지 명확히 할 수 있습니다.
코드를 테스트해야하는 이유가 더 많지만, 이 세가지 이유로 충분한 인센티브를 제공할 수 있습니다.
The test pyramid: where to invest your efforts
때때로 사람들은 테스트를 피하는데, 소프트웨어에 더 많은 기능을 추가하는데 더 많은 시간을 소요합니다.
테스트에 시간이 걸리는 것은 사실이지만, 프로젝트로 보답하는 것은 투자입니다.
특히 테스트가 다른 위치에서 복제되지 않고, 중요하지 않은 부분을 테스트 할 때 더 커집니다.
테스트를 설계 할 때 명심해야 할 유용한 개념은 테스트 피라미드입니다.
노력을 어디에 투자해야하는지 알려줍니다.
외부 구성 요소와의 통합에 의존하지 않는 코드 조각을 테스트하는 것은 단위 테스트입니다. 이들은 빠르게 실행될 수 있고 개발 노력이 저렴합니다.
이러한 테스트는 매우 빠르게 실행되기 때문에 많은 테스트가 있어야 합니다.
파일 시스템 및 데이터베이스와의 상호 작용은 통합 테스트입니다.
통합 테스트(서비스 테스트)는 서로 다른 서비스 또는 구성요소를 통합합니다. 그들은 더 느리게 실행되고, 설정에도 더 많은 노력이 필요합니다. 단위 테스트가 이미 일부를 다루어야 하기 때문에 적은 수를 가질 수 있습니다.
엔드 투 엔드 테스트에서도 마찬가지입니다. 사용자 인터페이스 (UI)를 통해 상호작용할 때 사용자가 얻을 수 있는 경험 느리게 실행되고 자주 발생하므로 비용이 훨씬 더 많이 듭니다. 강력하게 작성하기는 어렵지만, 최종 사용자의 경험에 가깝습니다.
Spark application is an ETL pipeline
- 위치에서 추출 된 데이터
- 변형
- 다른 위치에 로드
첫 번째 단계(추출)와 마지막 단계(저장) 단계에서는, 데이터베이스, 파일 시스템 및 클라우드 제공 업체와 같은 다른 서비스와 상호 작용합니다.
이러한 상호 작용은, 비용이 많이 들고, 이전에서 알 수 있듯이, 자주 일어나면 안됩니다. 이것이 우리가 진정한 비지니스 가치를 추가하는 곳입니다.
Separte transform from extract and load
prices_with_ratings = spark.read_csv("...") # extract
exchange_rates = spark.read.csv("...") # extract
unit_prices_with_ratings = (prices_with_ratings.join(...).withColumn(...)) # transform변환은 파일 시스템과의 상호 작용을 통해 얻은 DataFrames에서 작동합니다. ( 의존성을 제거하고 전적으로 변화에만 집중하길 원함 )
Construct DataFrames in-memory
( 변환이 더 이상 파일에서 데이터를 가져 오지 않는 경우에도 데이터를 어떻게 공급하는가? )
Spark DataFrames는 메모리 내에서도 생성 될 수 있습니다.
# Extract the data
df = spark.read.csv(path_to_file)인메모리를 생성하여 해결하는 것은 여러가지 단점이 있습니다.
- input/output에 의존하게 됨
- unclear how big the data is
- unclear what data goes in
from pyspark.sql import Row
purchase = Row("price", "quantity", "product")
record = purchase(12.99, 1, "cake")
df = spark.createDataFrame(record)사용자 지정 Spark SQL Row 클래스를 만들고 이 클래스 인스턴스의 반복 가능한 모든 인스턴스를 createDataFrame() 생성자에 전달합니다.
여기에는 분명한 이점이 있습니다.
- 데이터가 함수로 전달 되는 것을 즉시 확인
- 파일을 찾거나 다운로드하기 위해 여기저기서 클릭 할 필요가 없습니다.
Create small, reusable and well-named functions
def link_with_exchange_rates(prices, rates):
return prices.join(rates, ["currency", "date"])
def calculate_unit_price_in_euro(df):
return df.withColumn("unit_price_in_euro", col("price")/col("quantity")*col("exchange_rate_to_euro"))
unit_prices_with_ratings = (
calculate_unit_price_in_euro(
link_with_exchange_rates(price, exchange_Rates)
)
)이 전에는 코드를 하나에 여러 일을 작동하게 했지만, 그렇게하면 코드를 테스트 하기 힘듭니다. 따라서 다음과 같이, 각 단계를 자체 기능에 기록합니다.
새로운 함수를 작성하는 것은 어리석은 것 처럼 보일 수 있지만, 단일 변환, 각 변환 자체를 테스트 할 수 있습니다. 또한 재사용 될 수 있습니다.
Testing a single unit
단가를 유로로 계산하는 테스트를 작성하는 코드
def test_calculate_unit_price_in_euro():
record = dict(price=10,
quantity=5,
exchange_rate_to_euro=2.)
df = spark.createDataFrame([Row(**record)])
result = calculate_unit_price_in_euro(df)
expected_record = Row(**record, unit_price_in_euro=4.)
expected = spark.createDataFrame([expected_record])
assertDataFrameEqual(result, expected)필요한 열만 있는 메모리 내 DataFrame을 만드는 것으로 시작합니다.
Row에 record딕셔너리를 압축하는 방법으로, 언패키징 방법을 사용합니다.
DataFrame을 테스트하려는 함수에 전달하고 값을 비교합니다. (이 방법은 직접 쉽게 계산할 수 있으며, 메모리 내 DataFrame으로 테스트를 실행하는 또 다른 이점입니다. )
이제 시작 사전을 사용한 이유도 알 수 있는데, 초기 및 예상 DataFrame 모두에서 반복됩니다.
Take home messages ( 함수화 하면 좋은 점)
- 외부 데이터 소스와 상호 작용하는 것은 값 비싼 메모리 내 DataFrame를 사용하면 단일 기능을 보다 쉽게 테스트 할 수 있습니다.
- 눈에 잘 띄는 데이터와 소수의 예에 초점을 맞출수 있음
- 당신의 코드는 리팩토링되어 작게 재사용 가능하며, 이름이 잘 지정된 함수는 테스트 하기 더 쉽습니다.
Running a test suite
많은 프로그래밍 언어가 테스트를 실행하는 기능을 제공합니다. 파이썬에도 이를 수행하는 여러 모듈이 있습니다.
- unittest
- doctest
- pytest
- nose
모든 경우에 이러한 도구는 모듈, 클래스 및 함수를 찾습니다. ( 접두사(test 등) 을 통해 드릴 다운하여 실행할 수 있는 코드를 찾은 다음 실행 )
그들의 핵심 임무는 무언가를 주장하는 것입니다. ( 계산 된 값이, 예상 값과 같거나 오류가 발생했습니다. )
assert computed == expected
with pytest.raises(ValueError)Manually triggering test
이러한 프레임 워크의 가장 큰 특징은 실행이 끝날 때 보고서를 생성한다는 것입니다.
cd ~/workspace/my_good_python_project
pytest .어떤 테스트가 통과 되었는지, 어떤 테스트가 실패하였는지 요약하고, 종종 디버깅에 도움이 되는 추가 정보를 제공합니다.
이전에 단위 테스트가 빠르게 실행되어야 한다고 말했는데, 단일 테스트늬 경우 2초는 긴 시간입니다.
Spark 및 기타 분산 컴퓨팅 프레임 워크는 테스트에 오버 헤드를 추가합니다.
Automating tests
자동화는 데이터 엔지니어의 주요 목표 중 하나입니다.
단위 테스트를 수동으로 실행하는 것은, 지루하고 오류가 발생하기 쉽습니다.
일련의 코드 변경 후 실행하는 것을 잊을 수 도 있습니다.
코드를 전문적으로 작업하는 경우, git 과 같은 일종의 버전 제어 시스템을 사용하는 것입니다.
많은 버전 제어 시스템에서 코드를 변경 할 때, 실행할 특정 스크립트를 구성 할 수 있습니다.
변경 사항에 대한 빠른 피드백을 제공할 수 있으므로 훌륭합니다.
버전 제어 시스템에서 제공하는 옵션을 탐색하는 것이 좋습니다.
CI / CD
두 번째 방어선은 프로젝트의 CI/CD 파이프라인입니다.
CI / CD는 Continuous Integration 및 Continuous Delivery를 나타냅니다.
Continuous Integration
- 마스터 브랜치라고 하는 프로덕션에서 실행되는 코드로 가능한 빨리 변경 사항으로 인해 테스트가 어느 정도 감지 할 수 있는 문제가 없는 경우에만 허용
- 테스트를 실행하고 많은 것을 보유하는 데 집중합니다.
Continuous Delivery
- 모든 아티팩트가 문제없이 항상 가능한 상태에 있어야 합니다.
- 일부 버전 제어 시스템의 일부로 코드를 일부 원격 서버에 푸시 할 때, Python 스타일 가이드 인 PEP8 준수와 같은 실행중인 단위 테스트 및 정적 코드 검사를 트리거 합니다.
Configuring a CI/CD tool
- CircleCI : 자동으로 테스트를 실행하는 서비스 ( 이러한 많은 도구와 마찬가지로 코드 저장소에서 특정 파일을 찾습니다. ) 코드 저장소 루트에 있어야하는 circleci 폴더의 config.yml 파일을 찾습니다. 구문은 JSON의 상위 집합인 YAML이지만, 초점이 다르며 많은 기능을 추가합니다.
jobs:
test:
docker:
- image: circleci/python:3.6.4
steps:
- checkout
- run: pip install -r requirements.txt
- run: pytest .구성 파일에는 작업이라는 세션이 있습니다. 각 작업에는 테스트와 같은 이름이 있습니다.
작업은 일부에서 실행되는 단계 모음입니다. 이 경우 Python의 특정 버전을 위해 설계된 도커 이미지입니다.
단계는 순서대로 실행되며, 일반적으로 새 프로젝트를 받은 경우 수동으로 실행할 단계
이 경우 CircleCI에 코드에서
- 코드를 확인하도록 지시합니다.
- 필요한 모듈 설치 및 pytest로 테스트 스위트 실행
- 테스트 실행
- 테스트가 성공하면, 애플리케이션을 패키징하여 서버에 배포하거나 나중에 사용할 수 있도록 저장할 수 있습니다.
What is a workflow?
워크 플로는 예약 된 일련의 작업입니다.
실행하거나 이벤트 발생에 의해 트리거 될 수 있습니다.
워크 플로는 일반적으로 데이터 과학자와 데이터 엔지니어가 데이터 처리 파이프 라인을 조정하는 데 사용됩니다.
종종 일정에 따라 실행해야하는 작업이 있습니다.
Scheduling with cron
예를 들어 변동 예측 알고리즘은 매주 실행해야 할 수 있습니다.
이러한 경우에 자주 사용되는 소프트웨어 유틸리티는 “cron”입니다.
Cron은 “crontab” 파일로 알려진 구성 파일을 읽습니다.
이러한 파일에서 특정 시간에 실행할 작업을 표로 만듭니다.
*/15 9-17 * * 1-3,5 log_my_activity이 crontab 레코드는 특정 시간에 “log_my_activity”프로세스를 실행합니다.
15분마다 9-17시에 매일, 매월, 1(월), 2(화), 3(수), 5(금) 에 다음을 실행한다.
크론탭은 매우 기본적인 스케쥴러입니다.
매우 잘 작동하지만, 시간이 지남에 따라 모니터링하려는 복잡한 워크 플로에 가장 적합한 도구는 아닙니다.
- Luigi
- Azkaban
- Airflow
위와 같은 도구를 사용 하는 것이 더 효율적입니다.
Apache Airflow fulfills modern engineering needs
최신 워크 플로 관리 도구에서 기대하는 것은 복잡한 워크 플로를 만들고 시각화 할 수 있다는 것입니다.
Airflow가 앞서 본 워크 플로 회로도를 시각화 하는 방법은 다음과 같습니다.
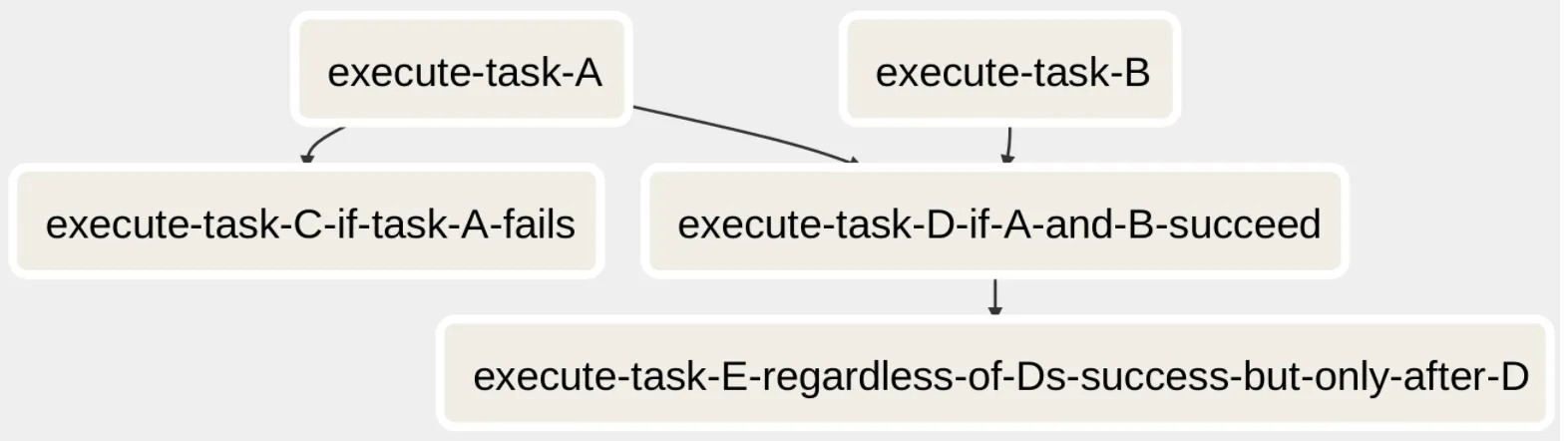
이러한 도구를 통해 워크 플로를 모니터링 할 수도 있습니다.
Airflow는 특정 작업이 실패한시키 또는 각 작업에 걸린 시간을 보여주고, 이를 명확한 차트로 표시할 수 있습니다.
마지막으로, 수평 확장이 중요합니다.
더 많은 작업을 실행할수록 도구가 단일 시스템의 성능을 높이는 대신, 여러 시스템을 사용합니다.
Airflow는 이러한 모든 요구 사항을 충족하므로, cron을 대체하는 것이 좋습니다.
The Directed Acyclic Graph (DAG)
Airflow 워크 플로의 중심 부분은 Directed Acyclic Graph인 DAG입니다.
그래프는 간선으로 연결된 노드 모음입니다.
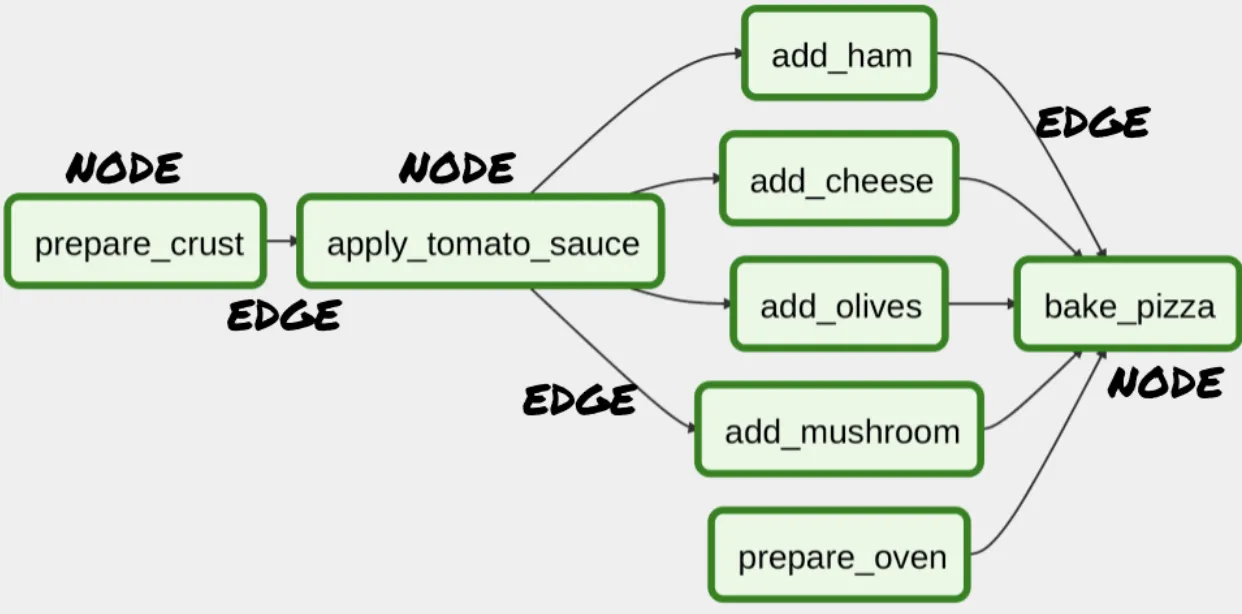
두문자어의 지시 된 부분은, 노드 사이에 방향 감각이 있음을 의미합니다.
가장자리의 화살표는 방향을 나타냅니다.
“비순환” 부분은 단순히 횡단 일 떄, 방향 그래프를 사용하면 동일한 노드로 다시 동그라미를 칠 수 없습니다.
Airflow에서 노드는 “운영자” 이며, 각 인스턴스에는 고유 한 레이블 인 작업 ID가 부여될 수 있습니다.
운영자는 Python 스크립트를 실행하거나 클라우드 공급자를 통해 작업을 예약하는 등의 작업을 수행할 수 있습니다.
스케쥴러에 의해 트리거되지만, 일반적으로 다른 프로세스인 실행기에 의해 실행됩니다.
The Directed Acyclic Graph in code
코드에서 Airflow DAG에는 ‘dag_id’가 필요합니다.
from airflow import DAG
my_dag = DAG(
dag_id="publish_logs",
schedule_interval="* * * * *",
start_date=datetime(2010, 1, 1)
)가장 일반적인 선택적 인수 중 일부는 ‘schedule_interval’ 입니다.
cron 일정과 DAG가 시작되어야하는 날짜를 전달할 수 있습니다.
연산자는 나중에 코드에서 이 DAG에 할당됩니다.
Classes of operators
작업은 기본적으로 연산자 클래스의 인스턴스입니다.
Airflows는 여러 가지와 함께 제공되지만 고유 한 연산자를 정의 할 수 도 있습니다.
일반적으로 수행하는 작업에 따라 이름이 저장됩니다.
- BashOperator -> bash 커맨드/스크립트
- PythonOperator -> Python
- SparkSubmitOperator -> 스파크
Expressing dependencies between operators
dag = DAG(...)
task1 = BashOperator(...)
task2 = PythonOperator(...)
task3 = PythonOperator(...)
task1.set_downstream(task2)
task3.set_upstream(task2)
# task1 >> task2
# task3 << task2
# or
# task1 >> task2 >> task3연산자 간의 종속성은 다음과 같이, “set_upstream()” 및 “set_downstream()” 메서드로 코딩됩니다.
다음과 같이 비트 시프트 연산자를 사용하여 이러한 동일한 관계를 정의 할 수 도 있습니다.
이와 같은 간단한 DAG 설명은 선형흐름을 생성합니다.
연산자의 인수를 사용하면 다음을 지정할 수 있습니다.
Airflow’s BashOperator
Airflow의 BashOperator를 사용하여 bash 쉘에서도, 실행할 수 있는 모든 bash 명령을 실행합니다.
spark-submit과 Singer 수집 파이프 라인은 모두 이러한 방식으로 트리거 할 수 있는 명령입니다.
Airflow를 통해 이러한 명령을 실행하는 한 가지 이점은 실행이 기록되고 모니터링되며 재 시도된다는 것입니다.
from airflow.operators.bash_operator import BashOperator
bash_task = BashOperator(
task_id='greet_world',
dag=dag,
bash_command='echo "Hello, world!"'
)모든 Airflow 연산자는 사용자가 선택할 수 있는 고유 식별자인 “task_id”를 사용합니다.
이 작업을 할당하는 DAG 개체에 대한 참조는
모든 연산자는 조상 인 BashOperator 클래스에서 상속하기 때문입니다.
마지막으로 “bash_command”에서 BashOperator에서 실행할 bash 명령을 문자열로 지정합니다.
이 중 여러 개를 지정하거나, 이름으로 스크립트 파일을 지정할 수 도 있습니다.
Airflow’s PythonOperator
BashOperator를 사용하여 많은 작업을 수행 할 수 있지만, “python my_app”과 같은 적절한 bash 명령을 전달하여 모든 사례를 제공하지는 않습니다.
예를 들어 Python 모듈을 수정할 수는 없지만, 필요한 기능이있는 경우 BashOperator는 많이 사용되지 않습니다.
이 경우 “PythonOperator”를 사용하는 것이 훨씬 더 적절합니다.
from airflow.operators.python_operator import PythonOperator
from my_library import my_magic_function
python_task = PythonOperator(
dag=dag,
task_id='perform_magic',
python_callable=my_magic_function,
op_kwargs={"snowflake": "*", "amount": 42}
)PythonOperator의 “python_callable”인수는 함수와 같이 호출 될 수 있는 모든 것 뿐만 아니라 클래스도 가능합니다.
여기에서 실제로 콜러블 이라고 부르지 않는 점에 주의해주세요.
작업이 트리커되면 운영자가 호출합니다.
아 콜러블에 추가 인수가 필요한 경우 선택적 키워드 인수 “op_args” 및 “op_kwargs”를 사용하여 전달할 수 있습니다.
Running Pyspark from Airflow
Airflow를 사용하여 이러한 파이프 라인을 호출하고 싶다면, 이를 수행하는 몇 가지 방법이 있습니다.
spark_master = (
"spark://"
"spark_standalone_cluster_ip"
":7077")
command = (
"spark-submit "
"--master {master}"
"--py-files package1.zip "
"/path/to/app.py"
).format(master=spark_master)
BashOperator(bash_command=command, ...)BashOperator를 사용하여 “spark-submit”을 호출 할 수 있습니다.
명령을 문자열로 지정한다는 점을 기억해야합니다.
여기서는 가독성을 높이기 위해 괄호를 사용하여 명령의 인수를 분할했습니다.
Airflow 서버의 bash셀에서 명령을 성공적으로 실행할 수 있다면 작동합니다.
이 접근 방식의 단점은 Airflow 서버에 Spark 바이너리를 설치해야한다는 점입니다.
이를 수행하는 또다른 방법은 Airflow의 SSHOperator를 사용하여 다른 서버에 위임하는 것 입니다.
from airlfow.contrib.operators.ssh_operator import SSHOperator
task = SSHOperator(
task_id='ssh_spark_submit',
dag=dag,
command=command,
ssh_conn_id='spark_master_ssh'
)이 연산자는 모든 타사 기여 연산자를 포함하는 contrib 패키지에 속합니다.
BashOperator에 비해 이 연산자는 Spark바이너리를 다른 컴퓨터에 설치해야합니다.
Spark 지원 클러스터에 원격으로 액세스 할 수 있는 경우 이는 매우 깔끔하게 진행할 수 있는 방법입니다.
다시 한번 문자열 형식으로 실행할 명령을 추가합니다.
이 연산자의 “ssh_conn_id”인수를 확인하십시오.
관리 메뉴의 연결 아래에 있는 Airflw사용자 인터페이스에서 구성할 수 있는 연결을 나타냅니다.
이러한 연결은 다음과 같은 편리한 방법을 제공합니다.
다른 서버에 대한 연결 세부 정보와 관련된 하드 코디되고 중복된 정보를 제거합니다.
from airflow.contrib.operators.spark_submit_operator import SparkSubmitOperator
spark_task = SparkSubmitOperator(
task_id='spark_submit_id',
dag=dag,
application-"/path/to/app.py",
py_files="package1.zip",
conn_id='spark_default'
)Spark 작업을 실행하는 또 다른 방법은 “SparkSubmitOperator”를 사용하는 것입니다.
이것도 기여한 운영자에게 속합니다.
Airflow 서버에서 직접 “spark-submit”을 사용하는 것이므로, BashOperator를 사용하는 솔루션과는 많이 다르지만, 키워드 인수를 제공합니다.
spark-submitd의 인수를 위해 전체 명령을 문자열로 작성할 필요가 없습니다.
또한 SSHOperator와 동일한 방식으로 연결을 사용합니다.
다른 작업에서 DAG는 모두 동일한 spark지원 클러스터에 연결되어 있으면 간단합니다.
Installing and configuring Airflow
워크 플로가 이제 Airflow DAG에 완전히 설명되 있지만 이를 실행할 준비가 된 서버를 만들지 않았습니다.
시작하는 가장 쉬운 방법은 Linux 이미지에 설치하는 것입니다.
Linux를 실행하는 로컬 서버를 사용할 수 있다고 가정합시다.
다른 어떤 것도 실행하지 않고 Python 환경이 깨끗합니다.
export AIRFLOW_HOME=~/airflow
pip install apache-airflow
airflow initdb셀에서 일부 디렉토리를 AIrflow의 홈 디렉토리로 선언합니다.
다음으로 Airflow를 설치합니다.
이후, 메타 데이터 데이터베이스를 초기화합니다.
이와 같이 새로 설치하면 AIRFLOW_HOME 디렉퇴가 생성되고 모든 로그 파일, 두 개의 구성 파일 및 SQLite 데이터베이스에 대한 하위 디렉토리로 채웁니다.
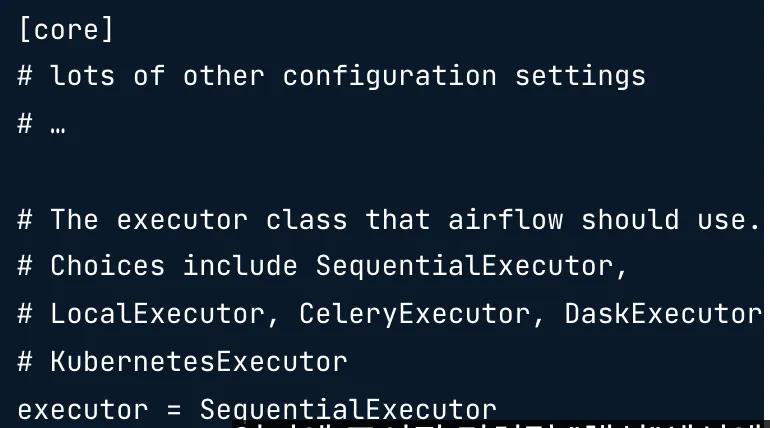
프로덕션에서는 MySQL과 같은 고급 데이터베이스를 사용할 가능성이 높습니다.
SequentialExecutor를 사용하도록 Airflow를 구성한 경우에도 작동합니다.
unittests의 구성 파일에서 이것은 미리 설정되어 있습니다.
프로덕션에서 사용할 다른 구성 파일에서 여기에 표시된 “핵심” 섹션에서도 유사한 설정을 찾을 수 있습니다.
Setting up for production
기본 구성 파일에 몇 개의 폴더를 더 추가했습니다.
특히 “dags”폴더는 이전 강의에서 작성하는 방법을 배운 DAG를 배치하는 위치입니다.
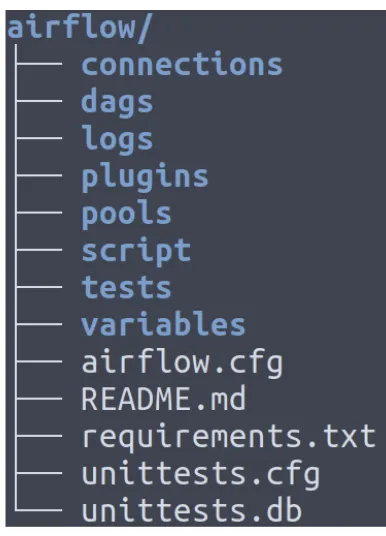
또한 “tests” 폴더를 확인하십시오
CI / CD 에서 사용할 수 있는 기능으로 채울 것입니다.
3 장의 데이터 변환 파이프 라인에서 했던 것처럼 파이프 라인입니다.
연결, 플로그인, 연결 풀 및 변수에 대한 폴더도 있습니다.
이 모든 기능을 통해 버전 제어하에 Airflow의 전체 배포를 쉽게 할 수 있습니다.
Example Airflow deployment test
Airflow DAG 파일은 기술적으로 Airflow의 웹 인터페이스를 통해서만 발견되는 오류를 생성 할 수 있습니다.
하지만, CI / CD 파이프 라인의 테스트 단계의 일부로 이를 더 일찍 캡처 할 수 있습니다.
from airflow.models import DagBag
def test_dagbag_import():
"""Verify that Airflow will be able to import all DAGs in the repository."""
dagbag = DagBag()
number_of_failures = len(dagbag.import_errors)
assert number_of_failures ==0, "There should be no DAG failures. Got: %s" % dagbag.import_errors예를들어, 이것을 추가하는 훌륭한 테스트가 될 수 있습니다.
먼저 폴더에있는 모든 DAG의 모음 인 DagBag를 가져와 인스턴스화합니다.
인스턴스화되면 DAG에 대한 오류 메시지 사전을 보유합니다.
파이썬 구문 오류나 순환의 존재와 같은 문제가 있었습니다.
이 테스트에서 테스트 프레임 워크가 실패하면 CI / CD 파이프 라인이 자동 배포를 방해할 수 있습니다.
Transferring DAGS Ang plugins
기본 설치가 포함 된 리포지토리에 모든 DAG를 유지하는 경우, Airflow 서버에서 저장소를 복제하여 간단히 수행 할 수 있습니다.
또는 DAG 파일 및 모든 종속성을 처리 코드에 가깝게 유지하는 경우, “rsync”와 같은 도구를 사용하여 DAG 파일을 서버에 복사하기 만 하면됩니다.
또는, 프로젝트간에 더 나은 격리를 촉진하는 압축 된 아카이브 패키지 DAG를 사용합니다.
이후, zip 파일을 서버에 복사해야합니다.
Airflow 서버가 정기적으로 동기화하도록 할 수 도 있습니다. 모든 사람이 쓰는 DAG 저장소가 있는 DAG 폴더, 이것들은 단지 몇가지 접근 방식이며 더 많은 것도 있습니다.