데이터를 어떻게 구성하고 관리할까?
- Schemas
- Normalization
- Views
- Access control
- DBMS
- … and more
어떻게 구성하냐에 따라, 가격이 다르고, 성능이 다르고, 메모리 차지하는 양이 다릅니다.
-> 정답은 없으며, 데이터를 어떻게 사용하느냐에 따라 다릅니다.
OLTP vs OLAP
OLTP와 OLAP는 데이터 처리에 대한 접근 방식입니다. 이는 데이터 흐름, 구조화 및 저장 방식을 정의하는데 도움이 됩니다.
비지니스 사례에 맞는 것이 무엇인지 파악하면 데이터베이스 설계가 휠씬 쉬워집니다.
OLTP
- Online Transcation Processing
- 트랜잭션 중심
OLAP
- Online Analytical Processing
- 분석 중심
OLTP
- 책의 가격을 찾는다.
- 모든 고객 거래를 추적한다. ( 고객이 지불을 마칠 때 판매를 삽입하는 OLTP 접근 방식 )
- 직원의 근무시간을 기록한다.
OLAP
- 가장 수익성이 높은 도서를 분석한다.
- 충성 고객처럼 판매에 대한 정교한 분석을 수행한다.
- 이달의 직원이 될 자격이 있는 사람에 대한 분석을 수행한다.
OLTP는 일상적인 작업을 지원하는데 중점을 두는 반면,
OLAP 작업은 모호하고 비지니스 의사 결정에 중점을 둡니다.
OLTP
- 목적 : 데이터 처리를 돕는다
- 디자인 : 애플리케이션 지향적
- 데이터 : 아카이브되는 트랜잭션의 현재 스냅 샷
- 사이즈 : 스냅샷 (기가바이트)
- 쿼리 : 간단하고, 빠른 쿼리 또는 업데이트 필요
- 유저 : 회사 전체에서 더 많은 사람들이 사용
OLAP
- 목적 : 데이터 분석을 돕는다.
- 디자인 : 분석중인 특정 주제 중심
- 데이터 : 장기 분석을 위해 통합 된 기간
- 사이즈 : 아카이브 (테라바이트)
- 쿼리 : 분석에 필요한 복잡한 쿼리 사용
- 유저 : 분석가 및 데이터 과학자
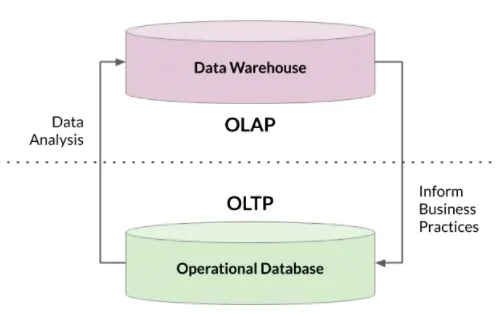
OLTP 및 OLAP 시스템은 함께 작동합니다. 그들은 서로를 필요 합니다.
OLTP 데이터는 일반적으로 OLAP 데이터웨어 하우스를 만들기 위해 가져 와서 정리되는 운영 데이터베이스에 저장됩니다.
트랜잭션 데이터가 없으면 분석을 수행 할 수 없습니다.
OLAP 시스템의 분석은 비지니스에 정보를 제공하는데 사용합니다. OLTP 데이터 베이스에 영향을 미칩니다.
Takeaways
- 비지니스 요구 사항을 파악
- OLAP or OLTP 접근 방식이 필요한지 파악
1. Structured data
- 일반적으로 스키마에 의해 정의 되는 구조화 데이터
- 데이터 유형, 테이블 정의, 관계 등 정의
2. Unstructured data
- 스키마가 없고, 가장 원시적인 형태의 데이터 ( 깨끗하지 않음 )
- Ex) 사진, 채팅로그, MP3파일 등
3. Semi-structured data
- 더 큰 스키마보다는 임시 자체 설명 구조를 가지고 있습니다.
- 일부 구조가 있습니다.
- Ex) NoSQL, XML, JSON

깔끔하고 체계화 된 데이터는 분석하기 더 쉽습니다. 그러나 스키마를 따라야 하기 때문에 확장성이 떨어집니다.
전통 데이터 베이스
- 일반적으로 관계형 스키마를 따릅니다. ( OLTP에 사용되는 운영 데이터베이스 )
- 데이터 분석이 시작되면 데이터 웨어하우스가 OLAP 접근 방식으로 대중화되었습니다.
- 빅데이터 시대에 우리는 더 많은 데이터를 분석하고 저장해야 하는데 이를 데이터 레이크를 이용합니다.
데이터 웨어하우스
- 읽기 전용 분석에 최적화 ( OLAP )
- 여러 소스의 데이터를 결합하고 더 빠른 쿼리를 위해 대규모 병렬 처리
- 일반적으로 차원 모델링과 비정규화 된 스키마를 사용합니다.
- AWS RED SHIFT, Azure SQL Data Warehouse, Google Big Query
- 데이터 마트는, 특정 주제 전용 데이터 웨어하우스의 하위 집합입니다.
- 데이터 마트를 사용하면 부서에서 중요한 데이터에 쉽게 액세스 가능합니다.
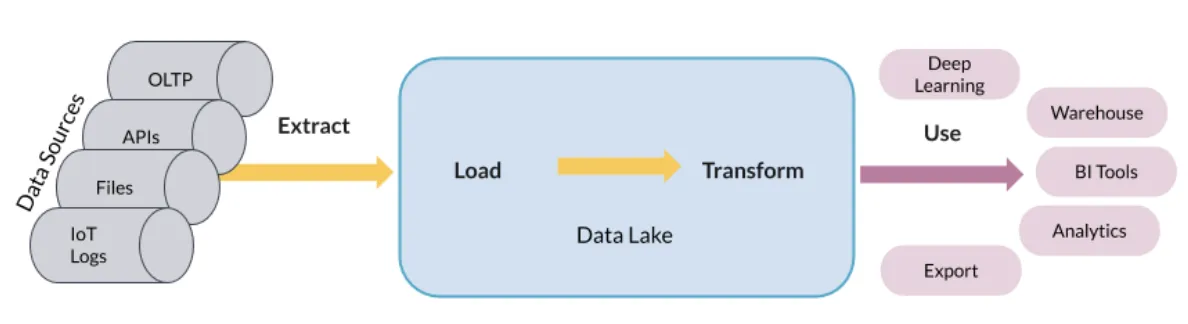
데이터 레이크
- 기술적으로 기존 데이터베이스 및 웨어하우스는 비정형 데이터를 저장 할 수는 있지만 비용적으로 효율적이지 않습니다.
- 데이터 레이크 스토리지는 기존 블록 또는 파일 스토리지와 달리 개체 스토리지를 사용하기 때문에 더 저렴합니다. ( 대량의 데이터 저장 가능 )
- 스트리밍 데이터에서 운영 데이터베이스에 이르기까지 모든 유형에 효과적으로 적용됩니다.
- 데이터 레이크는 사용할 수 있는 모든 데이터를 저장합니다.
- 비정형 데이터는 가장 확장성이 뛰어나기 때문에 거대한 크기의 데이터라도 허용합니다.
- 데이터 레이크는 읽을 때, 스키마가 생성됩니다. (데이터 웨어하우스는 작성 시 스키마 분류)
- 데이터 레이크는 잘 조직되고 분류되어야 합니다. (그렇지 않으면 데이터 늪이 됩니다.)
- 데이터 레이크는 스토리지로 끝나지 않고, 분석을 실행하는 것도 인기를 얻고 있습니다. ( 딥러닝 및 데이터와 같은 작업 )
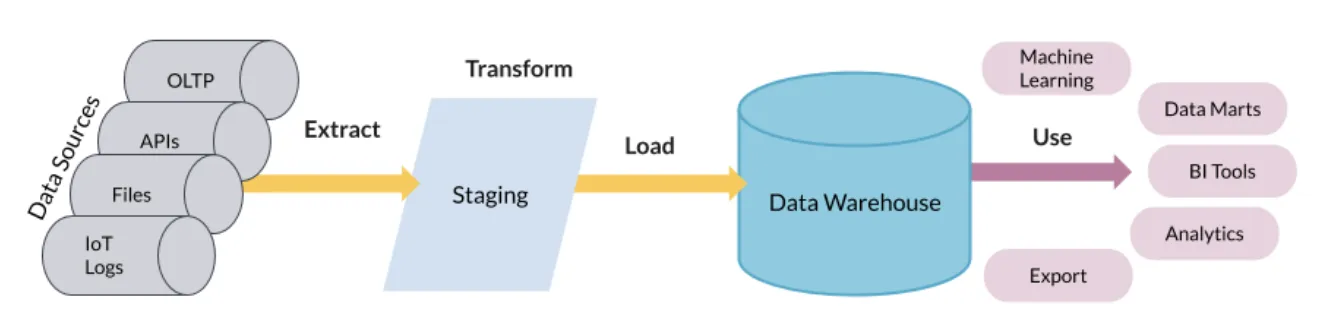
ETL
- Extract - Transform - Load
- 데이터 웨어하우징 및 소규모 분석을 위한 전통적인 접근 방식
ELT
- Extract - Load - Transform
- ELT는 빅데이터 프로젝트에서 일반화 되었습니다.
데이터베이스 디자인이란?
데이터베이스 설계는 데이터가 논리적으로 저장되는 방식을 결정합니다.
이는 데이터 읽기 또는 데이터 업데이트 여부에 관계없이 데이터베이스 쿼리 방법에 영향을 미치기 때문에 중요합니다.
데이터 베이스 디자인에 필요한 두가지
- 데이터 베이스 모델 : 데이터베이스 구조에 대한 고급 사양, 가장 인기있는 관계형 모델은 관계형 데이터 베이스를 만드는데 사용
- 스키마 : 데이터베이스의 청사진, 데이터베이스 모델의 구현, 특정 테이블, 필드, 관계, 인덱스 및 뷰를 정의하여 논리적 구조를 보다 세분화합니다. 구조화 된 데이터를 관계형 데이터베이스에 삽입 할 때 스키마를 준수해야 합니다.
데이터 모델링
데이터 베이스 설계의 첫 번째 단계는 데이터 모델링입니다. 이는, 저장 될 데이터에 대한 데이터 모델을 정의하는 추상 디자인 단계입니다.
- 개념적 데이터 모델 : 엔티티, 관계 및 속성과 같은 데이터베이스에 포함 된 내용
- 논리적 데이터 모델 : 엔티티 관계가 테이블에 매핑되는 방식을 결정
- 물리적 데이터 모델 : 데이터가 가장 낮은 추상화 수준에서 물리적으로 저장되는 방식을 살펴봄
이러한 세가지 수준의 데이터 모델은 일관성을 보장하고 구현 및 사용 계획을 제공합니다.
차원 모델링
- 데이터 웨어 하우스를 위해 관계형 모델을 수정한 것
- 업데이트보다는 분석을 목표로하는 OLAP 유형의 쿼리에 최적화 되어 있음
- 스타 스키마를 사용
- 차원 스카마는 해석 및 확장이 용이합니다.
- 두 가지 유형의 테이블로 구성됩니다.
- Fact tables
- 비지니스 사용 사례에 따라 결정
- 주요 측정 항목으로 레코드가 포함되며, 측정 항목은 자주 변경됨
- 차원 테이블에 대한 외래 키도 보유합니다.
- Dimension tables
- 특정 속성에 대한 설명을 보유하며 자주 변경되지 않습니다.
- Fact tables
Star schema
스타 스키마는 차원 모델의 가장 단순한 형태입니다. ( 일부는 스타 스키마와 차원 모델링 이라는 용어를 같은 의미로 사용합니다. )
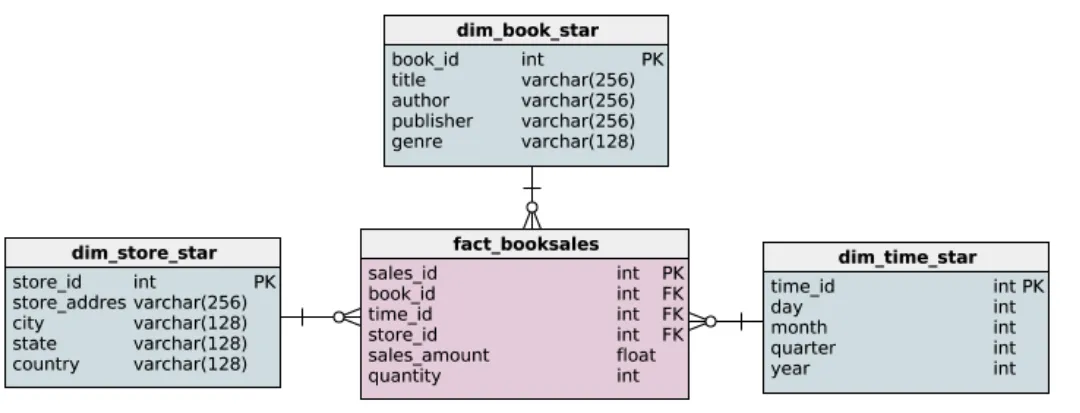
기본 및 외래 키를 제외하고 팩트 테이블에는 판매 금액과 책 수량이 포함됩니다.
위 테이블 구조는 일대 다 관계입니다. 스타 스키마는 위의 테이블처럼 확장 점이 다른 별처럼 보이기에 이러한 이름을 얻었습니다.
Snowflake schema
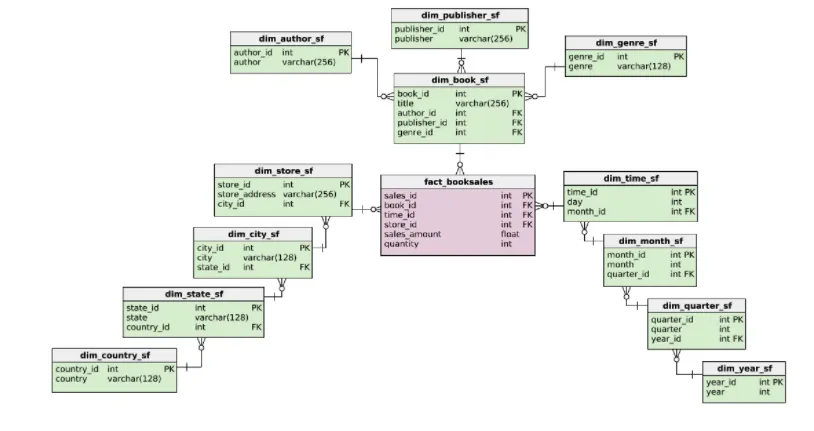
스노우플레이크 스키마는 스타스키마의 확장입니다. 스노우플레이크 스키마는 1차원 보다 큰데, 이는 차원테이블이 정규화(Normalized) 되었기 때문입니다.
Normalization?
정규화는 테이블을 더 작은 테이블로 나누고 관계를 통해 연결하는 기술입니다.
중복성을 줄이고, 데이터 무결성을 높이는 것을 목표로합니다.
- 반복되는 그룹을 식별하고 이를 위한 새 테이블을 만들어서 정규화를 진행합니다.
정규화 예시

다음 테이블이 있을 때, Author, Publisher, Genre는 중복이 될 수 있으므로, 새 테이블을 만들 수 있습니다.
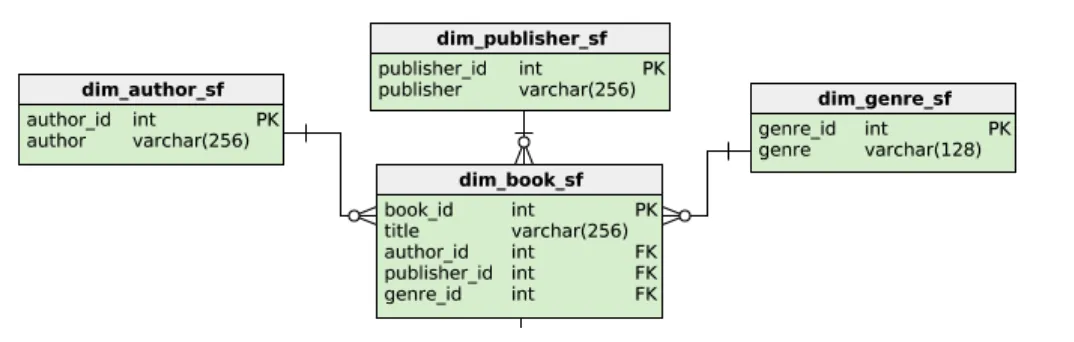
이를 정규화하면 다음과 같은 테이블 구조를 가지게 됩니다.
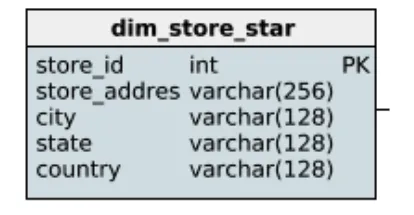
다른 예시로 다음을 정규화 한다면,
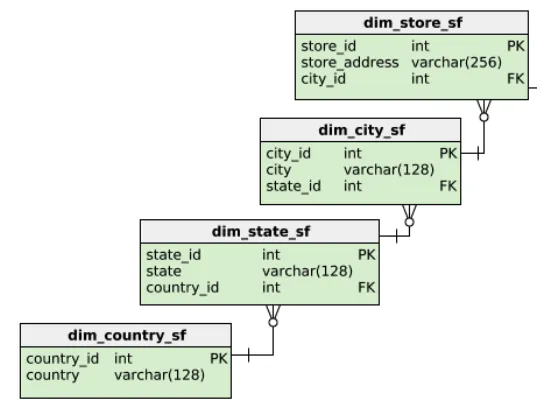
이는 위의 스타 스키마와 다른 모습을 보입니다.
book store example
Octavia E 버틀러의 2018년 4분기 밴쿠버 모든 책의 판매수량을 알고 싶다고 가정할 때,
비정규화 쿼리
비정규화 된 스키마를 쿼리를 실행하면 이를 수행할 수 있습니다.
SELECT SUM(quantity) FROM fact_booksales
-- Join to get city
INNER JOIN dim_store_star on fact_booksales.store_id = dim_store_star.store_id
-- Join to get author
INNER JOIN dim_book_star on fact_booksales.book_id = dim_book_star.book_id
-- Join to get year and quarter
INNER JOIN dim_time_star on fact_booksales.time_id = dim_time_star.time_id
WHERE
dim_store_star.city = 'Vancouver' AND dim_book_star.author = 'Octavia E. Butler' AND
dim_time_star.year = 2018 AND dim_time_star.quarter = 4정규화된 쿼리
SELECT SUM(fact_booksales.quantity) FROM fact_booksales
-- Join to get city
INNER JOIN dim_store_sf ON fact_booksales.store_id = dim_store_sf.store_idINNERJOIN dim_city ON dim_store_sf.city_id = dim_city_sf.city_id
-- Join to get author
INNER JOIN dim_book_sf ON fact_booksales.book_id = dim_book_sf.book_id
INNER JOIN dim_author_sf ON dim_book_sf.author_id = dim_author_sf.author_id
-- Join to get year and quarter
INNER JOIN dim_time_sf ON fact_booksales.time_id = dim_time_sf.time_id
INNER JOIN dim_month_sf ON dim_time_sf.month_id = dim_month_sf.month_id
INNER JOIN dim_quarter_sf ON dim_month_sf.quarter_id = dim_quarter_sf.quarter_id
INNER JOIN dim_year_sf ON dim_quarter_sf.year_id = dim_year_sf.year_id
WHERE dim_city_sf.city = `Vancouver` AND dim_author_sf.author = `Octavia E. Butler` AND dim_year_sf.year = 2018 AND dim_quarter_sf.quarter = 4정규화된 쿼리를 사용할때는, 더 오래걸립니다. 이는 더 많은 테이블을 조인하므로 더 느려집니다.
정규화 하는 이유
정규화는 위의 사례처럼 쿼리도 길어지고, 연산도 많아지지만, 사용하는 이유는 공간을 절약하기 때문입니다.
정규화 된 데이터베이스에 더 많은 테이블이 있는 방식은 보는 것에도 직관적이 않습니다.
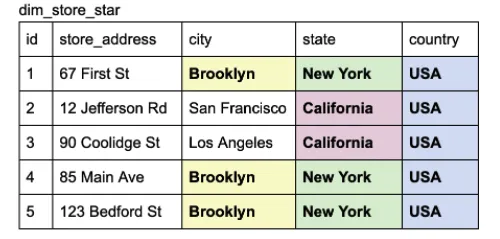
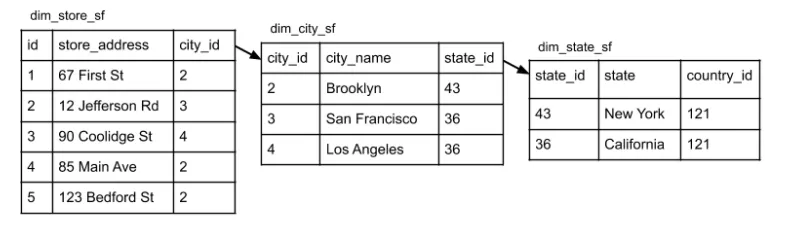
정규화된 테이블 위와 같이 직관적이지 않습니다. 하지만 이를 통해서 중복되는 데이터를 제거할 수 있습니다.
정규화는 설계를 통해 더 나은 데이터 무결성 보장합니다.
무결성 : 데이터의 정확성과 일관성을 유지하고, 데이터에 결손과 부정합이 없음을 보증
- 데이터의 일관성을 유지합니다. ( 데이터 입력은 지저분해 질 수 있으며 때때로 사람들은 필드를 다르게 채울 것 입니다. - California or CA )
- 중복이 줄어들 기 때문에 데이터 수정이 더 안전하고 간단해집니다.
- 테이블이 더 작고, 개체별로 더 많이 구성되므로 데이터베이스 스키마를 변경하기 더 쉽습니다.
장점
- 데이터베이스 유지 관리에 매력적
단점
- 정규화에는 쿼리를 만드는 더 많은 조인이 필요 ( 더 복잡하여 인덱싱 및 데이터 읽기 속도가 느려질 수 있습니다. )
OLTP and OLAP
OLTP는 쓰기 집약적인 의미로 자주 업데이트하고 작성합니다. 정규화는 데이터를 빠르고 일관되게 추가하기를 원하기 때문에 의미있습니다.
OLAP는 데이터에 대한 분석을 실행하기 때문에 읽기 집약적입니다. 즉 더 빠른 읽기 쿼리와 우선 순위를 지정하고 싶습니다.
Normalization
반복된 데이터 그룹을 찾아서 그룹에 대한 새 테이블 만들기
- 정규화의 목표
- 관계형 스키마에서 중복 수준을 줄일 수 있다.
- 스키마 처리단계에서, 중복을 제거하는 메카니즘을 제공한다.
Normal form (NF)
정규화 할 수 있는 범위는 다양합니다. 이를 작은 것부터 큰 것까지 정규화 할 수 있습니다.

1NF rules
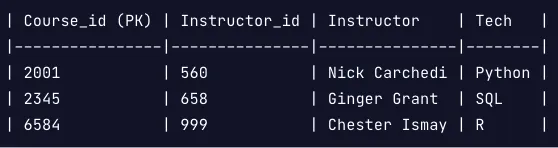
- 1NF를 준수하려면 각 레코드가 고유해야하며, 각 셀은 하나의 값을 보유해야합니다.

모든 행은 고유하지만, course_completed열에는 두 개의 레코드에 둘 이상의 코스가 있습니다. 이를 수정하기 위해서 테이블을 아래와 같이 분할 할 수 있습니다.
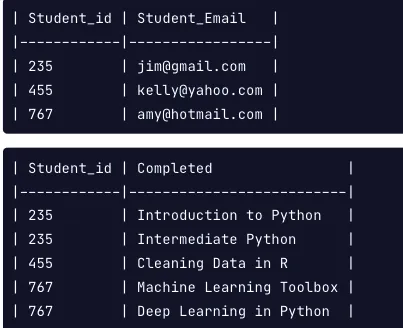
위와 같이 설정하면, 모든 레코드가 고유하고 각 열에 하나의 값이 있습니다.
2NF
- 2NF 는 1NF를 만족해야합니다.
- 그 외에도 기본 키가 하나의 열이면 테이블은 2NF입니다.
- 테이블에 복합 키 ( 기본 키가 둘 이상의 열로 구성된 경우 ) 가 있는 경우 키가 아닌 각 열은 모든 키에 종속되어야합니다.

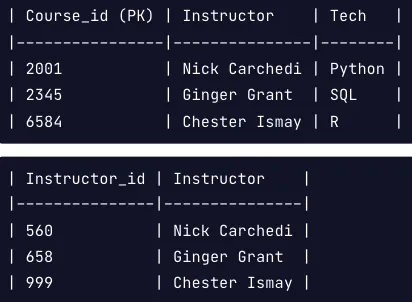
위의 테이블은 합성 기본 키로 학생아이디와, 코스아이디가 있습니다. 이후 다른 열과 이 두 키에 대한 종속성을 검토합니다.
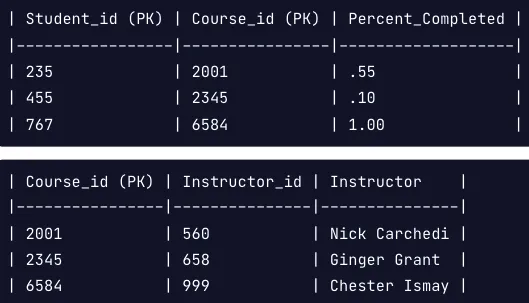
이를 2NF로 변경하기 위해서는, 두개의 새 테이블로 분할합니다.
3NF
- 3NF는 2NF를 충족해야 합니다.
- 3NF는 종속성을 허용하지 않습니다. 즉, 기본 키가 아닌 열은 다른 기본 키가 아닌 열에 의존 할 수 없습니다.
위의 테이블을 이용하면, 종속성이 없으며, 복합 기본 키가 없기 때문에 2NF를 충족합니다.
Data anomalies
충분히 정규화되지 않은 데이터베이스는 업데이트, 삽입 및 삭제라는 세 가지 유형의 이상 오류가 발생하기 쉽습니다.
- Update anomaly
- 업데이트 이상은 중복으로 데이터베이스를 업데이트 할 때 발생할수 있는 데이터 불일치입니다.
- 확장함에 따라 이러한 중복은 추적하기 더 어렵습니다.
- Insert anomaly
- 삽입 이상은 속성 누락으로 인해 새 레코드를 추가 할 수 없는 경우입니다.
- 동일한 테이블에있는 열 간의 종속성은 의도하지 않게 테이블에 삽입 할 수 있는 항목을 제한합니다.
- Deletion anomaly
- 레코드를 삭제하고 다른 데이터를 삭제하면 삭제 이상이 발생합니다.
데이터 베이스가 정규화 될수록 이러한 문제가 발생할 가능성이 줄어 듭니다.
대부분의 3NF 테이블에는 업데이트, 삽입 및 삭제 이상이 있을 수 없습니다.
Database views
데이터 베이스에서, 원하는 모든 데이터를 선택하여, 그들을 사용자 정의하여 나타낸 것이다. 관계형 데이터베이스의 관계 모델의 관계의 일종인 도출 관계에 해당하며, 여러 테이블 또는 뷰의 데이터를 연결하여 조합할 수 있다.
- 기본적으로 뷰는 물리적 스키마의 일부가 아닌 가상 테이블입니다.
- 뷰는 실제 메모리에 저장되지 않습니다.
- 뷰의 데이터는 동일한 데이터베이스의 테이블에있는 데이터에서 가져옵니다.
- 뷰가 형성되면 일반 테이블처럼 쿼리 할 수 있습니다.
- 뷰의 장점은, 일반적인 쿼리를 다시 입력 할 필요가 없다는 것입니다.
- 데이터베이스의 스키마를 변경하지 않고 가상 테이블을 추가 할 수 있습니다.
Creating a view
CREATE VIEW view_name AS
SELECT col1, col2
FROM table_name
WHERE condition;쿼리를 가져와 그 앞에 행을 추가하여 뷰 이름을 지정합니다.
Creating a View (example)
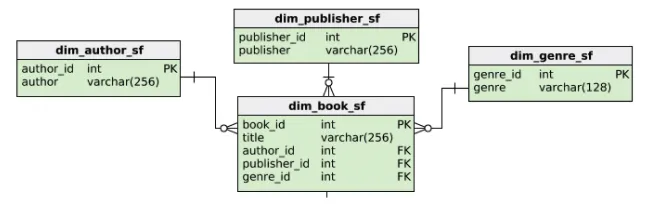
회사의 분석가가 종종 공상과학 장르에 대한 분석을 실행한다고 가정
워크 플로를 돕기 위해, 특별히 뷰를 반들고 싶습니다.
CREATE VIEW scifi_books AS
SELECT title, author, genre
FROM dim_book_sf
JOIN dim_genre_sf ON dim_genre_sf.genre_id = dim_book_sf.genre_id
JOIN dim_author_sf ON dim_author_sf.author_id = dim_book_sf.author_id
WHERE dim_genre_sf.genre = 'science fiction'위의 코드를 실행한 뒤, 뷰를 쿼리할 수 있습니다.
SELECT * FROM scifi_books뷰를 통해 생성된 테이블은 실제 메모리가 있는 테이블이 아닙니다.
Viewing biews
SELECT * FROM INFORMATION_SCHEMA.views;데이터베이스에서 뷰를 추적하는 것은 중요합니다. 데이터베이스의 모든 뷰를 가져 오려면 INFORMATION_SCHEMA에서 쿼리를 실행할 수 있습니다. (PostgreSQL)
이를 실행하면 많은 뷰들이 보이는데, DBMS에 내장되어 있는 뷰들이 있기에 그렇습니다.
SELECT * FROM information_schema.views
WHERE table_schema NOT IN ('pg_catalog', 'information_schema')시스템뷰를 제외하고 생성한 뷰를 가져 오려면 위의 쿼리를 사용합니다.
View의 장점
- 최소한의 쿼리 문을 제외하고는 어떤 스토리지도 차지하지 않습니다.
- 액세스 제어의 한 형태로 작동 ( 사용자에게 액세스 권한을 부여하는 대신, 민감한 정보가 있을 수 있는 열에 대해서는 뷰를 통해 볼 수 있는 내용을 제한 할 수 있습니다. )
- 쿼리의 복잡성을 감춥니다.
Creating moe complex views
뷰는 선택한 만큼 복잡하고 창의적일 수 있다는 점을 알아야합니다.

물론 사용한 함수만큼, 뷰를 불러오는 시간이 길어진다는 것은 알아야합니다.
Grating and revoking access to a view
- 사용자 권한을 부여하고 제거하기 위해 SQL GRANT 및 REVOKE명령을 사용합니다.
- 먼저 GRANT 및 REVOKE 명령 뒤에 관련 권한을 나열합니다.
Privileges : SELECT, INSERT, UPDATE, DELETE, etc
-
그 이후, 개체와 역할을 지정합니다.
-
부여 및 취소에 각각 To절과 FROM절을 사용합니다.
GRANT UPDATE ON ratings TO PUBLIC;REVOKE INSERT ON films FROM db_usersUpdating a view
UPDATE films SET kind = 'Dramatic' WHERE kind = 'Drama';사용자는 필요한 권한이 있는 경우 뷰를 업데이트 할 수 있습니다.
하지만 실제 테이블이 아닌데 어떻게 ?
업데이트를 실행 할 때, 뷰 뒤에서 테이블을 업데이트합니다.
따라서, 특정 뷰만 업데이트 할 수 있습니다. 업데이트 가능한 기준이 있는데, 이 기준은 사용중인 SQL 유형을 따릅니다.
일반적으로 뷰는 하나의 테이블로 구성되어야하며, window or aggregate 함수에 의존 할 수 없습니다.
Inserting into a view
INSERT INTO films (code, title, did, date_prod, kind)
VALUES ('T_601', 'Yojimbo', 106, '1961-06-16', 'Drama')Insert 명령은 Update 명령과 유사합니다. 뷰에 Insert 명령을 실행하면, 실제로 그 뒤에있는 테이블에 삽입합니다.
- 일반적으로 뷰를 통해 데이터를 수정하지 마세요. 읽기 전용 목적으로만 사용하는 것이 좋습니다.
Dropping a view
DROP VIEW view_name [ CASCADE | RESTRICT ];Drop 명령을 위해 알아야하는 것으로 CASCADE와 RESTRICT가 있습니다.
뷰가 더 큰 데이터베이스의 다른 뷰에 의해 빌드되는 것은 흔한일인데,
- RESTRICT 매개 변수는 기본값으로, 다른 오브젝트가 의존하는 뷰를 삭제하려고하면 오류를 리턴합니다.
- CASCADE 매개 변수는 뷰와 연결된 모든 개체를 삭제합니다.
Redefining a view
CREATE OR REPLACE VIEW view_name AS new_query뷰가 정의된 쿼리를 변경하고 싶다고 가정하면, 이를 위해 CREATE OR REPLACE 명령을 사용합니다.
view_name이 존재하면 지정된 new_query로 대체됩니다.
제한사항 - 새 쿼리는 기존 쿼리와 동일한 열 이름, 열 순서 및 열 데이터 형식을 생성해야합니다. 해당 조건이 충족되는 한 열 출력은 다를 수 있습니다.
위 조건을 충족하면 마지막에 새 열이 추가 될 수 있습니다. 이러한 조건을 충족하지 못한다면, 기존 뷰를 삭제하고 새 뷰를 만드는 것이 좋습니다.
Altering a view
보조 속성을 변경 할 수 있습니다.

두개의 View 타입
- 비 구체화 뷰
- 구체화된 뷰
뷰라는 용어는 명확하게 접하면, 비 구체화 뷰를 가르킬 가능성이 큽니다.
Materialized views ( 구체화된 뷰 )
- 구체화된 뷰는 물리적으로 구체화 된 반면 비 구체화 된 뷰는 가상 상태로 유지됩니다.
- 비 구체화된 뷰는 질의를 저장하는 대신 구체화 된 뷰는 결과를 저장합니다.
- 이러한 쿼리 결과는 디스크에 저장됩니다.
- 이것은 쿼리가 뷰를 통해 미리 계산된다는 것을 의미합니다.
- 구체화 된 뷰는 프롬프트가 표시되면 새로 고쳐 지거나 다시 구체화됩니다.
- 새로 고치거나 재 구체화하면 쿼리가 실행되고 저장된 쿼리 결과가 업데이트됩니다.
구체화된 뷰를 사용하면 좋은 경우
- 실행 시간이 긴 쿼리가 있는 경우 구체화 된 뷰가 좋습니다. ( 데이터가 마지막 뷰를 고쳤을 때, 최신 상태 )
- 따라서 자주 업데이트되는 데이터는 오래된 데이터에 대해 분석이 자주 실행되기 때문에 구체화된 뷰를 사용하면 안됩니다.
- 구체화 된 뷰는 데이터 웨어 하우스에서 유용합니다. ( 분석에 초점을 맞췄기에, 오래된 데이터에 대한 걱정이 줄어듭니다. )
- 동일한 쿼리가 데이터웨어 하우스에서 실행되는 경우가 많으면 계산 비용이 합산 될 수 있습니다.
구체화 뷰 생성 방법 ( materialized views )
CREATE MATERIALIZED VIEW my_mv AS SELECT * FROM existing_table;REFRESH MATERIALIZED VIEW my_mv;SQL문에 MATERIALIZED를 지정하는 것을 제외하고는, 비 구체화 된 뷰와 동일합니다.
갱신하는 코드는 cron을 이용합니다.
Managing dependencies
비 구체화 된 뷰와 달리, 종속성이있을 때, 구체화 된 뷰를 새로 관리해야합니다.
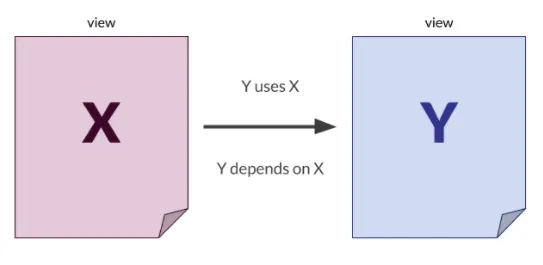
Y는 쿼리에서 X를 사용합니다. 따라서, Y는 X에 따라 달라집니다.
X에 더많은 시간이 소요되는 쿼리가 있다고 가정할 때, X의 새로 고침이 완료되기 전에 Y가 새로고쳐지면, Y는 오래된 데이터를 가지게 됩니다.
이렇게 하면 뷰를 새로 고칠 때 종속성 체인이 생성됩니다. ( 새로 고침시기를 예약하는 것은 간단하지 않습니다. ) - 쿼리 시간과 종속성을 고려할 때 동시에 고치는 것은 가장 효율적이지 않습니다.
이를 위해서는 Airflow와 같은 방향성 비순환 그래프를 사용하면 됩니다.
데이터베이스 역할
- 규칙은 데이터베이스 액세스 권한을 관리하는데 사용됩니다.
- 데이터 베이스 역할은 다음 정보를 포함하는 엔티티입니다.
- 로그인 할 수 있는지?, 데이터베이스를 생성할 수 있는지?, 테이블을 작성할 수 있는지?
- 암호와 같은 클라이어늩 인증 시셈과 상호 작용
- 역할은 한 명 이상의 사용자에게 할당 될 수 있습니다.
- 역할은 전역이므로 클러스터의 모든 개별 데이터베이스에서 역할을 참조 할 수 있습니다.
Create role
CREATE ROLE data_analyst;위의 명령을 사용해서 data_analyst 역할을 생성 할 수 있습니다.
역할을 생성 할 때 이 정보의 일부를 설정할 수도 있습니다.
CREATE ROLE intern WITH PASSWORD 'PasswordForIntern' VALID UNTIL '2020-01-01';위와 같이 역할을 생성하고 유효 날짜 속성을 지정 합니다.
CREATE ROLE admin CREATEDB;다음 속성을 이용해서 관리자 역할을 생성합니다.
ALTER ROLE admin CREATEROLE;ALTER 키워드를 이용해서 관리자 역할을 만들 수 있습니다.
승인, 거절 roles
특정 액세스 제어 권한을 부여하려면 GRANT 및 REVOKE를 사용합니다.
GRANT UPDATE ON ratings TO data_analyst;REVOKE UPDATE ON ratings FROM data_analyst;Users and groups
역할은 사용자 역할 또는 그룹 역할이 될 수 있습니다.
- User roles
- Group roles
역할은 다른 역할의 구성원 일 수 있으며 더 큰 역할을 그룹이라고 합니다.
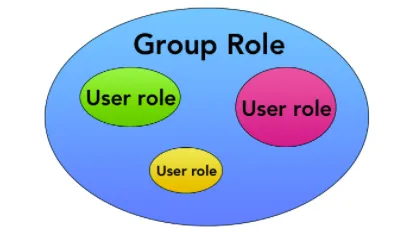
Group role
CREATE ROLE data_analyst;User role
CREATE ROLE alex WITH PASSWORD 'PasswordForIntern' VALID UNTIL '2020-01-01';data_analyst 역할을 그룹 역할로 생각하면 모든 데이터 분석가가 동일한 수준에 액세스 권한을 갖기를 원합니다.
GRANT data_analyst TO alex;사용자 역할 alex를 그룹 역할 data_analyst에 추가하려면 위의 코드처럼 사용합니다.
REVOKE data_analyst FROM alex;제거하는 것은 REVOKE를 사용하면 됩니다.
roles의 장단점
장점
- 유저가 사라져도, 역할은 살아있다.
- 유저가 계정을 얻기 전에도 만들 수 있다.
- 데이터베이스 관리자는 시간을 절약 할 수 있다.
단점
- 역할은 개인에게 너무 많은 엑세스 권한을 부여합니다.
- 역할 및 액세스 수준에 주의하고 염두에 두어야합니다.
Partition (분할)
- 테이블이 커지면 쿼리가 느려지는 경향이 있습니다. 인덱스를 올바르게 설정 한 경우에도 이러한 인덱스가 너무 커져서 메모리에 맞지 않을 수 있습니다.
- 특정 시점에서 테이블을 여러 개의 작은 부분으로 분할하는 것이 합리적 일 수 있습니다.
Data modeling refresher
데이터 모델링을 보면,
- Conceptual data model
- Logical data model
논리적 데이터 모델은, 액세스하거나 업데이트 할 데이터는 여전히 동일합니다. ( 차이점은 데이터를 여러 물리적 엔티티에 배포한다는 것입니다. )
- Physical data model
파티셔닝은 위 세개의 모델 중 3. Physical data model에 적합합니다.
Vertical partitioning
파티셔닝 유형은 두가지의 파티셔닝이있는데
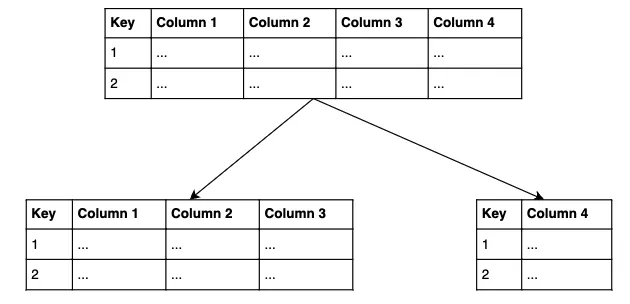
위의 분할은 수직 분할입니다. 이전에 정규화로 분할된 상태에서 수직 분할은 한단계 더 나아가 테이블을 분할합니다.
이미 완전히 정규화 된 경우에도 열에 의해 수직으로 분할됩니다.
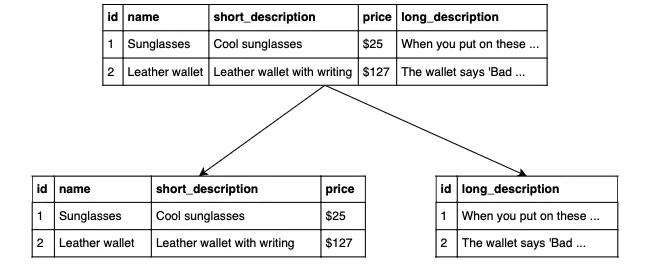
분할 뒤, 공유 키를 통해 연결 할 수 있습니다. 긴텍스트를 포함한 열을 검색에 사용하지 않는다면, 더 적은 데이터를 스캔하므로 쿼리시간이 향상됩니다.
Horizontal partitioning
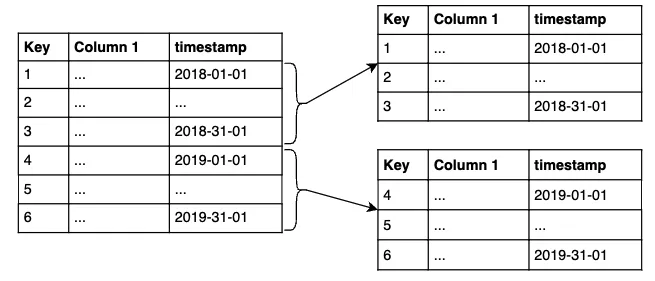
수평 분할은 다음과 같이 row를 기준으로 자릅니다.

수평 분할의 장단점
장점
- 인덱스의 많이 사용되는 부분이 메모리에 들어갈 가능성을 높입니다.
- 거의 액세스하지 않는 파티션을 더 느린 미디어로 이동할 수도 있습니다.
- OLAP는 OLTP 의 이점을 누릴수 있습니다.
단점
- 새 테이블을 만드록 데이터를 복사하는 등의 과정이 존재한다.
- 항상 동일한 유형을 설정할 수 없다. ( 프라이머리 키로 한계가 있다? )
Relation to sharding
파티셔닝을 한 단계 더 나아가 여러 머신에 분산 시킬 수 있습니다.
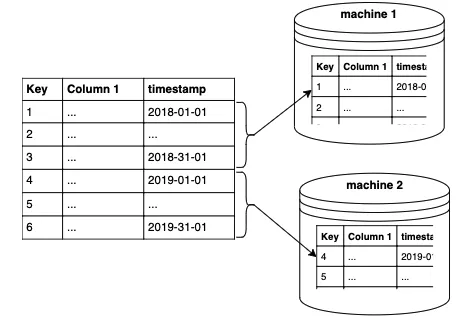
수평 분할을 적용하여 여러 컴퓨터에 테이블을 분산하는 것을 샤딩이라고하는데 이것을 이용하여 대규모 병렬 처리를 가능하게 합니다.
What is data integration
데이터 통합은 다양한 소스, 형식, 사용자에게 해당 데이터에 대한 번역되고 통합된 보기를 제공하는 기술입니다.
Business case example
- 360 -degree 고객 관측
- 기업 인수
- 레거시 시스템 ( 과거 오래된 데이터 )
다음과 같은 케이스들로 인해 데이터를 통합할 수 있습니다.
최종 목적은, 통합 데이터 모델을 사용하여 대시보드를 제작하는 것입니다. ( 일일 판매 그래프, 추천 엔진 )
최종 데이터 모델은 사용 사례에 맞게 충분히 빨라야합니다.
필요한 정보는 이러한 데이터 소스에 보관됩니다.
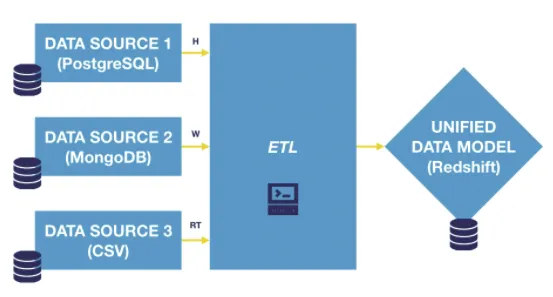
얼마나 자주 데이터를 업데이트 할 것인가? (경우에 따라 적절하게 설정해야함)
소스는 서로 다른 형식을 가지므로, 통합할 수 있는지 확인해야합니다. (트랜스폼 과정 필요)
데이터 병합 툴 선택
- 모든 데이터 소스에 연결할 수 있을만큼 유연성이 있는지 확인
- 신뢰할 수 있는지 ( 유지 관리 가능 한지 )
- 데이터 볼륨과 소스의 증가에 대응 할수 있는지 ( 확장성 )
경고(알림)
데이터가 ETL과정 중 손상되면 시스템에 의해 알아야 합니다.
보안
데이터 액세스가 제한되는 경우 통합 데이터 모델에서 제한을 유지해야합니다.
데이터 거버넌스
데이터 거버넌스 목적을 위해 계보를 고려해야함
감사를 수행하려면 데이터의 출처와 사용 위치를 항상 알아야합니다.
Database Management System (DBMS)
- DBMS는 데이터베이스를 만들고 유지하기 위한 시스템 소프트웨어입니다.
- DBMS는 데이터베이스 스키마를 정의하는 세가지 중요한 측면을 관리합니다.
- Data
- Database schema
- Database engine
- DBMS는 데이터베이스와 최종 사용자 또는 응용 프로그램 간의 인터페이스 역할을 합니다.
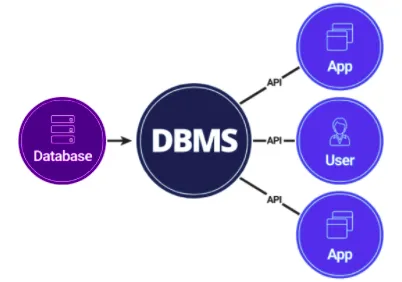
DBMS types
- DBMS 선택은 필요한 데이터베이스 유형에 따라 결정됩니다.
- Two types:
- SQL DBMS
- NoSQL DBMS
SQL DBMS
- 관계형 데이터베이스라고 불림
- 시스템은 관계형 데이터 모델을 기반으로 하는 일종의 DBMS입니다.
- RDBMS는 일반적으로 데이터 관리 및 엑세스를 위한 SQL을 사용합니다.
- SQL Server, PostgerSQL, ORACLE
- RDBMS를 고려하는 두가지 이유
- 미리 정의된 스키마의 이점을 얻을 수 있는 구조화되고 변경되지 않은 데이터로 작업할 때
- 회계 시스템같이 오류의 여지를 남기지 않고 모든 데이터가 일관성이 있어야하는 경우
NoSQL DBMS
- 관계형 데이터베이스보다 훨씬 덜 구조적이며 테이블 중심이 아닌 문서 중심
- NoSQL 데이터베이스의 데이터는 잘 정의된 행과 열에 맞지 않아도됩니다.
- NoSQL은 명확한 스키마 정의없이 빠른 데이터 증가를 경험하는 기업에게 적합
- NoSQL은 SQL DBMS보다 휠씬 더 많은 유연성을 제공하며 대량의 데이터를 분석하거나 다양한 데이터 구조를 관리해야하는 기업에게 적합
- key-value store, documents store, columnar database, graph database
NoSQL - key-value store
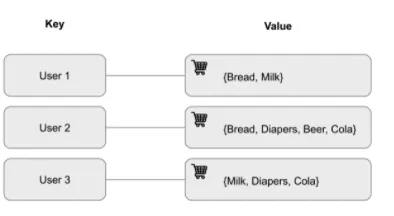
- key-value 데이터베이스는 키와 밸류의 조합을 저장합니다.
- 키는 관련 값을 검색하는 고유 식별자 역할을 하며, 밸류는 정수 또는 문자열과 같은 간단한 개체부터 JSON 구조와 같은 더 복잡한 개체까지 다양합니다.
- 웹 애플리케이션에서 세션 정보를 관리하늗네 자주 사용
- 대표적으로 redis가 있음
NoSQL - document store
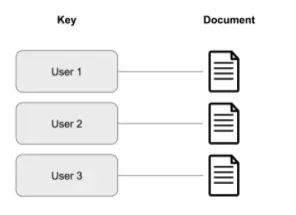
- Document store는 각각 값에 해당하는 키로 구성된다는 점에서 키밸류와 유사
- 차이점은, 저장된 값이 문서구조
- 블로그 및 비디오 플랫폼과 같은 콘텐츠 관리 응용프로그램을 위한 훌륭한 선택임
- 애플리케이션이 추적하는 각 엔티티는 단일 문서로 저장 할 수 있음
- 대표적으로 MongoDB
NoSQL - columnar database
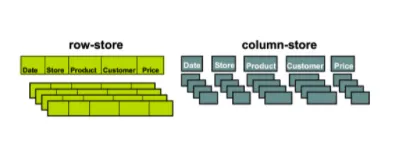
- 열을 테이블로 그룹화하는 대신 데이터베이스는 각 열을 시스템 저장소의 별도 파일에 저장
- 확장성과 규모가 더 빠른 데이터베이스가 가능
- 속도가 중요한 빅 데이터 분석을 위해 컬럼 형 데이터베이스 이용
- 대표적으로 Cassandra
NoSQL - graph database
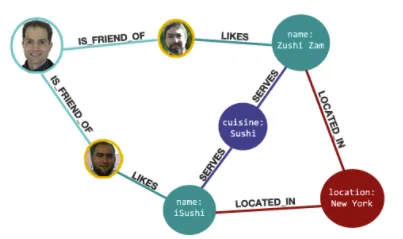
- 데이터는 서로 연결되어 있고 그래프로 표현됨 ( 다소 복잡 )
- 대부분의 소셜 네트워크에서 사용되며, 행동에 따라 무엇이든 추천하는 웹사이트 많습니다.
- 대표적으로 neo4j