TL;DR
“Dify로 Agent 시스템을 구축할 수 있을까?”
결론부터 말하면, Dify는 LLM 애플리케이션 개발에 특화된 강력한 노코드 플랫폼이다. 특히 RAG 파이프라인 구축, 빠른 프로토타이핑, 다양한 모델 연동에서 탁월한 생산성을 보여준다.
다만 엔터프라이즈 수준의 운영 자동화, 세밀한 거버넌스, 대규모 트래픽 처리가 필요한 환경에서는 구조적 한계가 존재한다. Dify는 AgentOps를 대체하는 플랫폼이 아니라, AgentOps 이전 단계에서 실험과 검증 속도를 높여주는 가속기로 이해하는 것이 정확하다.
배경: 왜 Dify에 주목하는가
Agent 기반 시스템이 빠르게 확산되면서, 현업에서 동일한 질문이 반복된다.
“이 정도 Agent 구성이라면 굳이 복잡한 플랫폼을 구축할 필요 없이, Dify 같은 노코드 툴로 충분하지 않을까?”
이 글은 Dify를 직접 사용하며 느낀 경험을 바탕으로, 노코드 LLM 플랫폼이 어디서 빛나고 어디서 한계에 부딪히는지 정리한다.
Agent 플랫폼의 두 가지 접근법
현재 Agent 시스템 구축 방식은 크게 두 갈래로 나뉜다.
Code-first 아키텍처는 Python이나 TypeScript 기반으로 명시적인 상태 관리, 테스트, 배포, 관측성을 갖춘다. 자유도가 높고 운영 안정성 확보에 유리하다.
No-code / Low-code 워크플로우는 시각적 UI로 구성하며, 빠른 실험과 낮은 진입장벽이 강점이다. 비개발자도 접근 가능하다.
Dify는 후자 중에서도 LLM 애플리케이션에 특화된 대표적인 오픈소스 플랫폼이다.
Dify란 무엇인가

Dify는 LangGenius에서 운영하는 오픈소스 AI 애플리케이션 플랫폼이다. Agent, RAG, Workflow 구성에 초점을 맞추고 있다.
n8n이나 Make 같은 범용 자동화 툴과 달리, Dify는 LLMOps에 특화된 플랫폼이다. 프롬프트 관리, 모델 라우팅, 데이터셋 관리, 평가 루프 등 LLM 앱 개발에 필요한 기능을 하나의 플랫폼에서 제공한다.
가격 및 제공 방식
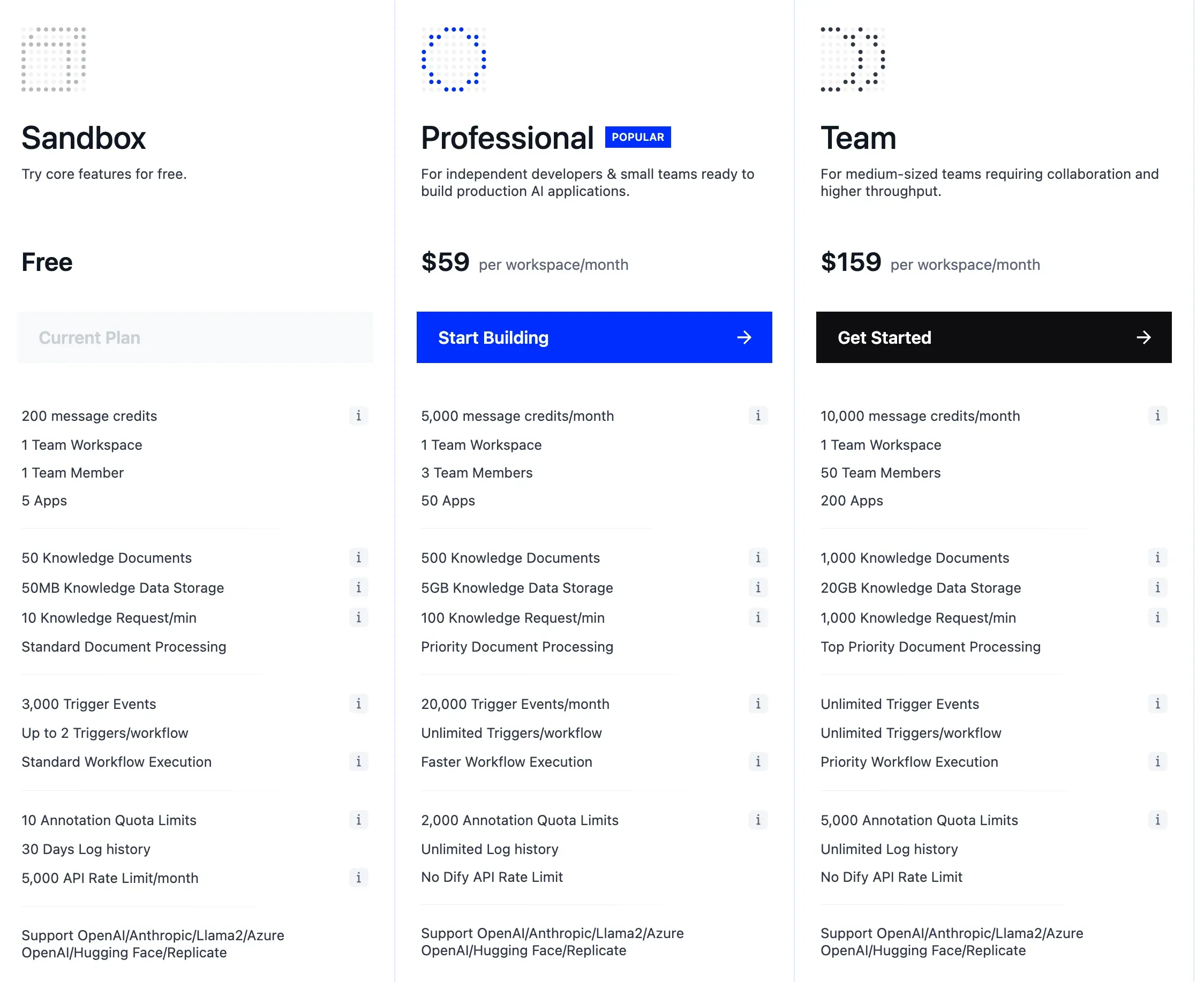
Dify는 **Cloud(Managed)**와 Self-hosted(OSS) 두 가지 방식을 제공한다.
Cloud 버전은 Sandbox(무료), Professional($59/월), Team($159/월) 플랜으로 구성된다. Self-hosted는 오픈소스로 무료 사용이 가능하며, 데이터 주권과 컴플라이언스가 중요한 기업에 적합하다. 다만 멀티 유저 제한 등 팀 단위 운영에는 일부 제약이 있다.
Dify의 핵심 강점
1. LLMOps 특화 플랫폼
Dify는 범용 자동화 툴이 아니라 LLM 앱 개발에 특화된 플랫폼이다. 프롬프트 버전 관리, 모델 라우팅, 평가(Evaluation), 데이터셋 관리 등 LLM 앱 라이프사이클 전반을 지원한다. n8n이나 Make에서는 별도 구현이 필요한 기능들이 기본 제공된다.
2. 모델 불가지론(Model-agnostic) 아키텍처
OpenAI, Anthropic은 물론 Llama, Mistral 등 오픈소스 모델, Ollama를 통한 로컬 모델까지 다양한 프로바이더를 지원한다. 모델 전환과 라우팅이 간편해서, 비용 최적화나 성능 비교 실험에 유리하다.
3. RAG 파이프라인 내장
외부 도구 없이 데이터 수집, 청킹, 임베딩, 검색, 리랭킹까지 End-to-End RAG 파이프라인을 구축할 수 있다. 이 부분은 Dify의 가장 강력한 차별점이다.
4. 오픈소스 + Self-hosting
Self-hosted 배포가 가능해서 데이터 주권, 보안 컴플라이언스, 커스터마이징이 필요한 엔터프라이즈 환경에 적합하다. 온프레미스 배포로 민감한 데이터를 외부로 노출하지 않을 수 있다.
5. 다양한 배포 옵션
워크플로우 완성 후 API, 웹 앱, 챗봇 위젯, iframe 임베드 등 다양한 형태로 즉시 배포할 수 있다. 프로토타입에서 MVP까지의 전환이 매우 빠르다.
Dify가 적합한 사용 사례
Dify는 다음과 같은 상황에서 특히 효과적이다.
RAG 기반 챗봇/코파일럿 구축 시 Dify의 내장 Knowledge 기능이 빛난다. 별도의 벡터 DB 설정 없이 빠르게 검증할 수 있다.
내부 지식 어시스턴트 개발에도 적합하다. Self-hosting으로 데이터를 내부에 유지하면서 사내 문서 기반 Q&A 시스템을 구축할 수 있다.
LLM 모델 비교 실험이 필요할 때 모델 전환이 간편해서 여러 모델의 성능과 비용을 빠르게 비교할 수 있다.
비개발자의 AI 실험 환경으로도 훌륭하다. PM, 기획자, 도메인 전문가가 직접 프로토타입을 만들어볼 수 있다.
워크플로우 기능 분석
Dify의 워크플로우는 n8n, Make 등 기존 자동화 툴과 유사한 방식으로 동작한다.
앱 생성 시 Workflow, Chatflow, Chatbot, Agent, Text Generator 중 하나를 선택할 수 있다.
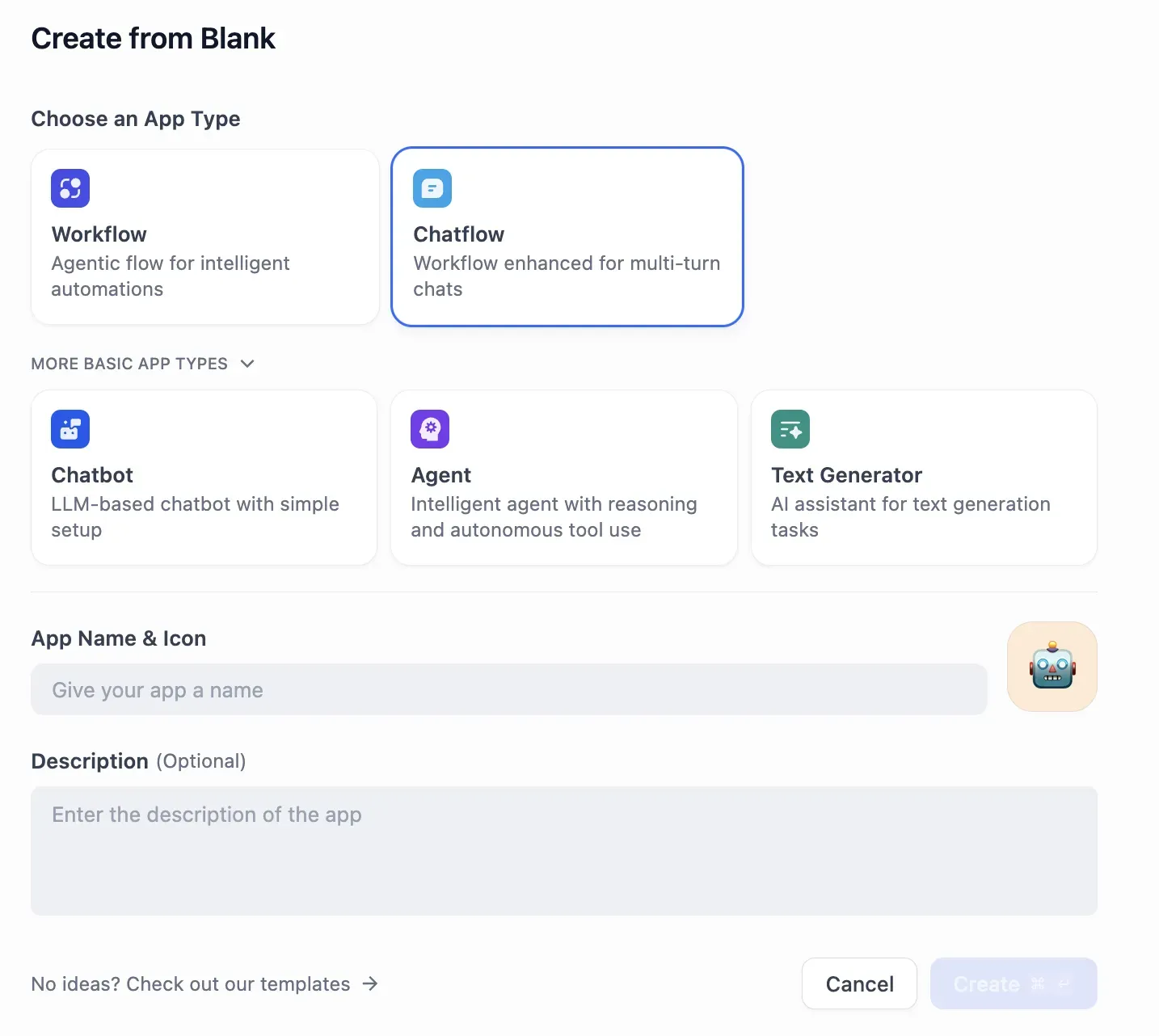
워크플로우 편집 화면은 직관적인 노드 기반 UI를 제공한다.
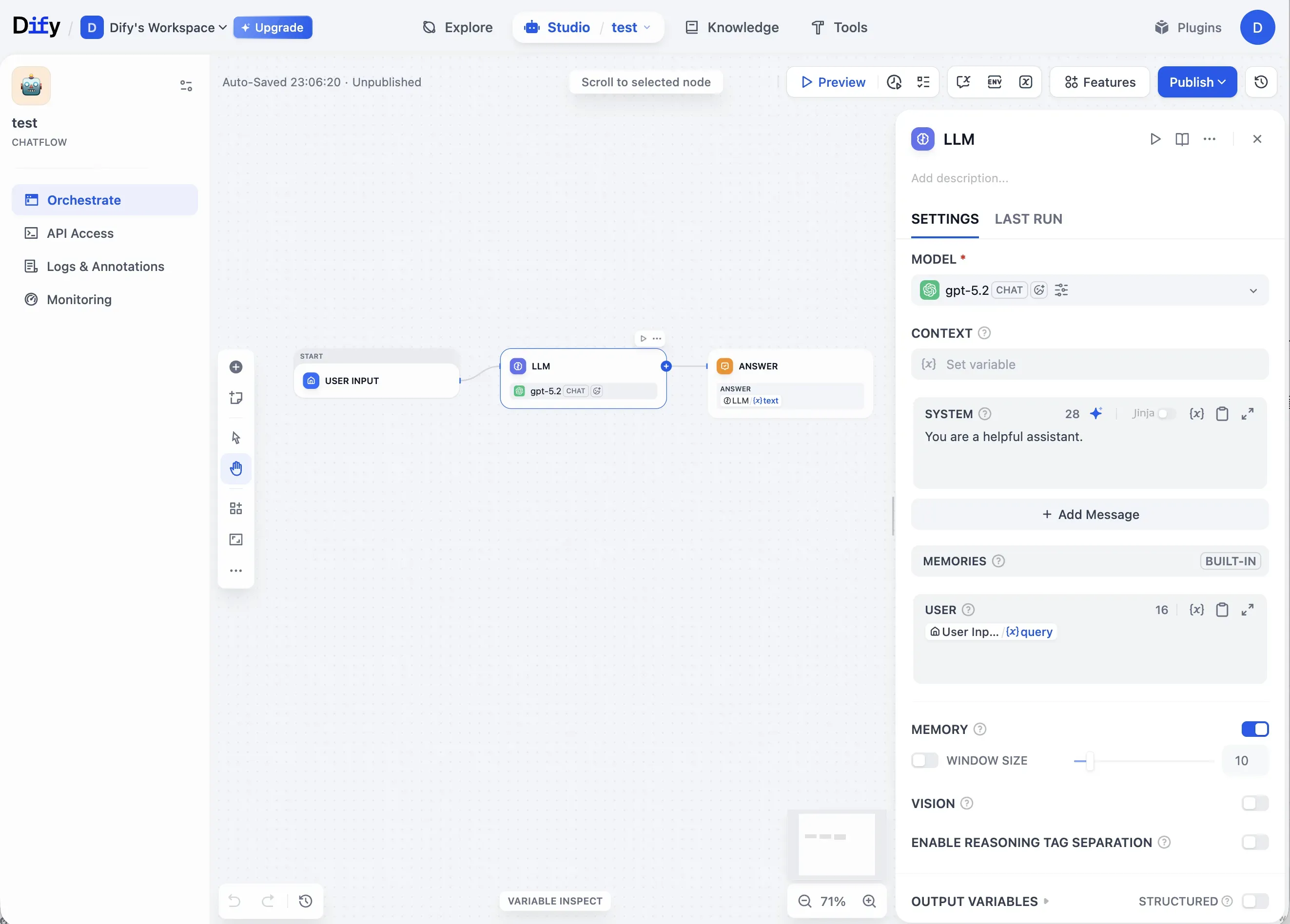
직관적인 UI 덕분에 PoC 단계에서 빠른 실험이 가능하다. Preview 기능으로 즉각적인 검증이 되고, API, Chatbot, Embed 등 다양한 배포 옵션도 제공한다.
Preview 버튼 하나로 즉시 실행 결과를 확인할 수 있다. 코드 작성 없이 빠른 피드백 루프를 구성할 수 있어 PoC 단계에서 특히 유용하다.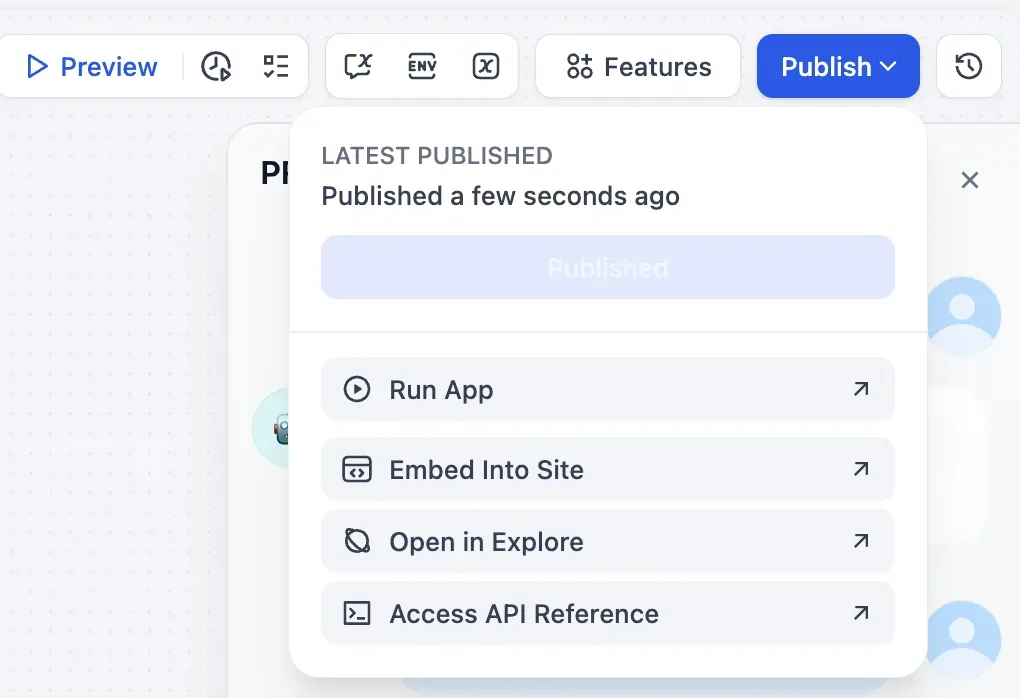
워크플로우 완성 후에는 Run App, Embed Into Site, API Reference 등으로 즉시 배포할 수 있다.
iframe 임베드나 챗봇 위젯 형태로 웹사이트에 쉽게 통합 가능하다. 프로토타입에서 실제 서비스까지의 전환이 빠른 점은 Dify의 명확한 강점이다.
워크플로우의 한계
다만 조건 분기와 상태가 복잡해질수록 가독성이 저하된다. 유지보수 비용도 증가한다. 결국 if/else 로직을 UI로 표현한 형태라는 본질적 한계가 존재한다.
일정 복잡도를 넘어서면 “코드로 작성하는 편이 낫다”는 결론에 도달하게 된다.
RAG 파이프라인: Dify의 가장 강력한 영역
Dify에서 가장 인상적인 부분은 Knowledge(RAG) 파이프라인이다.
PDF, PPT 파일 업로드 시 LLM 기반 OCR 처리가 가능하고, Chunk 설정 자유도가 높다. Chunk Preview로 결과를 미리 확인할 수 있으며, Top-k와 Cosine Similarity 기반 검색을 지원한다. 외부 벡터 DB나 별도 파이프라인 구축 없이 End-to-End RAG를 빠르게 검증할 수 있다는 점이 큰 강점이다.
Chunk 설정
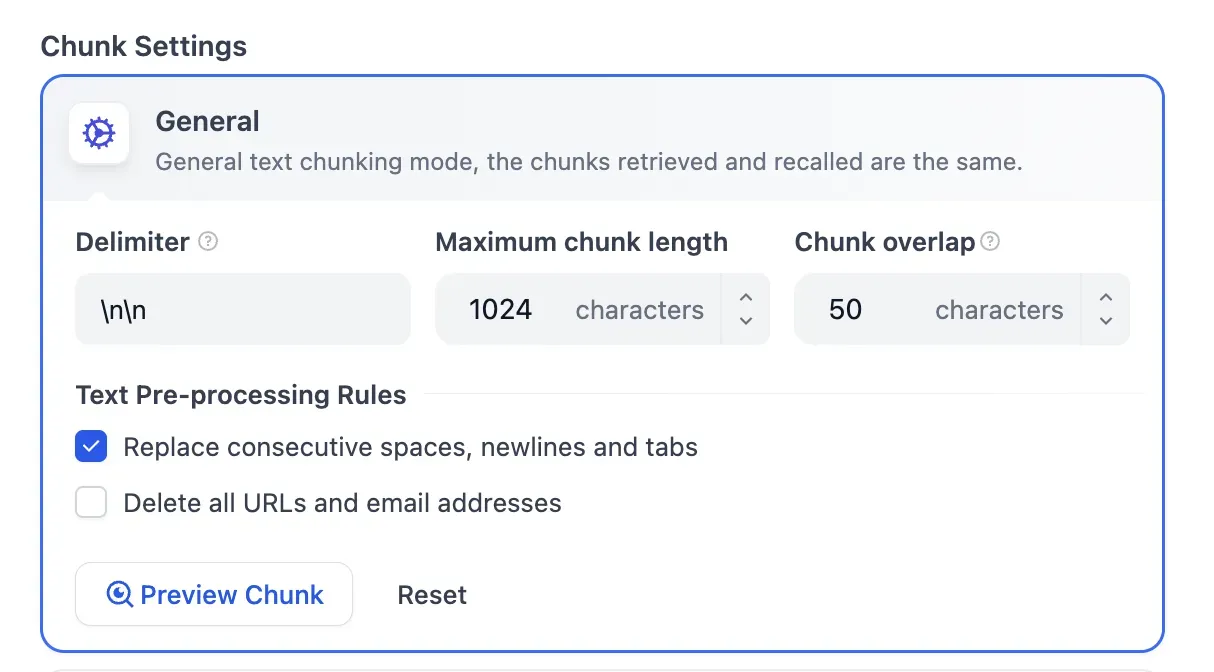
Delimiter, Maximum chunk length, Chunk overlap 등을 세밀하게 조정할 수 있다. 텍스트 전처리 규칙도 커스터마이징 가능하다.
Chunk Preview

문서 업로드 후 실제 청크 분할 결과를 미리 확인할 수 있다. RAG 품질 튜닝에 필수적인 기능이다.
이 부분은 참 매력적인 부분인 것 같다. 내용을 확인하면서 적절한 값을 설정할 수 있다.
Retrieval 설정
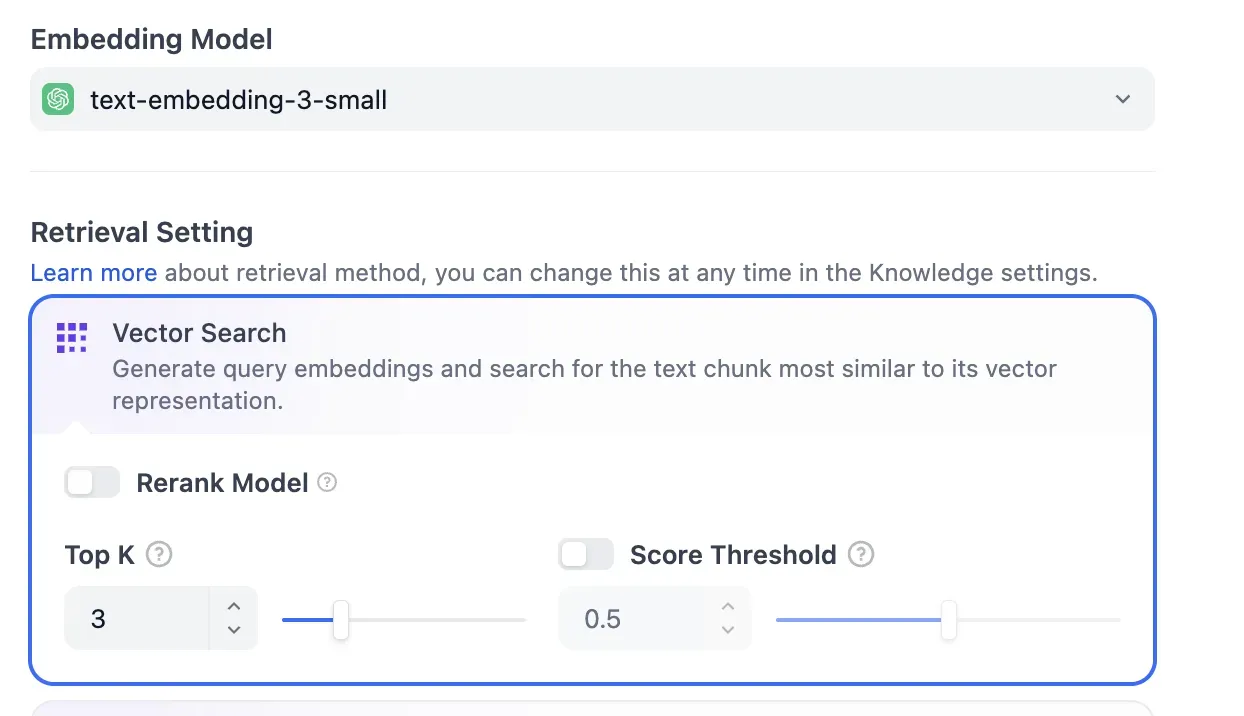
Embedding Model 선택, Vector Search 옵션, Rerank Model, Top K, Score Threshold 등 검색 파라미터를 직관적으로 조정할 수 있다. 이 부분은 코드로 짜는 것과 유사하다고 느껴진다.
RAG의 구조적 제약
그러나 Dify에서 생성한 Knowledge(Vector Store)는 Dify 내부에 강하게 바인딩된다. 외부 서비스에서 직접 접근이 불가능하고, 반드시 Dify 워크플로우를 통해서만 활용할 수 있다.
이는 전체 시스템을 Dify 중심으로 구성하지 않는 한 재사용성이 낮다는 의미다. 기존 시스템과의 통합이 필요한 경우 이 점을 고려해야 한다.
플러그인 생태계와 MCP 지원

Dify는 다양한 데이터소스 플러그인을 제공한다. Firecrawl, Notion, GitHub, Google Drive, SharePoint, Confluence 등 주요 서비스와의 연동을 지원한다.
다만 Dify가 후발주자이다 보니, n8n의 500개 이상 노드에 비하면 마켓플레이스 규모가 아직 제한적이다. 필요한 MCP(Model Context Protocol) Server를 직접 구현해야 하는 경우가 많을 것 같다. 생태계는 빠르게 성장 중이지만, 현 시점에서는 n8n 대비 성숙도가 낮은 편이다.
운영 환경에서 고려할 점
Observability 기능
Dify는 기본적인 모니터링 기능을 제공한다.
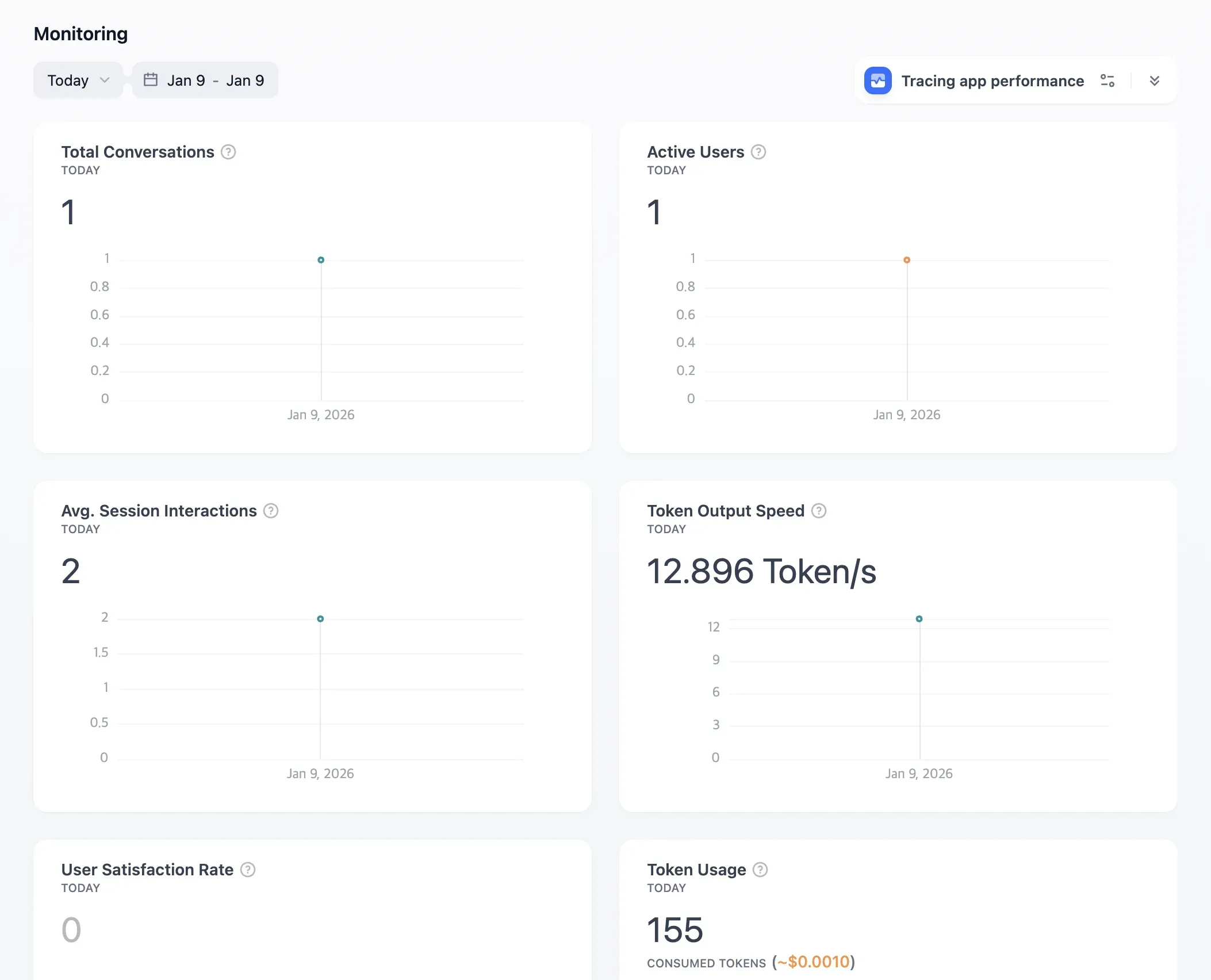
Logs에서는 요청/응답 중심의 로그를 확인할 수 있다.
Monitoring Dashboard에서는 Total Conversations, Active Users, Token Usage, Token Output Speed 등 기본 메트릭을 제공한다.
Tracing 연동도 지원한다. Langfuse, LangSmith, Opik 등 외부 트레이싱 플랫폼과 연동할 수 있다.
PoC나 소규모 운영에는 충분한 수준이다.
엔터프라이즈 운영의 한계
다만 대규모 엔터프라이즈 환경에서는 몇 가지 제약이 있다.
거버넌스 측면에서 토큰 예산 정책, 실패 처리 및 롤백, SLO/SLA 기반 자동화, 정교한 RBAC 등 세밀한 정책 제어가 필요하다면 적합하지 않을 것 같다.
Observability 측면에서 Agent나 Tool 단위의 세분화된 Metric 집계, 비용·지연·성공률 기반의 정책 자동화는 현재 지원이 부족하다.
확장성 측면에서 고동시성 환경에서의 안정성, 로드밸런싱, 트래픽 보호 등은 Self-hosted 환경에서 직접 구성해야 한다.
PoC와 소규모 운영에는 충분하지만, 대규모 Production 환경에서는 추가적인 인프라 설계가 필요하다.
n8n, Make와의 차이점
Dify를 n8n이나 Make와 단순 비교하는 것은 적절하지 않다. 지향점이 다르기 때문이다.
n8n/Make는 범용 자동화 플랫폼으로, 다양한 SaaS 앱 간의 연동과 워크플로우 자동화에 강점이 있다. 500개 이상의 노드와 풍부한 생태계를 갖추고 있다.
Dify는 LLM 앱 개발에 특화된 플랫폼으로, RAG, Agent, 프롬프트 관리, 모델 라우팅 등 LLM 앱에 필요한 기능을 네이티브로 제공한다.
범용 자동화가 필요하다면 n8n/Make가 적합하고, LLM 기반 AI 제품 개발이 목적이라면 Dify가 더 효율적이다.
결론: Dify의 올바른 포지셔닝
Dify는 LLM 애플리케이션 개발을 위한 강력한 노코드 플랫폼이다.
빛나는 지점은 명확하다. RAG 파이프라인 구축, 빠른 프로토타이핑, 다양한 모델 연동, Self-hosting 지원에서 높은 생산성을 보여준다. 아이디어 검증부터 MVP 개발까지의 속도가 탁월하다.
한계도 분명하다. 엔터프라이즈 수준의 거버넌스, 세밀한 Observability, 대규모 트래픽 처리가 필요한 환경에서는 추가적인 설계와 구현이 필요하다.
Dify를 AgentOps의 대체재가 아니라 가속기로 이해하면 적절하다. PoC와 실험 단계에서 속도를 높이고, Production 전환 시 필요에 따라 Code-first 아키텍처로 확장하는 전략이 현실적이다.
핵심 요약
Dify는 LLM 앱을 빠르게 만들어주는 강력한 도구다. 다만 대규모 운영에는 추가적인 설계가 필요하다.