Putting Files in the Cloud!
AWS는 인터넷의 중추를 담당하고 있고, Boto3를 사용하면, laptop의 확장으로 사용할 AWS의 기능을 활용할 수 있습니다. ( 자동 보고서 작성, 감정 분석 수행, 알림 전송 등 )
Python에서 AWS와 상호 작용하기 위해 Boto3라이브러리를 사용합니다.
import boto3
s3 = boto3.client('s3',
region_name='us-east-1',
aws_access_key_id=AWS_KEY_ID,
aws_secret_access_key=AWS_SECRET)
response = s3.list_buckets()사용법은 위와 같습니다.
먼저 boto3를 선언하고, AWS 서비스 이름, 리전, 키 및 시크릿를 통해 클라이언트를 초기화 합니다.
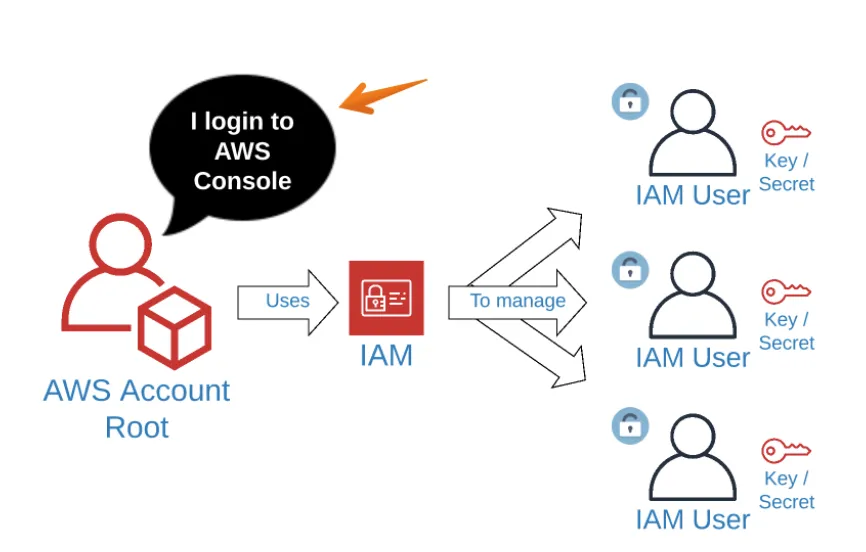
Boto3의 키/시크릿을 생성하기 위해 IAM(Identity Acess Management Service)를 사용합니다.
권한 부여 방법
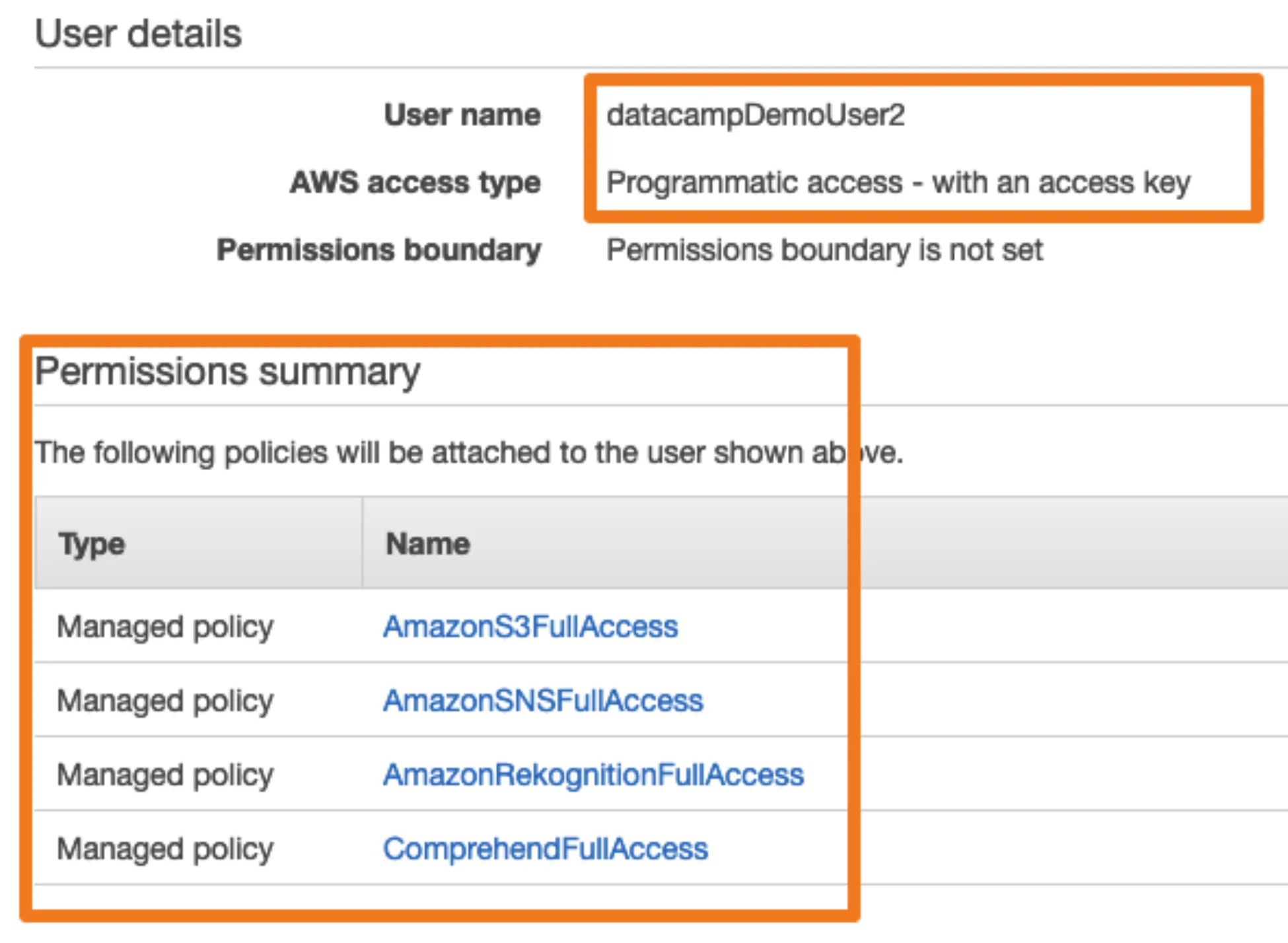
아마존 IAM 사용자에 다음과 같은 권한을 부여합니다.
AWS service
-
IAM : 이전에 알아본 것처럼 Identity Acess Management Service 의 약어로, 권한등을 관리합니다.
-
S3 : Simple Storage Service로, 파일을 클라우드에 저장할 수 있습니다.
-
SNS : Simple Notification Sevice로, 이메일과 문자를 보낼 수 있습니다. (이를 이용하여, 데이터 파이프 라인의 이벤트 및 조건을 기반으로 가입자에게 경고합니다.)
-
Comprehend : 텍스트 블록에 대한 감정 분석을 수행합니다.
-
Rekognition : 이미지에서 텍스트를 추출하고 사진에서 고양이를 찾습니다.
Diving into buckets
S3를 사용하면, 클라우드에 파일을 넣고, URL을 통해 전 세계 어디서나 액세스 할 수 있습니다.
클라우드 스토리지 관리는 데이터 파이프 라인의 핵심 구성 요소입니다.
S3 Components - Buckets
S3의 주요 구성 요소는 버킷 및 객체입니다.
-
버킷은 데스크탑의 폴더와 같습니다. ( 객체는 해당 폴더 내의 파일과 같습니다. )
-
버킷에는 자체 권한 정책이 있습니다.
-
정적 웹 사이트의 폴더 역할을 하도록 구성 할 수 있습니다.
-
로그를 생성할 수 있습니다.
S3 Components - Objects
버킷이 수행하는 가장 중요한 것은 객체를 포함하는 것 입니다.
객체는 이미지, 비디오, 파일, CSV, 로그 파일드잉 될 수 있습니다.
What can we do with buckets?
-
버킷을 생성
-
버킷을 나열
-
버킷을 삭제
버킷 생성
import boto3
s3 = boto3.client('s3', region_name='us-east-1',
aws_acess_key_id=AWS_KEY_ID,
aws_secret_access_key=AWS_SECRET)
bucket = s3.create_bucket(Bucket='gid-requests' )이전과 동일하게, 클라이언트를 생성한 뒤, gid-requests 버켓을 생성합니다. (버킷을 생성할 때, 버킷의 이름은 모두 고유해야합니다. 안그러면 오류 생깁니다.)
버킷 나열
import boto3
s3 = boto3.client('s3', region_name='us-east-1',
aws_acess_key_id=AWS_KEY_ID,
aws_secret_access_key=AWS_SECRET)
bucket_response = s3.list_buckets()
buckets = bucket_response['Buckets']
print(buckets)버킷 삭제
import boto3
s3 = boto3.client('s3', region_name='us-east-1',
aws_acess_key_id=AWS_KEY_ID,
aws_secret_access_key=AWS_SECRET)
response = s3.delete_bucket('gid-requests')Buckets and objects
버컷에 담는 것을 objects라고 표현하는데 이는, 이미지가 될 수 도 있고,비디오, 파일, CSV 또는 로그 파일과 같은 개체가 될 수 있습니다. 이러한 객체 관리는 데이터 파이프 라인의 핵심 구성 요소입니다.
S3의 객체 와 버킷은 데스크탑의 파일 및 폴더와 다소 유사하게 작동합니다.
버킷은 폴더와 같고, 객체는 그 안의 파일과 같다고 생각하면 편합니다.
Bucket
- 버킷은 name을 가진다.
- name은 string이다.
- name는 모든 S3에서 unique하다
- 버킷에는 많은 객체가 포함되어 있다.
Objects
- objects는 key를 가진다.
- name은 버킷루트의 풀 경로이다.
- 버킷안에서 Unique한 키를 가진다.
- object는 하나의 버킷에만 속할 수 있다.
Creating the client
s3 = boto3.client('s3', region_name = 'us-east-1',
aws_access_key_id=AWS_KEY_ID,
aws_secret_access_key=AWS_SECRET
)
s3.upload_file(Filename='gid_requests_2019_01_01.csv',
Bucket='gid-requests',
Key='gid_requets_2019_01_01.csv')먼저 클라이언트를 만들어 S3 변수에 할당하면, 객체와 버킷에서 작업을 수행 할 수 있습니다.
객체 업로드 방법은, 클라이언트의 upload_file메소드를 사용합니다.
Filename은 로컬 파일 경로이며, Bucket 매개 변수는 업로드 할 버킷의 이름을 사용하며, Key는 객체의 이름(AWS에 올라갈 경로)을 지정하는 것입니다. ( 해당 메소드는, 반환값이 없습니다. )
Listing objects in a bucket
response = s3.list_objects(Bucket = 'gid-requests',
MaxKeys=2,
Prefix='gid_requests_2019_')
print(response)버킷 이름에 대해 gid-requests를 전달하여 클라이언트의 list_objects 메소드를 호출하는 방법은 위와 같습니다.
MaxKeys와, Prefix의 경우 선택적으로 사용하는데, 이를 이용하여, 객체를 제한 할 수 있습니다. (Prefix의 경우 Contents에 Key값을 이용하여 해당하는 내용을 리스팅함.)
Getting objects metadata
response = s3.head_object(Bucket='gid-requets',
Key='gid_requets_2018_12_30.csv')
print(response)단일 객체에 대한 더 많은 내용을 알고 싶을 떈, head_object메소드를 이용합니다.
Downloading files
s3.download_file(Filename='gid_requests_downed.csv',
Bucket='gid-requests',
Key='gid_requests_2018_12_30.csv')파일을 다운로드 하기 위해서는 download_file메소르를 이용합니다.
Filename을 통해 다운받고자하는 파일의 저장장소를 지정합니다.
Deleting objects
s3.delete_object(Bucket='gid-requests',
Key='gid_requests_2018_12_30.csv')객체를 삭제하고 싶을 때는, delete_object를 이용하여 객체를 삭제합니다.
Sharing Files Securely.
AWS는 기본적으로 권한을 거부합니다. 즉, 파일을 업로드하면 기본적으로 키와 비밀번호만 액세스 할 수 있습니다.
이러한 동작은 귀찮을지 몰라도, 선택하는 것이 안전합니다.
df = pd.read_csv("https://gid-stagging.s3.amazonaws.com/potholes.csv")기본적으로, 판다스를 이용해서 다음 s3에 접근하려고하면 허용하지 않습니다.
이러한 접근을 위해서는, 자격증명을 통해 s3 클라이언트를 초기화하면 작동합니다.
s3 = boto3.client('s3', region_name='us-east-1',
aws_access_key_id=AWS_KEY_ID,
aws_secret_access_key=AWS_SECRET)
s3.download_file(Filenae='potholes.csv',
Bucket='gid-requests',
Key='potholes.csv')AWS Permissions Systems
S3의 권한을 제어할 수 있는 4가지의 방법이 있습니다.
- IAM을 사용하여 AWS서비스, 버킷 및 객체에 대한 사용자의 액세스를 제어 할 수 있습니다.
- 버킷 정책을 통해 버킷과 그 안의 객체를 제어 할 수 있습니다.
- ACL 또는 액세스 제어 목록을 통해 버킷 내의 특정 객체에 대한 권한을 설정할 수 있습니다.
- 미리 서명 된 URL을 사용하면, 객체에 임시로 액세스 할 수 있습니다.
ACLs
ACL은 S3의 오브젝트에 첨부 된 엔티티입니다.
s3.upload_file(Filename='potholes.csv',
Bucket='gid-requests',
Key='potholes.csv')
s3.put_objects_acl(Bucket='gid-requests',
Key='potholes.csv',
ACL='public-read')파일을 업로드한다고 가정할 때, 기본적으로, ACL은 private입니다.
S3_put_object_acl 메소드를 사용하여, ACL을 public-read 로 설정할 수 있습니다.
위와 같이 설정하면, 전 세계 누구나 파일을 다운로드 할 수 있습니다.
Setting ACLs on upload
업로드시 ACL을 공개 읽기로 설정할 수도 있습니다.
키 ACL과 값 public-read가 있는 사전을 ExtraArgs 매개 변수에 전달합니다.
s3.upload_file(Bucket='gid-requests',
Filename='potholes.csv',
Key='potholes.csv',
ExtraArgs={'ACL':'public-read'})Accessing public objects
퍼블릭 객체가 있으면 전세게 모든 사람이 버킷 형식의 URL에서 액세스 할 수 있습니다.
https://{bucket}.s3.amazonaws.com/{key}
https://gid-requests.s3.amazonaws.com/2019/potholes.csvGenerating public object URL
Python의 멋진 문자열 형식 방법을 사용하여 S3에서 객체의 공개 URL을 생성 할 수 있습니다.
url = "https://{}.s3.amazonaws.com/{}".format("gid-requests",
"2019/potholes.csv")
df = pd.read_csv(url)버킷 이름과 객체 키가 빈 괄호 인 문자열을 만들고, format메소드를 통해서 위치 인수를 전달합니다.
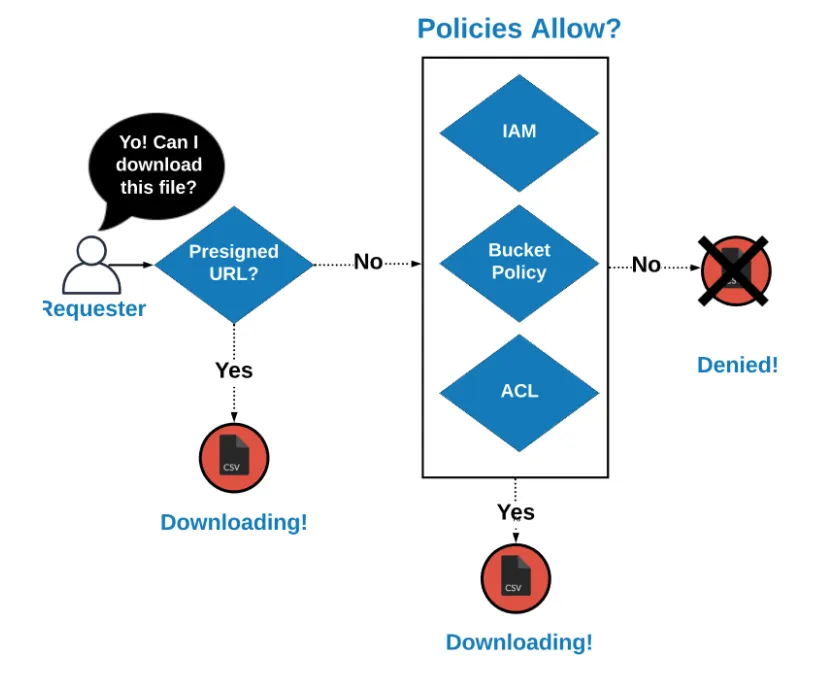
How access is decided
미리 서명 된 URL 인 경우 요청이 들어 오면 다운로드가 허용되고, 미리 서명되지 않은 경우, 정책에서 다운로드를 허용하는지 확인합니다. AWS의 기본 동작은 액세서를 거부하는 것입니다.
Downloading a private file
파일에 대한 공개 읽기 ACL을 명시적으로 설정하지 않은 경우, AWS하는 비공개로 설정합니다. 이를 공유하기 위해서는 boto3를 사용합니다,.
s3.download_file(Filename='potholes_local.csv',
Bucket='gid-staging',
Key='2019/potholes_private.csv')
pd.read_csv('./potholes_local.csv')boto3의 download_file 메소드를 사용하여 파일을 다운로드하고 판다스가 csv를 읽도록 할 수 있습니다.
Accessing private files
그러나, 위의 방법보다 get_object메소드를 사용하는 방법이 훨씬 간단한 방법입니다.
obj = s3.get_object(Bucket='gid-requests', Key='2019/potholes.csv')
print(obj)
pd.read_csv(obj['Body'])버킷 이름과 객체 키를 매개변수로 사용하여 get_object 메소드를 호출합니다.
Pre-signed URLs
pre-signed_url을 사용하여 s3 개인 객체에 대한 액세스 권한을 일시적으로 부여 할 수도있습니다.
- Upload a file
s3.upload_file(Filename='./potholes.csv',
Key='potholes.key',
Bucket='gid-requests')- Generate Presigned URL
share_url = s3.generate_presigned_url(ClientMethod='get_object',
ExpiresIn=3600,
Params={'Bucket': 'gid-requests',
'Key': 'potholes.csv'})
pd.read_csv(share_url)3600초 동안, 파일에 대한 액세스 권한을 부여하는 url을 생성합니다.
Load mulitple files into one DataFrame
종종 데이터 엔지니어는 s3에서 여러 파일을 구문 분석해야합니다.
패턴에 따라 하나의 DataFrame에 로드한 다음, 무언가를 수행합니다.
df_list = []
response = s3.list_objects(Bucket='gid-requests',
Prefix='2019/')
request_files = response['Contents']
for file in request_files:
obj = s3.get_object(Bucket='gid-requests',
Key=file['Key'])
obj_df = pd.read_csv(obj['Body'])
df_list.append(obj_df)
df = pd.concat(df_list)위와같이 여러파일을 array에 담아서, 불러올 수 있습니다.
이후 concat를 이용해서, 하나의 DataFrame으로 결합할 수 있습니다.
Serving HTML pages
S3는 HTML페이지를 제공 할 수 있습니다.
이는 분석 결과를 경영진과 공유하고 파이프 라인을 통해 결과를 업데이트 할 때 유용합니다.
많은 파이썬 데이터 과학 도구에서는 데이터에서 간단한 HTML을 생성하는 기능이 있습니다.
HTML table in Pandas
df.to_html('table_agg.html')이를 사용하여, DataFrame을 HTML 파일에 쓸 수 있습니다.
선택적으로 render_links 인수는 모든 URL을 클릭 할 수 있도록 변환합니다.
df.to_html('table_agg.html', render=links=True)Columns 매개 변수를 사용하여 렌더링하려는 열만 목록으로 전달할 수 있습니다.
df.to_html('table_agg.html', render_links=True,
columns=['service_name', 'request_count', 'info_link'])Borders
Border인수를 통해 몇 가지 기본 테두리 컨트롤이 있습니다.
df.to_html('table_agg.html',
render_links=True,
columns=['service_name', 'requests_count', 'info_link'],
border=0)값이 0이면, 테두리가 제거되고, 값이 1이면 테두리가 표시됩니다.
Uploading an HTML file to S3
html 파일을 업로드하는 것은 다른 파일을 업로드 하는 것과 같습니다.
브라우저가 HTML로 취급 할 수 있도록 ContentType을 설정해야합니다.
s3.upload_file(Filename='./table_agg.html',
Bucket='datacamp-website',
Key='table.html',
ExtraArgs = {'ContentType': 'text/html'.
'ACL': 'public-read'})upload_file 메소드를 사용하여 S3에 업로드합니다.
Uploading other types of content
Python의 차트 라이브러리에서 생성 된 것과 같은 이미지를 업로드하는 것은 위와 유사합니다.
s3.upload_file(Filename='./plot_image.png',
Bucket='datacamp-website',
Key='plot_image.png',
ExtraArgs = {'ContentType': 'image/png',
'ACL': 'public-read'})HTML 파일을 업로드하지만, 브라우저에서 렌더링하려면 업로드하는 동안 적절한 contentType을 설정해야 합니다.
PNG의 경우 contentType으로 image/png를 사용합니다.
IANA Media Types
IANA에는 파일 확장자를 기준으로 모든 파일 유형 목록이 있습니다.
- JSON : application/json
- PNG : image/png
- PDF : application/pdf
- CSV : text/csv
Generating an index page
r = s3.list_objects(Bucket='gid-reports', Prefix='2019/')
objects_df = pd.DataFrame(r['Contents'])
base_url = 'http://datacamp-website.s3.amazonaws.com/'
objects_df['Link'] = base_url + objects_df['Key']
objects_df.to_html('report_listing.html',
columns=['Link', 'LastModified', 'Size'],
render_links=True)목록을 생성하는 방법은 위와 같습니다.
먼저 버킷의 객체를 나열하고, DataFrame으로 변환합니다. 객체의 모든 키에 대한 URL을 생성하는 링크열을 생성하고, DataFrame을 HTML에 작성합니다.
Uploading index page
s3.upload_file(Filename='./report_listing.html',
Bucket='datacamp-website',
Key='index.html',
ExtraArgs = {'ContentType': 'text/html',
'ACL': 'public-read'})다른 HTML 파일처럼 생성한 색인 페이지를 업로드합니다.
Generating a Report Repository
- Read raw data files
df_list = []
response = s3.list_objects(Bucket='gid-requests',
Prefix='2019_jan')
request_files = response['Contents']
for file in request_files:
obj = s3.get_object(Bucket='gid-requests', Key=file['Key'])
obj_df = pd.read_csv(obj['Body'])
df_list.append(obj_df)
df = pd.concat(df_list)
df.head()- Create aggregated reports
df.to_csv('jan_final_report.csv')
df.to_html('jan_final_report.html')
jan_final_chart.html # bokeh 플롯다음과 같이 생성후, gid-reports 버킷에 집계 된 보고서를 배치합니다.
- Upload Aggregated CSV
s3.upload_file(Filename='./jan_final_report.csv',
Key='2019/jan/final_report.csv',
Bucket='gid-reports',
ExtraArgs={'ACL': 'public-read'})- Upload HTML Table
s3.upload_file(Filename='./jan_final_report.html',
Key='2019/jan/final_report.html',
Bucket='gid-reports',
ExtraArgs={'ContentType': 'text/html',
'ACL' : 'public-read'})- Upload HTML Chart
s3.upload_file(Filename='./jan_final_chart.html',
Key='2019/jan/final_chart.html',
Bucket='gid-reports',
ExtraArgs={'ContentType': 'text/html',
'ACL' : 'pulic-read'})- Create index.html
r = s3.list_objects(Bucket='gid-reports', Prefix='2019/')
objects_df = pd.DataFrame(r['Contents'])
base_url = "https://gid-reports.s3.amazonaws.com/"
objects_df['Link'] = base_url + objects_df['Key']
objects_df.to_html('report_listing.html',
columns=['Link', 'LastModified', 'Size'],
render_links=True)- Upload index.html
s3.upload_file(Filename='./report_listing.html',
Key='index.html',
Bucket='gid-reports'.
ExtraArgs = {'ContentType': 'text/html',
'ACL': 'public-read'})Reporting and Notifying!
Amazon SNS는 간단한 알림 서비스입니다. 이것을 이용해서, 이메일, 문자 메시지 및 푸시 알림을 보낼 수 있습니다.
게시자는 주제에 메시지를 게시하고 가입자는 메시지를 받습니다.
AWS SNS을 검색해서 들어가면, 대시보드가 있는데, Topics 와 Subscriptions에 관한 내용이 표시됩니다.
모든 Topics는, ARN 또는 Amazon 리소스 이름이 있습니다. 이는 고유 ID입니다.
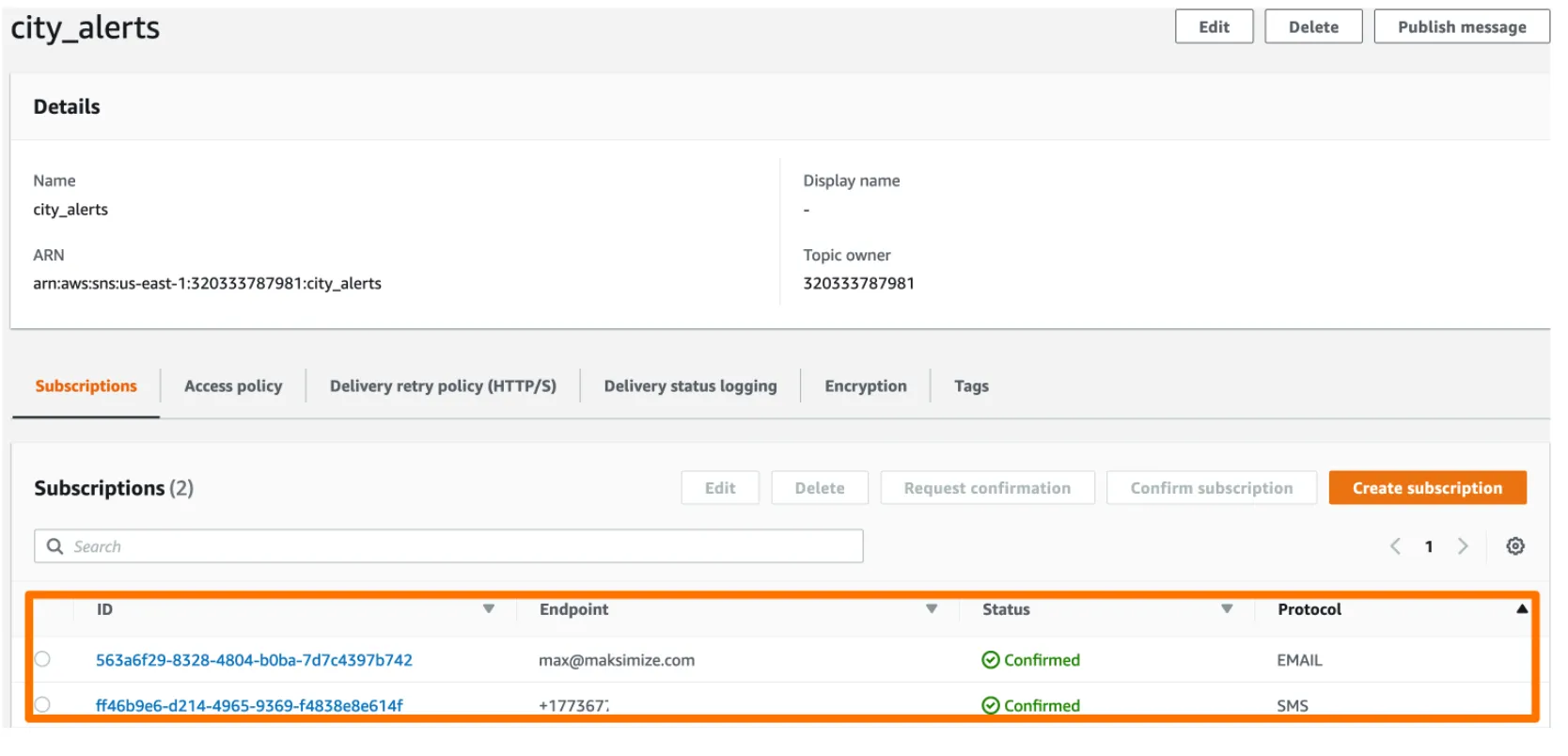
하단에는 구독 정보가 표시됩니다. 이또한 고유 ID를 가지고 있습니다.
Creating an SNS Topic
sns = boto3.client('sns', region_name = 'us-east-1',
aws_access_key_id = AWS_KEY_ID,
aws_secret_access_key = AWS_SECRET)
response = sns.create_topic(Name='city_alerts')
topic_arn = response['TopicArn']
# or
# sns.create_topic(Name='city_alerts')['TopicArn']SNS 주제를 만들기 위해 SNS 클라이언트를 초기화합니다. 이전과 다르게 ‘s3’가 아닌 ‘sns’를 사용합니다.
이제 클라이언트가 생겼으므로 create_topic 메소드를 사용해서 주제를 만듭니다.
변수에 저장하기 위해서 응답 TopicArn키를 가져옵니다.
Listing topics
response = sns.list_topics()list_topic 메소드를 이용하면 주제를 Topics 를 나열할 수 있습니다.
Deleting topics
sns.delete_topic(TopicArn='arn:aws:sns:us-east-1:320333783981:city_alerts')Topics를 삭제하려면, TopicArn을 delete_topic메소드에 입력하면 됩니다.
Creating an SMS subscription
sns = boto3.client('sns', region_name = 'us-east-1',
aws_access_key_id = AWS_KEY_ID,
aws_secret_access_key=AWS_SECRET)
response =. ns.subscribe(TopicArn ="arn:was:sns:us-east-1:320333787981:city_alerts",
Protocol='SMS', Endpoint='+13125551123')SMS 구독을 만들기 위해 boto3 SNS 클라이언트를 초기화합니다.
이후, TopicArn을 전달하여, SNS subscribe를 호출합니다. 프로토콜은 SMS이여, end-point는 전화번호입니다.
Creating an email subscription
response =sns.subscribe(TopicArn ="arn:was:sns:us-east-1:320333787981:city_alerts",
Protocol='email', Endpoint='max@maksimize.com')이메일 구독 작성도 SMS와 매우 유사합니다. 프로토콜을 email로 설정하고 , Endpoint는 이메일로 설정하면됩니다.
Listing subscriptions by Topic
sns.list_subscriptions_by_topic(TopicArn="arn:was:sns:us-east-1:320333787981:city_alerts")
sns.list_subscriptions()['Subscriptions']고객의 list_subscriptions_by_topic 메소드를 이용해서 TopicArn을 전달합니다.
Deleting subscriptions
sns.unsubscribe(SubscriptionArn="arn:was:sns:us-east-1:320333787981:city_alerts:9f2dad1d-8844-4fe8")구독을 삭제하고 싶으면, SNS 구독 취소 메소드를 이용해서 삭제합니다.
Deleting multiple subscriptions
response = sns.list_subscriptions_by_topic("arn:was:sns:us-east-1:320333787981:city_alerts")
subs = response['Subscriptions']
for sub in subs:
if sub['Protocol'] == 'sms':
sns.unsubscribe(sub['SubscriptionArn'])모든 구독에 대해 SMS인 경우 구독 취소 메소드를 호출하는 방법은 위와 같습니다.
Publishing to a Topic
Topic에 메시지를 게시하면, 모든 구독자가 메시지를 받습니다.
response = sns.publish(TopicArn="arn:was:sns:us-east-1:320333787981:city_alerts",
Message = 'Body text of SMS or e-mail',
Subject = 'Subject Line for Email')Topic에 게시하기 위해서는, TopicArn, message 및 subject를 인자로 전달받습니다.
메시지 인자는, 메시지 본문의 내용이며, Subject는 제목입니다.
Sending custom messages
num_of_reports = 137
response = client.publish(
TopicArn = "arn:was:sns:us-east-1:320333787981:city_alerts",
Message = 'There are {} reports outstanding'.format(num_of_reports),
Subject = 'Subject Line for Email')사용자 정의 메시지를 보내기 위해서는, 파이썬 문자열 형식 메소드를 이용하면 됩니다.
Sending a single SMS
response = sns.publish(PhoneNumber = '+13121233211',
Message = 'Body text of SMS or e-mail')단일 SMS를 보내기 위해 동일하게, boto3 SNS 클라이언트의 pulish를 사용합니다.
Message 인자는, 텍스트의 본문이며, PhoneNumber은 전화번호입니다.
Not a good long term practice
이러한 일회성 문자 메시지는, 유용하지만 데이터 파이프라인에는 매우 까다로운 방법입니다.
데이터 엔지니어의 임무 중 하나는 데이터를 유지 관리 할 수 있게하는 업무 수행에 균형을 맞추는 것 입니다.
Building the notification system
구덩이 및 불법 투기 잔고가 통제 불능 상태로 증가하고, 시의회가 이사들이 언제 업무를 수행하고 있는지 알리는 구조를 요청했다.
이를 구현하기 위해, 이메일 전화번호와 함께 CSV를 관리합니다. 이 목록을 사용하여 작성한 trash_nontifications Topic에 대한 구독을 작성합니다. 그 후, final_report를 확인합니다. 이를 통해 불법 투기 사례가 30이 초과하면, trash_notificaition Topic에 publish됩니다.
- Create the topic
- Download the contact list csv
- Create topics for each service
- Subcribe the contacts to their respective topics
- Download the monthly get it done report
- Get the count of Potholes
- Get the count of Illegal dumping notifications
- If potholes exceeds 100, send alert
- If illegal dumping exceeds 30, send alert
Topic set up
sns = boto3.client('sns', region_name = 'us-east-1',
aws_access_key_id=AWS_KEY_ID,
aws_secret_access_key=AWS_SECRET)
trash_arn = sns.create_topic(Name="trash_notifications")['TopicArn']
streets_arn = sns.create_topic(Name="streets_notifications")['TopicArn']먼저 휴지통 거리 알림에 대한 주제를 만듭니다. 나중에 사용할 수 있도록 ARN을 변수에 저장합니다.
Subscribing users to topics
contacts = pd.read_csv("https://gid-staging.s3.amazonaws.com/contacts.csv")
def subscribe_user(user_row):
if uesr_row['Department'] == 'trash':
sns.subscribe(TopicArn = trash_arn, Protocol='sms', Endpoint=str(user_row['Phone']))
sns.subscribe(TopicArn = trash_arn, Protocol='email', Endpoint=user_row['Email'])
else:
sns.subscribe(TopicArn = streets_arn, Protocol='sms', Endpoint=str(user_row['Phone']))
sns.subscribe(TopicArn = streets_arn, Protocol='email', Endpoint=user_row['Email'])데이터에 있는 정보를 이용해서, 구독을 진행하는 함수를 작성합니다.
contacts.apply(subscribe_user, axis=1)Get the aggregated numbers
df = pd.read_csv("http://gid-reports.s3.amazonaws.com/2019/feb/final_report.csv")
df.set_index('service_name', inplace=True)
trash_violations_count = df.at['Illegal Dumping', 'count']
streets_violations_count = df.at['Pothole', 'count']이후, 해당 데이터를 변수에 저장합니다.
Send Alerts
if trash_violations_count > 100:
message = "Trash violations count is now {}".format(trash_violations_count)
sns.publish(TopicArn = trash_arn,
Message = message,
Subject = "Trash Alert")
if streets_violations_count > 30:
message = "Streets violations count is now {}".format(streets_violations_count)
sns.publish(TopicArn = streets_arn,
Message = message,
Subject = "Streets Alert")만약 해당 변수가 설정한 값 이상일경우, 경고 메세지를 보냅니다.
Pattern Rekognition
Boto3 문서와 AWS 인터페이스를 사용하여, Rekognition이라는 새로운 서비스를 탐색합니다.
Rekognition
Rekognition은 AWS의 컴퓨터 비전 API입니다.
- Detecting Objects in an image
- Extracting Text from Images
Rekognition 사용이유
우리가 직접 모델을 만든다면, 인식과 같은 하나의 특정 임무를 위해 훈련을 합니다. 이는 Training 데이터가 필요하고, 모델을 배포하고 유지 관리해야합니다.
- Quick but good
- Keep code simple
- Recognize many things
Upload an image to S3
물체 감지를 위해 인식 기능을 사용하는 방법을 살펴봅니다.
시는, 카메라를 지나가는 자전거를 세려고합니다. 이 작업을 하기 전에, 이미지를 S3에 업로드해야합니다.
s3 = boto3.client('s3', region_name='us-east-1',
aws_access_key_id=AWS_KEY_ID, aws_secret_access_key=AWS_SECRET)
s3.upload_file(Filename='report.jpg', Key='report.jpg',
Bucket='datacamp-img')S3 클라이언트를 초기화 한 다음, upload file 메소드를 호출합니다.
Object detection
rekog = boto3.client('rekognition', region_name='us-east-1',
aws_access_key_id=AWS_KEY_ID,
aws_secret_access_key=AWS_SECRET)
response = rekog.detect_labels(Image={'S3Object':
{'Bucekt':'datacamp-img',
'Name':'report.jpg'},
MaxLabels=10,
MinConfidence=95})이후 boto3 Rekognition 클라이언트를 구성합니다. 버켓 및 이미지를 지정하고, 선택적으로, 반환 할 최대 라벨 수, 및 최소한의 신뢰정도를 설정 할 수 있습니다.
Text detection
텍스트 추출도 비슷하게 작동됩니다.
response = rekog.detect_text(Image={'S3Object':
{
'Bucket': 'datacamp-img',
'Name': 'report.jpg'
}})클라이언트를 인스턴스화 한 다음, detect_text를 호출하여 이미지 및 버킷을 입력합니다.
Translating text
translate = boto3.client('translate',
region_name = 'us-east-1',
aws_access_key_id=AWS_KEY_ID,
aws_secret_access_key=AWS_SECRET)
response = translate.translate_text(Text='Hello, how are you?',
SourceLanguageCode='auto',
TargetLanguageCode='es')AWS를 이용해서, translating 하는 방법도 위와 유사합니다. 먼저 AWS translate 용 boto3클라이언트를 초기화합니다.
이후, translate_text 메소드를 호출합니다. 텍스트 인수로, 번역하려는 텍스트를 전달하고, 언어를 설정합니다.
response = translate.translate_text(Text='Hello, how are you?',
SourceLanguageCode='auto',
TargetLanguageCode='es')['TranslatedText']이 구조를 통해 간단한 한 줄짜리를 만들어 응답에서 직접 번역 된 텍스트를 얻을 수 있습니다.
Detecting language
AWS Comprehend를 사용하여, SourceLanguageCode 자동 선택을 사용합니다.
comprehend = boto3.client('comprehend',
region_name='us-east-1',
aws_access_key_id=AWS_KEY_ID,
aws_secret_access_key=AWS_SECRET)
response = comprehend.detect_dominant_language(
Text='Hay basura por todas partes a lo largo de la carretera.')이또한, boto3의 comprehend 클라이언트를 초기화하는 것으로 시작합니다.
이후 detect_dominant_language 메소드를 이용해서, Text를 입력받아, 해당 언어가 어떤 언어인지 알 수 있습니다.
Understanding sentiment
response = comprehend.detect_sentiment(Text="DataCamp students are amazing.",
LanguageCode='en')위와 동일하게 comprehend 인스턴스를 사용하며, Text와 해당 언어를 입력받습니다.
Final Product
지난 해, 시는 거리에 스쿠터로 부터 맹공격을 당했습니다. 많은 주민들이 재미있는 교통 수단을 즐기면서, 시의회는 노인과 장애가있는 주민들로부터 더 나은 규제를 받아야한다는 압력을 받고 있습니다. 또한 사람들은 종종 길거리에두고 길을 막습니다. 시의회는 도시가 보도를 막는 스쿠터를 집어 올리는 정책을 통과시킬 것인지에 대해 토론합니다. 그러나, 시의회에 출석하는 사람들은 도시 인구 통계를 나타내는 경향이 없으며, 시의회는 요청을 검토하여 도시가 픽업해야할 스쿠터의 양을 추정하도록 요청했습니다.
- Initialize boto3 service clients.
rekog = boto3.client('rekognition',
region_name='us-east-1',
aws_access_key_id=AWS_KEY_ID,
aws_secret_access_key=AWS_SECRET)
comprehend = boto3.client('comprehend',
region_name='us-east-1',
aws_access_key_id=AWS_KEY_ID,
aws_secret_access_key=AWS_SECRET)
translate = boto3.client('translate',
region_name='us-east-1',
aws_access_key_id=AWS_KEY_ID,
aws_secret_access_key=AWS_SECRET)먼저 클라이언트 설정을 진행합니다.
-Translate all descriptions to English
for index, row in df.iterrows():
desc = df.loc[index, 'public_description']
if desc != '':
resp = translate_fake.translate_text(Text=desc,
SourceLanguageCode='auto',
TargetLanguageCode='en')
df.loc[index,'public_description'] = resp['TranslatedText']현재 다양한 언어로 작성되어있는 언어를, 하나의 언어로 번역하는 작업을 진행합니다.
- Detect text sentiment
for index, row in df.iterrows():
desc = df.loc[index, 'public_description']
if desc != '':
resp = comprehend.detect_sentiment(Text=desc,
LanguageCode='en')
df.loc[index, 'sentiment'] = resp['Sentiment']이후, 설명에서 텍스트의 감정을 감지하기 위해 DataFrame의 모든 행을 반복합니다.
- Detect scooter in image
df['img_scooter'] = 0
for index, row in df.iterrows():
image = df.loc[index, 'image']
response = rekog.detect_labels(
Image={'S3Object': {'Bucket': 'gid-images', 'Name': image}}
)
for label in response['Labels']:
if label['Name'] == 'Scooter':
df.loc[index, 'img_scooter'] = 1
break마지막으로, 저장한 모든 이미지에 대해, Rekognition레이블 감지를 실행합니다.
- Final count
pickups = df[((df.img_scooter == 1) & (df.sentiment =='NEGATIVE'))]
num_pickups = len(pickups)스쿠터가 감지 되고, 부정의 감정을 가진 모든 행을 픽업 데이터 프레임에 저장하고 그 수를 저장합니다.