Your first database
데이터 베이스를 만드는 것은, csv나 excel파일을 이용하는 것보다 많은 이점을 가집니다.
A relational database
-
데이터베이스는 개체를 테이블에 저장하여 모델링합니다. (professor, universities, companies)
-
각 테이블에는 단일 항목 유형의 데이터만 포함됩니다. (Companies for bank “Credit Suisse”)
이것은 엔티티를 한 번만 저장하여 중복성을 줄입니다.
- 데이터베이스를 사용하여 엔티티 간의 관계를 모델링 할 수 있습니다. (교수는 대학, 회사 여러곳에서 일할 수 있고, 회사는 여러 교수를 고용할 수 있다.)
이러한 구성을 통해, 엔티티가 서로 관련되는 방식을 정확히 정의할 수 있습니다.
Have a look at the PostgreSQL database
SELECT table_schema, table_name
FROM information_schema.tablesSELECT table_name, columns_name, data_type
FROM information_schema.columns
WHERE table_name = 'pg_config';SELECT *
FROM university_professors
LIMIT 3;One “entity type” in the database
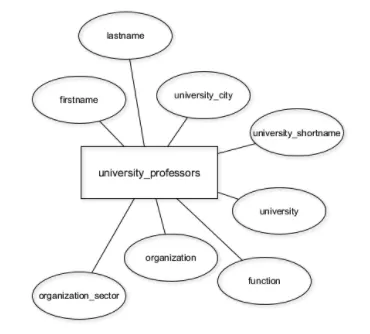
위와 같은 그림을 엔티티-관계 다이어그램이라고 합니다.
사각형은 소위 엔티티 유형을 나타내고, 연결된 원은 속성(또는 열)을 나타냅니다.
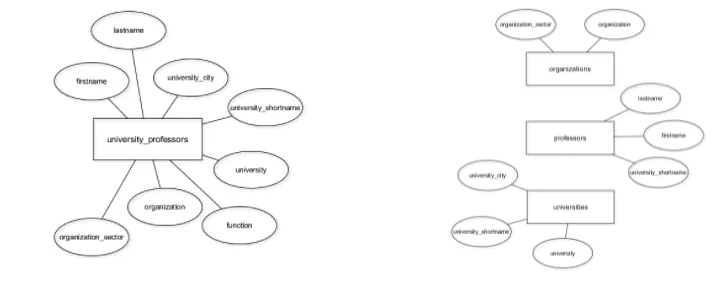
위와 같이 이용하면, 중복성이 줄어들게 됩니다. 하지만, 원래 속성 중 하나인 기능이 여전히 누락되어 있습니다. 이를 위해서 제휴 테이블을 따로 생성하는 것이 올바른 방법입니다.
CREATE TABLE table_name(
column_a data_type,
column_b data_type,
column_c data_type
);
ALTER TABLE table_name
ADD column_d data_type;이를 위해 가장 먼저 해야하는 것은 테이블을 만드는 것입니다. 위와 같이, SQL의 CREATE TABLE 명령어를 사용합니다. 최소한 이 명령에는 테이블 이름과 해당 데이터 유형이 있는 하나 이상의 열이 필요합니다.
CREATE TABLE weather(
clouds text,
temperature numeric,
weather_station char(5)
);예를 들어, 적적할게 세 개의 열이 있는 날씨 테이블을 만들 수 있습니다.
각 열의 데이터 타입을 지정해야합니다.
DISTINCT data in the new tables
SELECT COUNT(*)
FROM university_professors;테이블을 분할하는 것의 한 가지 장점은 중복성이 감소된다는 것입니다.
SELECT COUNT(DISTINCT organization)
FROM university_professors;하지만 완벽하게, 고유의 조직으로 분리하지는 못합니다.
INSERT DISTINCT records INTO the new tables
INSERT INTO organizations
SELECT DISTINCT organization,
organization_sector
FROM university_professors;기존 테이블에서 새 테이블로 데이터를 복사하려면, INSERT INTO SELECT DISTINCT 패턴을 사용할 수 있습니다.
INSERT INTO table_name (column_a, column_b)
VALUES ("value_a", "value_b");이것은 수동으로 값을 삽입하는 INSERT INTO 의 일반적인 사례입니다.
CREATE TABLE affiliations(
first_name text,
last_name text,
university_shortname text,
function text,
organisation text
);
ALTER TABLE table_name
RENAME COLUMN old_name TO new_name;column의 이름을 변경하고 싶으면, ALTER TABLE을 통해 변경할 수 있습니다.
DROP a column in affiliations
CREATE TABLE affiliations(
firstname text,
lastname text,
university_shortname text,
function text,
organization text
);
ALTER TABLE table_name
DROP COLUMN column_name;university_shortname이 필요없기에, 이를 DROP 하기 위해서는 위와 같이 사용합니다.
Enforce data consistency with attribute constraints
데이터베이스 개념은 데이터를 특정 구조로 밀어 넣는 것입니다.
데이터 유형, 관계 및 기타 규칙을 적용하는 사전 정의된 모델입니다.
일반 적으로 이러한 규칙을 무결성 제약 조건이라고 하지만 다른 이름이 존재합니다.
Integrity constrains
무결성 제약조건은 대략 세가지의 유형으로 나눌 수 있습니다.
- Attribute constraints - 데이터 타입
- Key constraints - 고유키
- Referential integrity constraints - foreign keys
Why constraints
제약 조건에 대해 알아야하는 이유
- 데이터를 특정 형태로 압축
- 제약 조건은 일관성을 제공
- 데이터 품질 문제를 해결하는데 도움
- 데이터베이스 관리 시스템에 큰 도움
Dealing with data types (casting)
CREATE TABLE weather (
temperature integer,
wind_speed text
);
SELECT temperature * wind_speed AS wind_chill
FROM weather;데이터 유형은, SQL 작업을 제한합니다. ( 텍스트 연산 등 )
SELECT temperature * CAST(wind_speed AS integer) AS wind_chill
FROM weather;이를 위해서는, CAST를 이용합니다. ( 즉각적인 유형 변환 )
Working with data types
데이터 유형 작업은 데이터베이스 관리 시스템에서 간단합니다.
- 테이블의 단일 열에 대해 구현됩니다.
- 열에 있는 값의 영역을 정의합니다. (이러한 값이 취할 수 있는 형식과 그렇지 않은 형식)
- 어떤 작업이 가능한지 정의합니다.
- 일관된 저장이 이루어집니다.
이러한 작업은 데이터 품질 향상에 도움이 됩니다.
The most common types (PostgreSQL)
- text
- varchar(x)
- char(x)
- boolean
- date
- time
- timestamp
- numeric
- Integer
데이터베이스 관리 시스템이 있으며 대부분의 SQL 표준을 따릅니다.
Specifying types upon table creation
CREATE TABLE students (
ssn integer,
name varchar(64),
dob date,
average_grade numeric(3,2), -- e.g. 5.24
tuition_paid boolean
);
ALTER TABLE students
ALTER COLUMN name
TYPE varchar(128);테이블 생성 후 유형을 변경하는 것은 위와 같습니다. ALTER COLUMN을 이용해서 지정합니다.
ALTER TABLE students
ALTER COLUMN average_grade
TYPE integer
-- Turn 5.54 into 6, not 5, before type conversion
USING ROUND(average_grade)USING 키워드를 사용하서 유형이 변경되기전에 변환을 지정할 수 있습니다.
ALTER TABLE professors
ALTER COLUMN firstname
TYPE varchar(16)
USING SUBSTRING(firstname FROM 1 FOR 16);The not-null constraint
- NULL이 아닌 제약 조건은, 주어진 열에서 NULL 값을 허용하지 않습니다.
- 이는 기존 상태 뿐만 아니라, 미래의 모든 상태에도 적용되어야 합니다.
- NULL 값을 보유하지 않은 열에 대해서만 not-null 제약 조건을 지정할 수 있습니다.
What does NULL mean?
- unknown
- does not exist
- does not apply
- …
< br>
Example
CREATE TABLE students (
ssn integer not null,
lastname varchar(64) not null,
home_phone integer,
office_home integer
);위와 같이 학생을 정의하는 테이블이 있을 때, ssn(학생 고유번호), lastname는 null이 아니여야 하지만, home_phone이나 office_home등은 null을 허용해야합니다. (전화가 없을 수도 있기 때문에.)
ALTER TABLE students
ALTER COLUMN home_phone
SET NOT NULL;그러나 기존 테이블에 null이 아닌 제약 조건을 추가하거나 제거할 수도 있습니다.
ALTER TABLE students
ALTER COLUMN ssn
DROP NOT NULL;비슷하게 not null을 해제할수도 있습니다.
The unique constraint
열에 대한 고유 제약조건은 열에 중복 항목이 없는지 확인합니다.
고유의 항목만 추가할 수 있습니다.
CREATE TABLE table_name(
column name UNIQUE
);
ALTER TABLE table_name
ADD CONSTRAINT some_name UNIQUE(column_name)고유 제약 조건이 있는 열을 만드는 방법은 다음과 같습니다. 컬럼명 뒤에 UNIQUE 키워드를 추가하면 됩니다.
또한, 기존 테이블에 고유 제약 조건을 추가할 수도 있습니다.
What is key?
일반적으로 데이터베이스 테이블에는 속성 또는 다음의 조합이 있습니다.
-
전체 테이블에서 고유한 여러 속성 (레코드를 고유하게 식별)
-
슈퍼키 속성(조합을 제거할 수 있으며 속성은 여전히 레코드를 고유하개 식별)
-
최소 키(최소한으로 구성)
Primary keys
기본 키는 데이터베이스 설계에서 가장 중요한 개념 중 하나입니다.
-
거의 모든 데이터베이스 테이블에는 후보 키 집합에서 사용자가 선택한 기본 키가 있어야 합니다.
-
주요 목적은 테이블에서 레코드를 고유하게 식별하는 것입니다.
-
기본 키는, 중복 또는 NULL값을 허용하지 않습니다.
-
기본 키 제약조건은 시간 불변입니다.
Specifying primary key
CREATE TABLE products (
product_no integer UNIQUE NOT NULL,
name text,
price numeric
);
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);위의 두 테이블은 동일한 데이터를 허용하지만, 두번째 테이블에서는 기본 키가 지정되어 있습니다.
기본키 지정방법은 뒤에 PRIMARY KEY를 지정해주면 됩니다.
CREATE TABLE example (
a integer,
b integer,
c integer,
PRIMARY KEY (a,c)
);둘 이상의 열을 기본 키로 지정하려는 경우 위와 같이 지정합니다.
ALTER TABLE table_name
ADD CONSTRAINT some_name PRIMARY KEY(column_name)기존 테이블에 기본 키 제약 조건을 추가하는 것은 위와 같습니다.
Surrogate keys
인공 대리 키를 만드는 이유
- 기본 키는 가능한 적은 수의 열로 이상적 구성
- 기본 키는 시간이 지나도 변경되지 않아야 합니다.
Adding a surrogate key with serial data type
ALTER TABLE cars
ADD COLUMN id serial PRIMARY KEY;이를 다루는 특별한 유형이 있습니다.(serial)
Serial 타입은, 열을 추가하면 테이블의 모든 레코드에 번호가 매겨집니다.
INSERT INTO cars
VALUES ('Opel', 'Astra', 'green', 1);또한 이미 존재하는 ID를 지정하려고 하면 기본 키 제약 조건으로 인해 그렇지 못하게 합니다.
Another type of surrogate key
ALTER TABLE table_name
ADD COLUMN column_c varchar(256);
UPDATE table_name
SET column_c = CONCAT(column_a, column_b);
ALTER TABLE table_name
ADD CONSTRAINT pk PRIMARY KEY (column_c);대리 키를 만드는 또 다른 전략은 두 개의 기존 열을 이용해서 새 열을 만드는 방법입니다.
Implementing relationships with foreign keys
외래 키는 다른 테이블의 기본 키를 가리키는 지정된 열입니다.
외래 키에는 몇가지 제한 사항이 있습니다.
- 도메인과 데이터 유형이 기본 키 중 하나와 동일해야 합니다.
- 참조된 테이블의 기본 키에 값으로 존재하는 외래 키만 허용됩니다.
- 참조 무결성이라고도 하는 실제 외래 키 제약 조건입니다.
- 외래 키가 반드시 실제 키일 필요는 없습니다. ( 중복 or NULL 값 허용 )
Specifying foreign keys
CREATE TABLE manufacturers (
name varchar(255) PRIMARY KEY);
INSERT INTO manufacturers
VALUES ('Ford'), ('VW'), ('GM');
CREATE TABLE cars (
model varchar(255) PRIMARY KEY,
manufacturer_name varchar(255) REFERENCES manufactures (name));
INSERT INTO cars
VALUES ('Ranger', 'Ford'), ('Beetle', 'VW')먼저 manufacturers라는 테이블과 , cars라는 테이블을 생성합니다.
자동차 테이블에는, REFERENCES를 이용해서 제조사 컬럼을 추가합니다.
INSERT INTO cars
VALUES ('Tundra', 'Toyota');저장되지 않은, 제조사를 입력하면 테이블의 외래 키 제약 조건으로 인해 불가능합니다.
Specifying foreign keys to existing tables
ALTER TABLE a
ADD CONSTRAINT a_fkey FOREIGN KEY (b_id) REFERENCES b (id);기존 테이블에 외래 키를 추가하는 구문은 다음과 같습니다.
기본 키 및 고유 제약 조건을 추가하는 것과 동일합니다.
How to implement N:M - relationships
- 테이블 만들기
- 모든 테이블을 연결할 수 있는 외래 키
- 추가 속성 포함
CREATE TABLE affiliations (
professors_id integer REFERENCES professors (id),
organization_id varchar(256) REFERENCES organizations (id),
function varchar(256)
);해당 관계 테이블을 처음부터 생성하려는 경우 표시된 대로 정의합니다.
- 기본 키가 정의되어 있지 않습니다.
Referential integrity ( 참조 무결성 )
다른 테이블의 다른 레코드를 참조하는 레코드는 항상 기존 레코드를 참조해야 함을 나타냅니다.
즉, 테이블 A의 레코드는 존재하지 않는 테이블 B의 레코드를 가리킬 수 없습니다.
참조 무결성은 항상 두 개의 테이블과 관련된 제약 조건이며, 외래 키를 통해 적용됩니다.
Referential integrity violations
참조 무결성은 두 가지 방식으로 위반 될 수 있습니다.
테이블 A가 테이블 B를 참조한다고 가정할 때,
- 테이블 A에서 이미 참조된 테이블 B의 레코드가 삭제되면 위반이 발생합니다.
- 테이블 A에 테이블 B에 없는 것을 참조하는 레코드를 삽입하려고 하면 위반이 발생합니다.
- 외래 키의 주된 이유 ( 외래 키가 오류를 발생시키고 실수로 이러한 작업을 수행하지 못하게 합니다. )
Dealing with violations
CREATE TABLE a (
id integer PRIMARY KEY,
column_a varchar(64),
...
b_id integer REFERENCES b (id) ON DELETE NO ACTION
);열에 외래 키를 지정하면 실제로 데이터베이스 시스템이 삭제됬을 때, ON DELETE NO ACTION 키워드는 자동으로 외래 키 정의에 추가됩니다.
즉, 테이블 B의 레코드를 삭제하려고 하면, 테이블 A에서 참조하는 경우 오류가 발생합니다.
CREATE TABLE a (
id integer PRIMARY KEY,
column_a varchar(64),
...
b_id integer REFERENCES b (id) ON DELETE CASCADE
);CASCADE옵션을 사용하면, 테이블 B의 레코드를 선택한 다음 테이블 A의 모든 참조 레코드를 자동으로 삭제합니다. (계단식 삭제)
Dealing with violations
- NO ACTION : 그냥 냅두기(에러발생)
- CASCADE : 참조 삭제 ( 계단식 삭제 )
- RESTRICT : 에러발생
- SET NULL : 레코드의 외래 키 값을 NULL로 설정
- SET DEFAULT : 열에 대한 기본값을 지정한 경우 작동하며, 디폴트값으로 변경