본 내용은, 한이음 ICT 공모전에서 진행한 프로젝트의 일부를 정리한 내용입니다.
시작한 이유
쇼핑몰 리뷰데이터 분석 프로젝트를 진행하다가, 다른 감성분석 모델과는 차이점을 주고 싶었습니다.
감성분석 모델에서, 어떤 부분이 중요한 내용인지 하이라이팅을 하고 싶었습니다. 이러한 기능을 구현한 곳이 있나 다른 쇼핑몰 사이트를 찾아보니, 네이버 쇼핑에서 주요 문장이라고 판단되는 곳을 하이라이팅 하는 기능이 있었습니다.
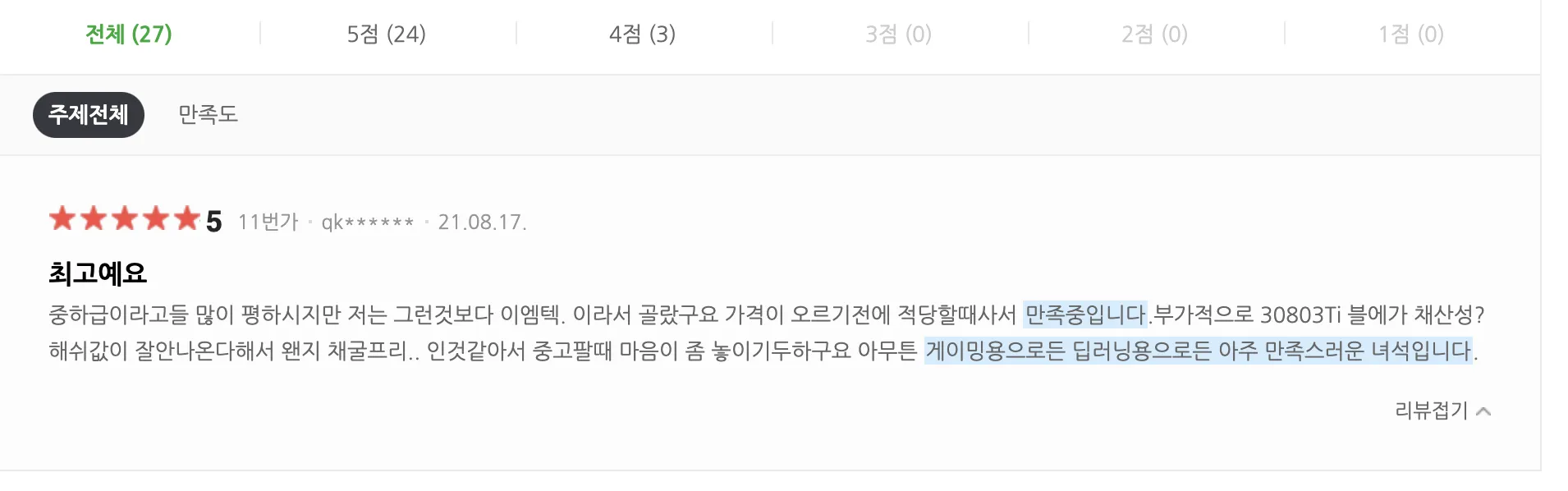
< 네이버 쇼핑리뷰 - 하이라이팅 기능 >
Keybert등을 이용해서, 위와같은 기능을 구현해볼까? 라는 생각도 해봤지만, 팀원들과 상의 끝에 우리만의 독자적인 방법을 도전해보자고 결심했습니다. 그 결과 XAI기능을 구현하면, 알아서 딥러닝이 하이라이팅을 할 수 있지 않을까? 라는 생각에 XAI 기능을 구현하기로 했습니다.
XAI
XAI 라는 것 자체가, 쉬운 도전은 아니였습니다. 거의 몇일을 XAI 와 NLP만 도전했던 것 같습니다. Computer Vision 분야에서는 XAI를 구현하는 다양한 라이브러리 및 방법들이 소개되어 있었지만, NLP 관련 XAI는 찾아보기 힘들었습니다.
계속 헤매이기만 하다가, 스트레스만 받지 말고, 차라리 ""각 Input 값에 Output 값에 영향을 끼치는 것을 수식으로 직접 계산하자” 결심하게 되었습니다.
이후이 찾아보니 이 방법이 LRP(Layer-Wise Relevance Propagation: An Overview) 라는 논문으로 소개되어 있었습니다. 이 논문을 더 빨리 찾았다면, 구현하는데 많은 도움이 되었을 텐데 라는 생각으로 논문과 친해지자는 계기가 되기도 했습니다.
데이터
앞서 말했듯이, 쇼핑몰 리뷰데이터 분석 프로젝트이며, 감성분석 모델을 구현해야 했습니다. 데이터를 찾아봤더니, 네이버 쇼핑리뷰데이터 20만개 (긍정 10만개<평점 4,5점>, 부정 10만개<평점 1,2점>) 가 있었습니다. 이를 이용해서 처음에 진행하다가, 이후 성능을 더 올리고싶어서, 추가로 크롤링을 이용해서 데이터를 수집했습니다. 이렇게 사용한 데이터는 총 54만개 (긍정 27만개, 부정 27만개) 이었습니다.
형태소 분석기
형태소 분석기로는, Mecab 형태소 분석기를 사용했습니다. Okt, KKma등 여러가지를 사용했었지만, Mecab의 연산 속도에 매력을 느꼈습니다. 또한, 쇼핑 리뷰데이터 특성상 신조어들이 등장하기에 트위터 기반으로 학습된 Mecab이 적합하다고 판단했습니다.
문장 분리
아마, 한국어 문장분리기로 가장 유명한 것이 KSS라고 생각합니다. 본 프로젝트에서도 초기에 KSS를 사용했었습니다. 하지만, 이는 연산량이 너무 많아서, 서비스를 만들기 위해서 너무 많은 시간을 소요한다는 것을 느끼게 되었습니다.
이를 극복하기 위해서, 자체적으로 문장 분리 알고리즘을 만들자 생각하게 되었습니다.
문장 분리 하기위해서, 문장이 끝나는 특징을 찾고자 했습니다.
가장 기본적인 문장의 끝맺음은 “요”, “다”, “죠” 등이 였습니다. 또한, “했음”, “삼” 등과 같은 예외적인 상황이 존재했는데, 이는 Mecab 형태소 분석기를 통해 ETN(명사형 전성 어미) 품사를 사용한다는 것을 알게되었고, 이를 이용해 문장을 분리하였습니다.
물론 정확하게 문장 분리를 하면 좋지만, 본 프로젝트에서는 크게 영향을 끼치는 사안이 아니기에, 연산 속도를 우선시 하여 진행하였습니다.
불용어 제거
Mecab 형태소 분석기를 통해 조사, 어말, 접두사, 접미사, 특수기호, Unknown 등을 제거했습니다.
워드 임베딩
사실 가장 많은 시간을 소요한 것은 워드 임베딩이였습니다. 이후 모델부분에서 소개하겠지만, 모델적인 접근보다는, 데이터적 접근을 시도하였습니다. 처음에는 Word2Vec과 LSTM을 이용해 구현하고자 했지만, XAI 성능적인 면에서 좋지 않은 성능을 보였습니다. 이에 따라 워드 임베딩 또한 자체적으로 개발하고자 했습니다.
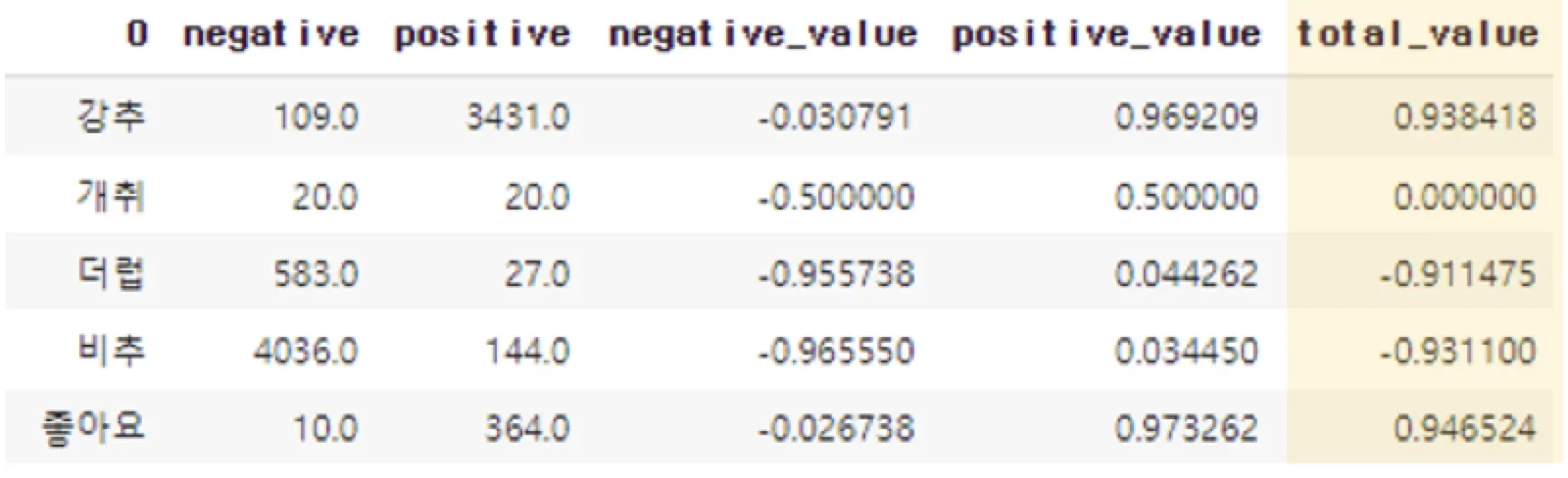
“어차피, 문맥을 이해하는 것이 아니라, 긍정 부정을 분류하는 모델이니까 이를 이용해서 임베딩하면 되지 않을까?” 라는 생각으로 통계적으로 접근하고자 했습니다.
긍정과 부정의 비율을 동일하게 맞췄으므로, 해당 형태소가 긍정에서 나온 비율, 부정에서 나온 비율을 계산하자고 생각했습니다.
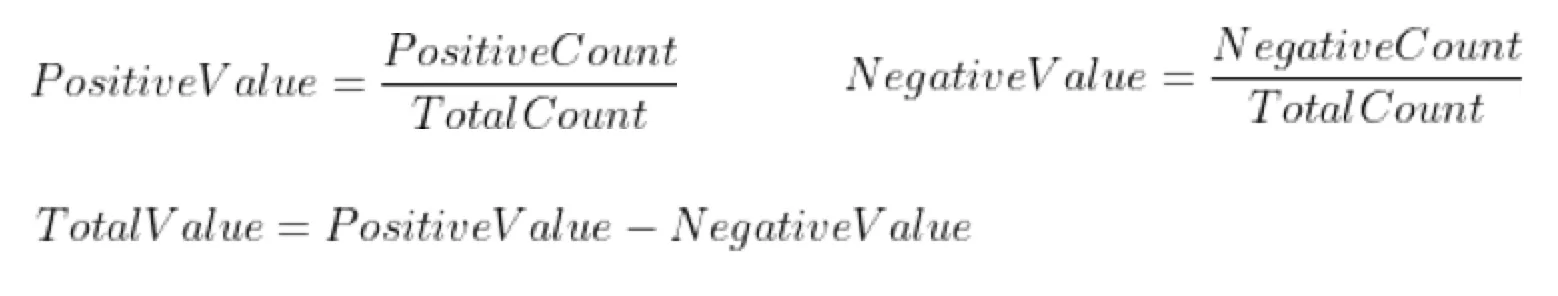
공식은 간단합니다.
긍정에서 나온 비율 / 전체에서 나온 비율 - 부정에서 나온 비율 / 전체에서 나온 비율
위의 값을 통해 값을 임베딩했습니다. 이렇게 하면, -1 ~ 1의 범위를 가지게 되며, 부정일경우 -1에 가깝고, 긍정의 경우 1에 가까운 값을 얻게 됩니다.
모델
모델로는 DNN을 이용한 2중 구조를 사용했습니다. 이번 계기로 간단한 모델도 엄청난 모습을 보여준다는 느끼게 되었습니다.
처음에는 트랜스포머 XAI를 구현하고자 했지만, 능력 부족으로 트랜스포머의 연산을 직접 수식으로 구현하기 힘들었습니다.
이후 LSTM을 도전하였지만, LSTM 특성상 값이 누적되어 이후에 전달되었으며, XAI 구현 시, 뒤에 있는 단어들이 영향을 끼치는 단어로 표기되는 것을 발견했습니다. 이는 본 프로젝트와 맞지 않는다고 판단하게 되었습니다.
이렇게 DNN 모델을 사용하게 되었습니다. NLP에 무슨 DNN 모델이냐? 생각하는 분들도 있겠지만(저도 그랬습니다…), 한국어는 생각보다 문맥이 필요가 없다는 걸 알게되었습니다. 성능 부분에서, LSTM의 경우 85%의 정확도를 보였지만, DNN 에서도 83%의 정확도를 보였습니다.
2%의 성능차이가 크다고 느끼지만, 이후 XAI 구현을 통해 얻는 이점이 더 크다고 느끼고 과감하게 DNN 모델을 사용하게 되었습니다.
XAI 구현하기
LRP를 통해 XAI를 구현하는 방법은 생각보다 간단합니다. 학습을 통해서 얻은 가중치와 편향값을 이용해서 각각의 Input layer 에서 Output layer에 영향을 끼치는 값을 계산하면 됩니다.
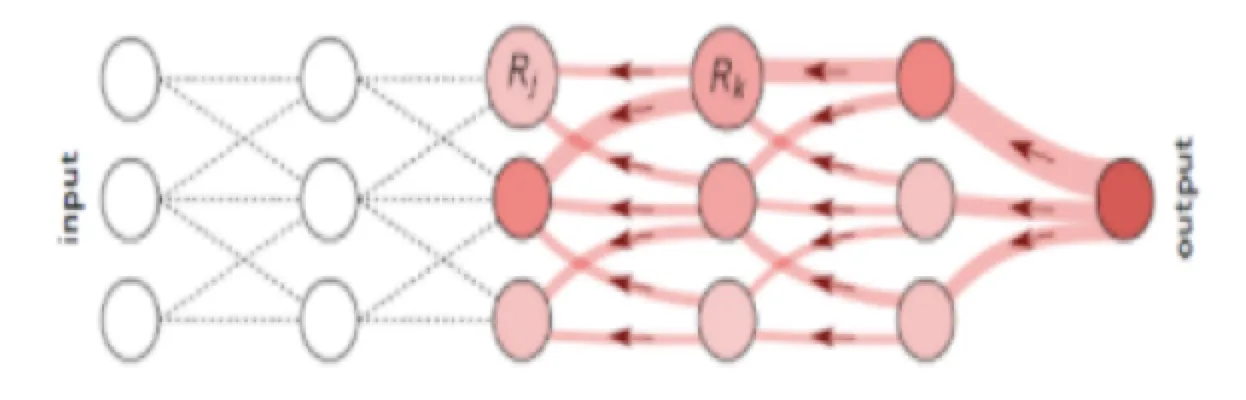
< LRP논문 이미지 >
consider_relu = [0 if h < 0 else 1 for h in np.dot(value, weights[0]) + weights[1]]
arr = [*map(np.sum, [[h * weights[2][index] + weights[3] / (20 * 10) for index, h in enumerate([0 if consider_relu[index] == 0 else value[i] * weights[0][i][index] + weights[1][index] / 20 for index in range(10)])] for i in range(20)])]위는 구현코드의 일부입니다. 전체 코드가 궁금하신 분은 제 깃헙 DNN_func 함수를 참고해주세요
이렇게 하면, 각 단어(이후 형태소 분석기를 역으로 다시 계산해서 단어로 합침)가 끼치는 영향값을 구할 수 있게됩니다.
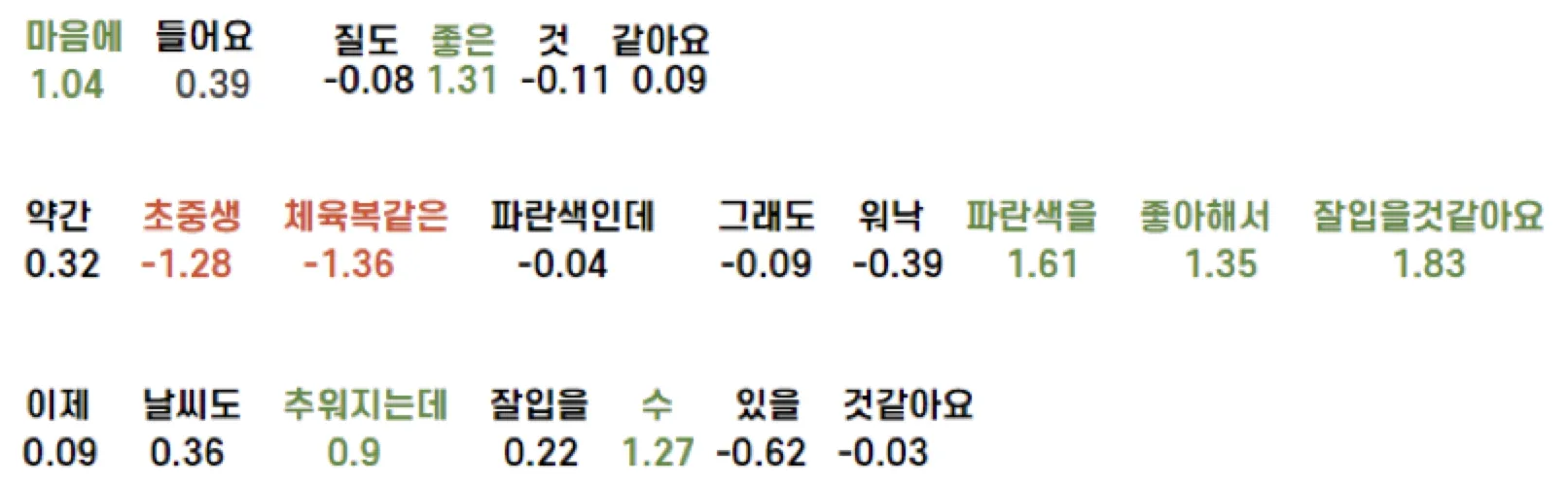
위의 예시를 보시면 생각보다는 잘 된다고 느끼게 되지만, 아쉬움이 많이 남았습니다. 소비자 입장에서 볼 때, 각 단어가 따로따로 논다고 느낄 것 같았습니다. 이를 보완하기 위해 새로운 필터링 방법을 적용했습니다.
(설정한 값(긍정값)보다 클 경우 초록색, 설정한 값(부정값)보다 작을 경우 빨간색으로 표기)
필터링 알고리즘
방법은 간단합니다. CNN 필터를 보고 이를 응용하면 되겠다고 느꼈습니다.
먼저 사이즈를 3으로 설정하고, max값을 추출하는 필터하나와 min값을 추출하는 필터하나를 통해 연산을 진행했습니다.(긍정의 수치와 부정의 수치를 비교하기 위해서 두개의 필터를 사용)
이후 두 필터를 통해 출력되는 값 중 절댓값이 큰 값과, 해당 값의 평균을 구해줬습니다.
if max(x[i-1], x[i], x[i+1]) > abs(min(x[i-1], x[i], x[i+1])):
x[i] = (max(x[i-1], x[i], x[i+1]) + x[i])/2
else:
x[i] = (min(x[i-1], x[i], x[i+1]) + x[i])/2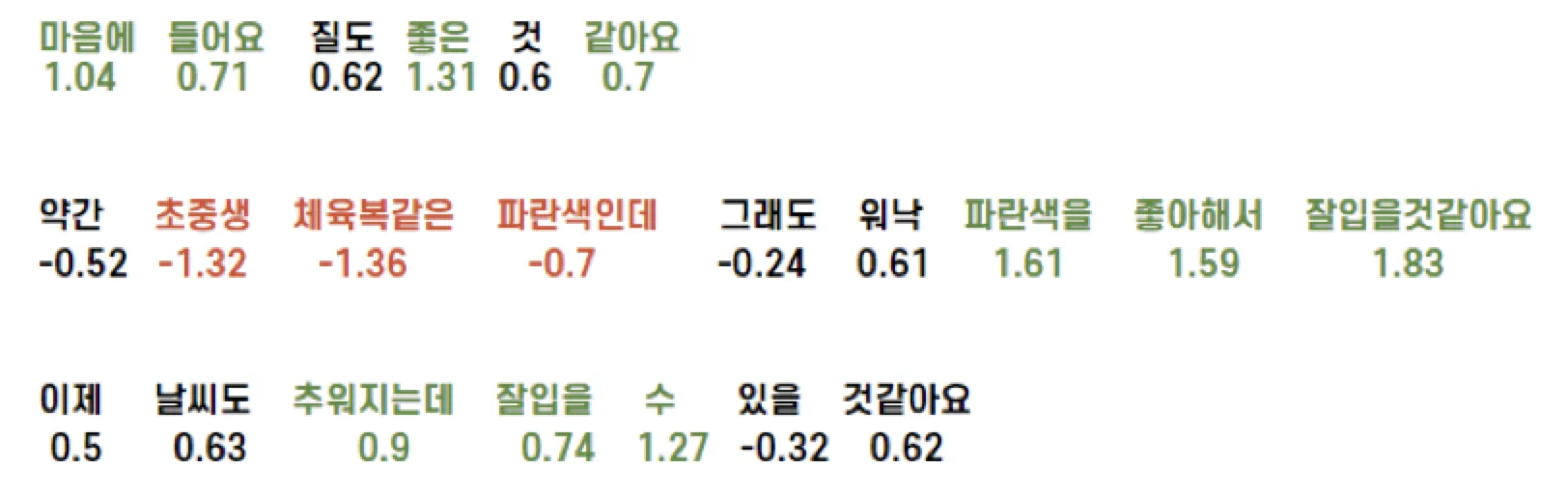
이후 새로운 계산을 적용했으므로, 이에 맞는 감성분석 모델이 필요했습니다. 이는 통계적으로 접근해서 가장 accuracy가 높은 지점을 찾아 해당 값보다 클경우 긍정, 해당 값보다 작을경우 부정으로 설정하였습니다. ( 본 프로젝트에서는, 모든 Input layer가 끼치는 영향값의 합을, -2.16을 기준으로 설정하였습니다. )
이렇게 설정하니, 기본 DNN보다 accuracy가 상승되는 것도 발견할 수 있었습니다. 이렇게 84.3% Accuracy를 보이는 xai 모델을 구현할 수 있었습니다.
본 모델이 포함된 서비스에 시연 영상 이 궁금하시면 해당 영상을 참고해주시기 바랍니다. [공모전 중간발표 제출 영상이라, 최종과 다소 다릅니다.]