As 2025 kicks off, the word “Agent” seems to pop up in the news feed almost daily. Options have exploded—from no-code workflow tools like n8n and Make, to Google’s ADK, LangChain Agents, and today’s topic, the OpenAI Agent SDK. Among these, OpenAI has released Agent Builder and integrated it with the Agent SDK, and the SDK looks poised to draw even more attention. You can take flows built in Builder straight into code for version control and deployment.
In Agent Builder, click the Code button and it instantly renders Agent SDK code.
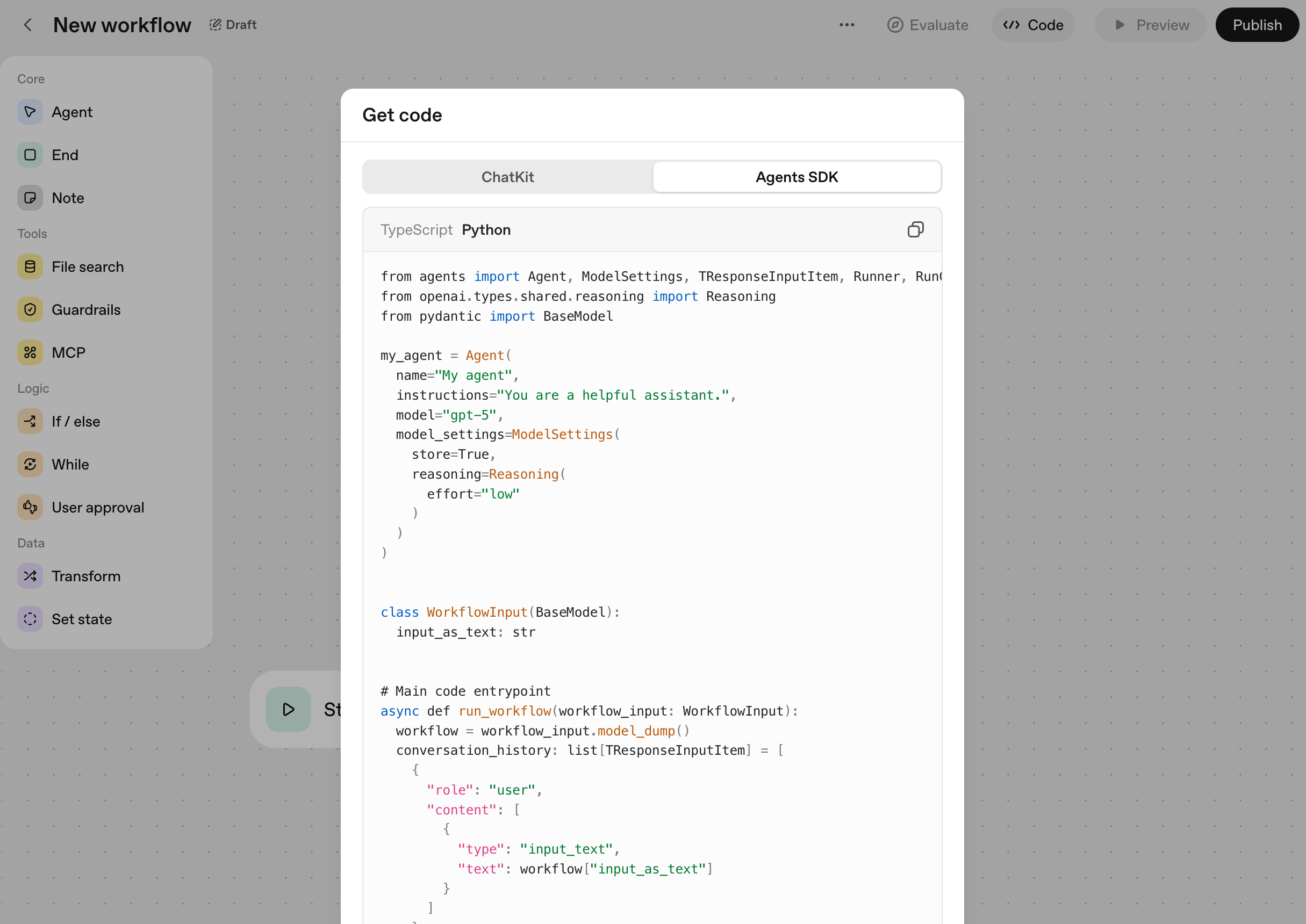
Of course, there are many tools that take different approaches, like Google ADK or Microsoft Autogen. The best choice ultimately depends on your team’s requirements and existing infrastructure. In this post, I’ll summarize what the OpenAI Agent SDK aims for and which features stand out.
First, here are the advantages that immediately stood out:
- Minimal abstraction means a shallow learning curve; if you’re familiar with the OpenAI API, you’ll pick it up quickly.
- It cleanly exposes only the essential building blocks: multi-agent, handoffs, guardrails, sessions.
- Tracing is enabled by default, so it’s easy to track execution history.
- You can jump between Agent Builder and code to run fast experiment-to-deploy cycles.
Exploring the Agent SDK
The Agent SDK evolved from the earlier beta “Swarm” and is now part of the official product line. The two principles in the official docs are particularly compelling: https://openai.github.io/openai-agents-python
- Provide enough capability to be worth using, while keeping core components minimal so it’s quick to learn.
- Work great out of the box, but stay open to customization.
In short, it’s aiming to be “lightweight yet complete.” In practice, the SDK’s scope is crisply defined around agents, handoffs, guardrails, sessions, and tracing. That makes it easy to stand up the skeleton of an agent system without heavy configuration.
The simplicity becomes clearer in the most basic example. Declaring an agent can be as simple as the code below—arguably more declarative than dealing with the GPT API directly.
from agents import Agent, Runner
agent = Agent(name="Assistant", instructions="You are a helpful assistant")
result = Runner.run_sync(agent, "Write a haiku about recursion in programming.")
print(result.final_output)
Quick start
Here’s the flow I use when first experimenting with the Agent SDK.
Installation is just the openai-agents library.
pip install openai-agents
Handoffs
The easiest way to wire up multiple agents is with handoffs. Declare each agent and pass them in the handoffs array; a routing agent will branch naturally. It’s similar to the orchestration/router concept in other tools, but the SDK intentionally simplifies configuration.
spanish_agent = Agent(
name="Spanish agent",
instructions="You only speak Spanish.",
)
english_agent = Agent(
name="English agent",
instructions="You only speak English",
)
triage_agent = Agent(
name="Triage agent",
instructions="Handoff to the appropriate agent based on the language of the request.",
handoffs=[spanish_agent, english_agent],
)
async def main():
result = await Runner.run(triage_agent, input="Hola, ¿cómo estás?")
print(result.final_output)
In this example, the triage_agent hands off to the Spanish or English agent based on input language. Using the async Runner.run instead of Runner.run_sync scales naturally when chaining steps that await external APIs or tool calls. In production, rather than building very deep handoff chains, it’s more maintainable to branch only on clear criteria like language, domain, or permissions.
As with other tools, you can also use multi-agents as tools if that fits your design.
Tools
The tool system is simple enough to define with a function or two. The basic shape looks like this:
from agents import Agent, Runner, function_tool
@function_tool
def get_weather(city: str) -> str:
return f"The weather in {city} is sunny."
agent = Agent(
name="Hello world",
instructions="You are a helpful agent.",
tools=[get_weather],
)
Wrap a function with the @function_tool decorator and it auto-generates a JSON schema you can pass directly via the tools parameter. As with the GPT API, you can fine-tune call policy—for example, tool_choice="required".
Beyond function-style tools provided by the SDK, you can attach external tool protocols like MCP.
async def main():
async with MCPServerStdio(
params={
"command": "uv",
"args": ["run", "-m", "openai_agent_sdk.mcp_server"],
},
) as server:
agent = Agent(
name="test",
instructions="test",
model=settings.OPENAI_MODEL,
mcp_servers=[server],
)
result = await Runner.run(agent, "삼성전자 주가 얼마야?")
print(result)
This example attaches an MCP server over stdio and exposes its resources as tools. In testing, everything from resource discovery (list, get) to execution worked smoothly, suggesting strong compatibility with the MCP ecosystem.
Tracing
By default, the Agent SDK sends messages, tool calls, and handoff history to OpenAI Dashboard — Logs: https://platform.openai.com/logs This is powerful because you can visualize execution flow immediately without wiring up a separate observability stack.
Since all traffic goes to OpenAI, it’s wise to set policy for sensitive data up front. If you want to disable logs, set the environment variable before importing the library:
os.environ["OPENAI_AGENTS_DISABLE_TRACING"] = "1"
Here’s what the tracing looks like:
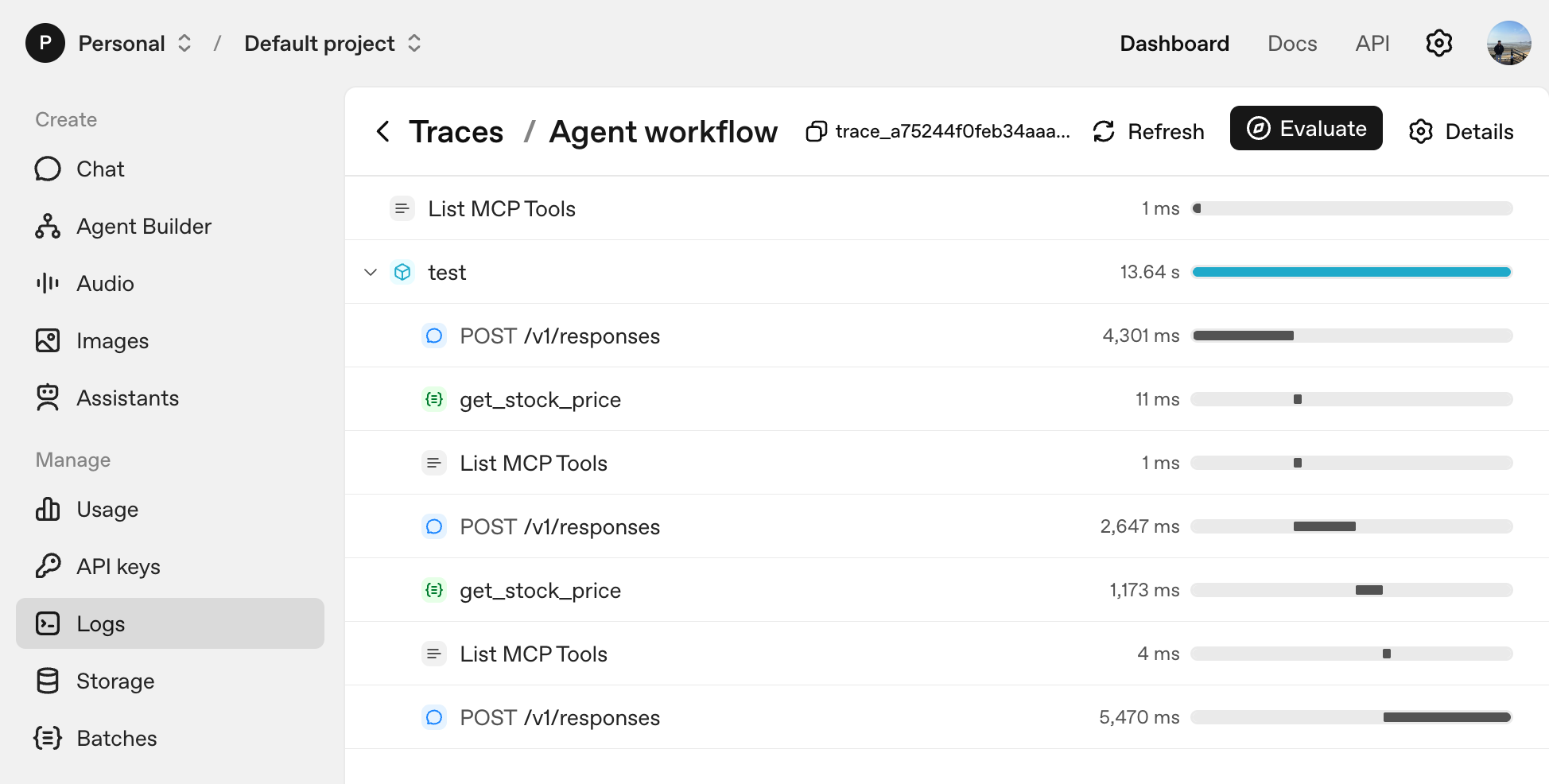
You can keep tracing even when you’re not using an OpenAI model. Attach other models via an adapter like LiteLLM, and pass a separate OpenAI API key to set_tracing_export_api_key. That lets you collect logs without incurring model costs.
import os
from agents import set_tracing_export_api_key, Agent, Runner
from agents.extensions.models.litellm_model import LitellmModel
tracing_api_key = os.environ["OPENAI_API_KEY"]
set_tracing_export_api_key(tracing_api_key)
model = LitellmModel(
model="your-model-name",
api_key="your-api-key",
)
agent = Agent(
name="Assistant",
model=model,
)
Guardrails
As agents grow more complex, you need ways to codify policy enforcement. The Agent SDK clearly separates guardrails into two types:
- Input guardrails: Inspect the initial user input and stop execution if needed.
- Output guardrails: Review the final agent response for sensitive content.
The key idea is that a guardrail is just another agent or function. For input guardrails, for example, you pass the user input to a guardrail function that decides whether to trip a block.
Here’s an example:
from pydantic import BaseModel
from agents import (
Agent,
GuardrailFunctionOutput,
InputGuardrailTripwireTriggered,
RunContextWrapper,
Runner,
TResponseInputItem,
input_guardrail,
)
class MathHomeworkOutput(BaseModel):
is_math_homework: bool
reasoning: str
guardrail_agent = Agent(
name="Guardrail check",
instructions="Check if the user is asking you to do their math homework.",
output_type=MathHomeworkOutput,
)
@input_guardrail
async def math_guardrail(
ctx: RunContextWrapper[None], agent: Agent, input: str | list[TResponseInputItem]
) -> GuardrailFunctionOutput:
result = await Runner.run(guardrail_agent, input, context=ctx.context)
return GuardrailFunctionOutput(
output_info=result.final_output,
tripwire_triggered=result.final_output.is_math_homework,
)
agent = Agent(
name="Customer support agent",
instructions="You are a customer support agent. You help customers with their questions.",
input_guardrails=[math_guardrail],
)
async def main():
# This should trip the guardrail
try:
await Runner.run(agent, "Hello, can you help me solve for x: 2x + 3 = 11?")
print("Guardrail didn't trip - this is unexpected")
except InputGuardrailTripwireTriggered:
print("Math homework guardrail tripped")
In this code, the math_guardrail function calls a separate agent to judge whether the request is asking to do someone’s math homework. If true, it raises the InputGuardrailTripwireTriggered exception. Splitting guardrail logic into its own agent makes policy reusable and easy to port across projects. Output guardrails follow the same pattern with the @output_guardrail decorator.
Sessions and state management
To run agents in production, you need to persist conversation context and per-user state. The Agent SDK provides a Session abstraction that cleanly separates this concern. I won’t cover it here, but it supports memory, databases, and other storage like similar tools, so you should be able to use it without much friction.
Drawbacks
Compared to other tools, I don’t see stark pros/cons—this one sits in the middle. If I had to call one out, it’s the tight coupling to the OpenAI ecosystem. You can attach other models via LiteLLM, but tracing and access control ultimately depend on an OpenAI account, and default tracing goes only to the OpenAI Dashboard. If you already have in-house monitoring, you’ll need to build a separate pipeline.
Wrapping up
Agent SDK pursues the same simplicity as MS Autogen, while the integration with OpenAI Builder could shorten the experiment-to-deployment loop. Most of all, I like that it trims down to the essentials, significantly reducing the learning cost.
You can find more examples and patterns in the openai-agents-python repo: https://github.com/openai/openai-agents-python/tree/main/examples/agent_patterns I recommend experimenting to find an architecture that fits your team’s needs.